

Thanks to the AWS Community Builders program membership (where I have received a voucher for the AWS Certification - if you want yours, pay attention to this page, as there will be a new draft in Q1 2021) I recently passed the *AWS Certified Data Analytics - Specialty exam successfully (also called DAS-C01). Back in the days, it was called AWS Certified Big Data - Specialty and AWS did not change only the name as the scope and expected knowledge is different.
Below, I have summarized my experience and collected an extensive list of materials that I have used in the process. It took ~1 month. However, I previously had 2 years of hands-on experience with most of the topics required by the blueprint. Speaking about the prerequisites...
Blueprint and Prerequisites
Before we go to the materials, I want to start with an official blueprint:
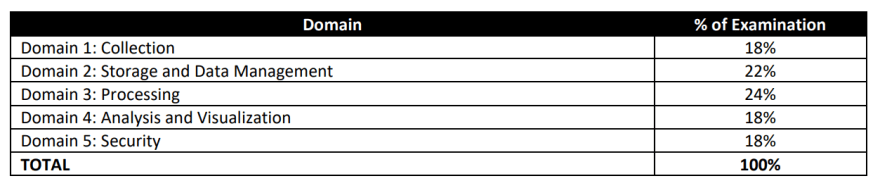
According to the table above, the content of that exam is well-balanced. However, there are some surprises that I would like to emphasize here. First things first, I was surprised that even though 24% of all points are related to Processing, it does not require expertise in Hadoop ecosystem like was the case with the former incarnation. More emphasis is put on knowing which service to choose and how to integrate them between each other. Additionally, you should know AWS Glue and its transforms (mostly because those are easy points to gain), but we will discuss it in detail later.
The most important thing coming from that table is that you should feel pretty knowledgeable about all areas before approaching the exam because it is balanced in that regard, and skimming over one part may result in failing the exam.
One other thing worth mentioning is that it is possible to pass the exam in a fully-remote environment. There are a few drawbacks, though:
- You need to have a dedicated room or space during the exam, plus you cannot leave the room. Supervisors are paying attention to what's happening on the camera, and any interruption by you or bystanders will result in a fail attempt.
- You have to perform an exam from a Windows or macOS machine, with a camera, microphone.
- You need to have a phone and a government-issued document (e.g., driving license) to verify your identity.
- Yet, during the exam duration, phones, snacks, beverages (even water) cannot be available within reach.
- Camera placement matters! Mine was on top of the 24" monitor on a stand. During the exam, I was asked twice to look into the exam content, and not on the sides (because I moved my head sideways reading from left to right on a lengthy screen 😅).
As usual, more general tips are applicable as well:
- Additional handicap of 30 minutes for non-native English speakers is still available, so make sure that you have requested that.
- Make sure you will use the flagging mechanism and reiterate the questions if you have time.
- There is no penalty for guessing.
- You can and should apply the same rules as in the other exams (look here for more details) regarding how to read a question and answers. So make sure your bullshit-o-meter is well calibrated. 😂
As we have the usual stuff covered, let's discuss my thoughts regarding the exam content and coverage.
My thoughts about the exam content
Let's start with what surprised me and wasn't available for my exam. There were no queries, no SQL, no code examples to analyze (even the smallest bit of IAM policy, nor AWS CloudFormation template).
As I told you above, there were almost no questions about Hadoop and its internals. If there were any, they were pretty basic and well-documented - mostly about EMRFS and the purpose of Apache Hive and Hive Metastore.
There was no question about Amazon Kinesis Video Streams (however, wait for it as I will explain it later), nor AWS IoT. The same goes for theory, definitions, AWS Well-Architected Framework.
What was there and actually surprised me is a significant amount of questions about AWS Lambda, including consumers for the Amazon Kinesis suite or just for processing data from Amazon S3.
Speaking about Amazon Kinesis - this exam is very Kinesis-heavy. You need to have in-depth knowledge of the limits, relevant data sources, data targets, and delivery guarantees for all Amazon Kinesis services (excluding Amazon Kinesis Video Streams mentioned above). Pay attention to which services and integrations provide near real-time processing and allow for processing data in an exactly-once manner. You need to have experience with error handling, Amazon Kinesis Producer Library (KPL), Amazon Kinesis Consumer Library (KCL), and you need to know where and how you can use the Random Cut Forest (RCF) algorithm.
If we are on the topic of Processing, pay attention to AWS Glue. Its transforms, what can be done with them, how to optimize AWS Glue ETL jobs, know the limits and use cases for AWS Glue Crawlers, AWS Glue Data Catalog and its compatibility with Hive Metastore. Make sure you know where and how you can use AWS Glue Job Bookmark. Nevertheless, it does not require a lot of knowledge about Apache Spark itself (I have just one question about its internals).
