
Once upon a time, people looking for information had to physically walk into a brick-and-mortar library, find the right books, and read through them intently.
Today, it seems a given that whatever data you’re looking for exists on the Internet. There are over a billion websites on the World Wide Web at any given moment, containing enough information to take up out 305 billion printed sheets of paper.
The good news is that no matter what kind of data you’re looking for, you can be sure to find it online. The bad news is that there is so much data online that personally sifting through it borders on the physically impossible.  Add in the fact that most websites have different scopes, formats, and frameworks. About 30% of websites use WordPress, for instance, and the rest use a variety of other platforms like Joomla, Drupal, Magento, etc.
Add in the fact that most websites have different scopes, formats, and frameworks. About 30% of websites use WordPress, for instance, and the rest use a variety of other platforms like Joomla, Drupal, Magento, etc.
Enter web crawling. Web crawlers are automated data-gathering tools that interact with websites on their owners’ behalf. This lets you access reams of data ready for output to a local database or spreadsheet for further analysis.
Although it may sound complicated, the truth is that building a web crawler using Selenium is a pretty straightforward process. Let’s dive in and find out exactly what you need to get started. 
There are Two Ways to Crawl Web Data
One of the first obstacles you’ll encounter when learning how to build a web crawler using Selenium is the fact that websites don’t seem to like it. Web crawlers generate a lot of traffic, and website administrators tend to feel like web crawlers abuse the server resources they make available to the public.
But major Internet companies like Google crawl data all the time. The only difference is that they ask permission and offer something in return (in Google’s case, placement on the world’s number-one search engine). What do you do if you need access to data and don’t have the convenient backing of a powerful economic incentive on your side?
You can use Selenium to collect data from websites through a browser – just like a regular user would. But since web administrators don’t like it, you’ll need the proxy to hide your identity behind so that they can’t trace the activity back to you.
Depending on your jurisdiction and the jurisdiction of the website you want to access, using a proxy could be a life-saver. In 2011, a court in British Columbia punished a company for scraping content from a real estate website, but more recent cases allow crawling of publicly accessible content.
Journalists, data analysts, and programmers generally don’t have the resources Google brings to the table when it asks for web crawler access.
Selenium – How it Works and Why You Should Use It
There are lots of tools and platforms you can use to scrape web data, but most have limitations. For instance, if you use the Python module Scrapy, you can only access websites that don’t feature JavaScript-heavy user interfaces.
Selenium is a simple tool for automating browsers. With Selenium, you can automate a web browser like Google Chrome or Safari so that any website is crawl-compatible.
The first step is downloading and setting up Selenium. You will need to download a version of Selenium specifically tailored to your browser. For Google Chrome, for instance, this is called ChromeDriver.
When you extract the file (ChromeDriver.exe, for instance), make sure to remember where you put it, because you’ll need it later.
In order to use Selenium to build a web crawler, you’ll need some extra Java modules. This requires a little bit of coding, but it’s not that complicated. First, install Maven, which is what you’re going to use to build the Java program.  Once Maven is ready, you must add this dependency to POM.xml: Now just run the build process and you’re ready to take your first steps with Selenium.
Once Maven is ready, you must add this dependency to POM.xml: Now just run the build process and you’re ready to take your first steps with Selenium.
Basic Introduction to Using Selenium
 Let’s start with something simple. First, create an instance of ChromeDriver:
Let’s start with something simple. First, create an instance of ChromeDriver:
WebDriver driver = new ChromeDriver();
Now you’ll have a Google Chrome window open. To navigate to a web page, use this command (using example.com as an example):
driver.get("http://www.example.com");
To locate HTML elements on a page, use WebDriver.findElement(). To get the page title, your command should look like this:
System.out.println("Title: " + driver.getTitle());
This is how Selenium works. It assigns a coding matrix to the browser so that you can automate the things you would normally do by hand. It’s a simple, and powerful way to complete a broad variety of time-intensive tasks. To close out the session, use this command: driver.quit();
And that’s it. You’ve successfully controlled a browser session using Java in Selenium. To learn more about using Selenium as a web crawler, use this GitHub tutorial. Once you know the commands and understand the methodology, the entire Internet is open to you.
Proxies – What to Look for When Building a Web Crawler Using Selenium
When using Selenium to scrape websites, the main thing you want to protect yourself against is blacklisting. Since web administrators will generally automatically treat Selenium-powered web crawlers as threats, you need to protect your web crawler.
Nobody can guarantee that your web scraper will never get blacklisted, but choosing the right proxy can make a big difference and improve the life expectancy of your crawler.  The majority of websites will block web crawlers based on the IP address of the originating server or the user’s hosting provider. Clever web administrators will use intelligent tools to determine the pattern of a certain pool of IP addresses and then block the whole bunch.
The majority of websites will block web crawlers based on the IP address of the originating server or the user’s hosting provider. Clever web administrators will use intelligent tools to determine the pattern of a certain pool of IP addresses and then block the whole bunch.
What you need is a proxy that can shift between multiple IP addresses. Don’t settle for a simple solution, either:
- Some experts recommend using between 50 and 100 distinct IP addresses to be sure you have a large enough pool.
o Make sure you don’t get consecutive IP addresses (1.2.3.4 to 1.2.3.5 to 1.2.3.6, for example).
You need randomized IP addresses with no logical correlation between them.
The important thing is that Selenium, by its nature, is powerfully customizable. Your imagination and coding skills are the only limit to your ability to build a web crawler using Selenium.
For instance, if you are using the Requests library (more information here ) then you can write code to use proxy IPs with Selenium like so:
r = requests.get('example.com',headers=headers,proxies={'https': proxy_url}) proxy = get_random_proxy().replace('\n', '') service_args = [ '--proxy={0}'.format(proxy), '--proxy-type=http', '--proxy-auth=user:password' ] print('Processing..' + url) driver = webdriver.PhantomJS(service_args=service_args)
Where example.com is the website you would like to access and get_random_proxy is the command to obtain a random proxy from within your pool. 