On the other hand, Amazon EMR which was a significant bit of the Big Data - Specialty exam here, was marginal for me. You need to know how to optimize costs, Apache Hive and Hive Metastore. You need to know its security, permissions, encryption, and differences between EMRFS and HDFS.
There are two big chunks left: one is definitely Amazon S3. You have to know inside-out the permission model, storage classes, and automation around it. It would be great to know by heart performance limitations and Amazon S3 Event Notifications constraints and use cases.
The last big chunk may be surprising because it was Amazon QuickSight. You need to know precisely how Enterprise and Standard licensing models differ, how to use SPICE and refresh datasets, how to optimize costs of Amazon QuickSight when to use which chart type, ML insights and Outlier or Anomaly Detection.
Surprisingly topics like Amazon Athena, Amazon MSK, Amazon Redshift or Amazon Elasticsearch Service are not extensively covered (at least during my exam). Here is the brief list of topics I had:
-
Amazon Athena:
- You need to know how to optimize the costs and performance of the queries.
- Know inside-out administration mechanism via Amazon Athena Workgroups.
-
AWS Lake Formation:
- How the permissions model work (what you can and can't do), including the cross-account access.
-
Amazon MSK:
- When to use Amazon MSK and when Amazon Kinesis.
- I have one strange question about its permission model.
-
Amazon Redshift:
- For sure, you need to know everything about sizing and resizing the cluster.
- It would be great to know when to use Amazon Redshift Spectrum.
- How to optimize the performance of queries, clean-up, and ingestion time.
-
Amazon Elasticsearch Service:
- I have very few questions about it, mostly about the permissions model or Kibana.
Finally, you should have a gist of what AWS Batch, Amazon Data Pipeline, Amazon SageMaker or AWS Data Exchange are about such knowledge can provide you straightforward points.
I have said everything that I could, so let's discuss the materials that are worth your time.
Resources
There are available online courses or sets of questions dedicated to that particular exam. Those are worth checking:
-
udemy.com/course/aws-big-data: an online course dedicated fully to preparing for the exam mentioned above, authored by Stephane Maarek and Frank Kane.
-
In the end, I have enjoyed this course.
- I have bought it (on Udemy) and done it.
- It was not so dry, irrelevant, and not practical as most online courses prepared just for the exam.
- It's definitely a comprehensive source of knowledge about the necessary topics.
- I wish those tasks would be much easier to reproduce because they were time-consuming.
- I have bought it (on Udemy) and done it.
-
In the end, I have enjoyed this course.
- szkoleniedatalake.pl: this one is a shameless plug for 🇵🇱 speaking folks, as I have created an online course about leveraging and building data lake architecture on AWS. It covers in-depth 2/3 of the content required for the exam (it misses Amazon Kinesis, Amazon EMR, and Amazon Redshift).
- whizlabs.com/aws-certified-data-analytics-specialty/practice-tests: I haven't checked them, but they look solid based on a table of contents, and I have used practice tests from WhizLabs for other exams in the past with success.
Also, Qwiklabs and Linux Academy Hands-on Labs for Amazon EMR, Amazon Athena and AWS Glue are helpful, but you can do similar stuff on your own too.
Additional resources from AWS
In this section, I would like to emphasize two additional types of resources that are definitely worth checking.
The first one was surprising for me, but I have discovered that FAQ for the following services contains interesting information that can give easy points:
- Amazon Athena
- Amazon EMR
- Amazon Redshift
- Amazon Kinesis Data Streams
- Amazon Kinesis Data Firehose
- Amazon Kinesis Data Analytics
- Amazon ElasticSearch Service
- Amazon Managed Service for Kafka (MSK)
- Amazon QuickSight
- AWS Data Exchange
- AWS Glue
- AWS Lake Formation
The second one is also surprising: I find AWS Certified Data Analytics - Specialty Exam Readiness available here enjoyable and well-prepared. It is worth doing just for the questions presented there, but I liked the course's interactivity. Topics are prepared nicely and allow you to review the content if you have missed anything.
AWS Blog Posts you have to read
Yeah, this time, it is a separate section because I found at least five blog posts that are worth reading:
-
Optimize memory management in AWS Glue.
- This one is a 💎.
- It's definitely worth reading, as it provides a lot of useful knowledge.
- This one is a 💎.
-
Process data with varying data ingestion frequencies using AWS Glue job bookmarks
- This will help you understand how AWS Glue Job Bookmarks work.
-
Amazon Redshift Engineering’s Advanced Table Design Playbook: Preamble, Prerequisites, and Prioritization
- Another set of 💎💎💎, this time about Amazon Redshift.
- All five posts in the series are worth reading. They may look dated - but don't be fooled. They are providing a lot of useful knowledge.
- Another set of 💎💎💎, this time about Amazon Redshift.
-
Top 10 performance tuning techniques for Amazon Redshift
- This piece is also worth reading!
- It's more modern than the one mentioned above and provides a lot of interesting information from a different angle.
- This piece is also worth reading!
-
Best Practices for Amazon Redshift Spectrum
- This one is definitely worth your time because knowledge about Amazon Redshift Spectrum gives you easy points.
List of AWS whitepapers worth reading
I have one remark about whitepapers for this exam: focus more on re:Invent videos (especially the deep dives into EMR, Athena, Glue, Kinesis, and S3).
Nevertheless, there are some papers worth reading. Here is the list that I have read and my recommendations on how important each one is:
-
Must Read:
-
AWS Well-Architected Framework - Analytics Lens.
- Another must-read IMHO.
- This one contains more recent information, plus it focuses on a critical perspective for any AWS related exam (AWS Well-Architected Framework).
- Another must-read IMHO.
-
Streaming Data Solutions on AWS with Amazon Kinesis
- This one is interesting as it focuses on real-world scenarios and their use cases.
- However, if you have worked with Amazon Kinesis, it's something you can skip.
- This one is interesting as it focuses on real-world scenarios and their use cases.
- Sizing Cloud Data Warehouses
-
Amazon Redshift: Cost Optimization
- This paper and the previous one are definitely worth reading to systematize knowledge about Amazon Redshift.
- Especially if you haven't worked with a lot of clusters or haven't resized any.
- This paper and the previous one are definitely worth reading to systematize knowledge about Amazon Redshift.
-
Cost Modeling Data Lakes for Beginners
- This is a must-read one!
- It contains a lot of insightful knowledge about cost and performance optimization.
- This is a must-read one!
-
AWS Well-Architected Framework - Analytics Lens.
-
Nice to Read:
-
Migrating to Apache HBase on Amazon S3 on Amazon EMR
- It's funny because this paper is worth reading not because of Apache HBase but to understand the difference between HDFS and EMRFS.
- I think the Apache HBase example explains it pretty well.
- It's funny because this paper is worth reading not because of Apache HBase but to understand the difference between HDFS and EMRFS.
-
Comparing the Use of Amazon DynamoDB and Apache HBase for NoSQL
- This one is very dense and worthwhile but very specific.
- You will not get a lot of information for the exam, but it's worth reading.
- This one is very dense and worthwhile but very specific.
-
Migrating to Apache HBase on Amazon S3 on Amazon EMR
-
For Beginners:
-
Big Data Analytics Options on AWS
- If you do not know where to start, pick out this whitepaper.
-
Use Amazon Elasticsearch Service to Log and Monitor (Almost) Everything
- It's a good overview of the Amazon Elasticsearch Service and ELK stack on AWS.
-
Lambda Architecture for Batch and Stream Processing
- Read this one only if you are new to those topics and haven't heard about Lambda Architecture.
- However, it's not necessary for the exam, though.
- Read this one only if you are new to those topics and haven't heard about Lambda Architecture.
-
Big Data Analytics Options on AWS
List of re:Invent videos worth watching
Here is my playlist that I watched and think those are valuable.
It is an awful lot of much watch time, but watching those on 1.5x speed is still pleasant (Video Speed Controller extension is your friend). And I cannot stress that enough: those are more important than whitepapers. In comparison to whitepapers, I experienced many more questions than I recalled from the re:Invent talks instead.
Are you up to your AWS Data Analytics adventure?
I think this exam is definitely worth your attention if you work daily with Data Lakes, Data Analytics, and Data Processing on AWS. If you have hands-on experience, you should prepare reasonably quickly - I did that in more or less 1 month. If so, why not try to get another one to your collection? 😉
I hope this guideline will help you to prepare and evaluate your knowledge. If you have any questions, remarks, doubts, other observations, or you want just to share the joy of the passed exam, feel free to do it in the comments below.
And of course: Good Luck with your exam! Have Fun. 💪
If you are interested in similar guides, but for AWS Certified Database - Specialty or AWS Certified Solutions Architect - Professional feel free to check out my blog with the rest of those guides here: awsmaniac.com/exams.

Top comments (1)
Some comments may only be visible to logged-in visitors. Sign in to view all comments.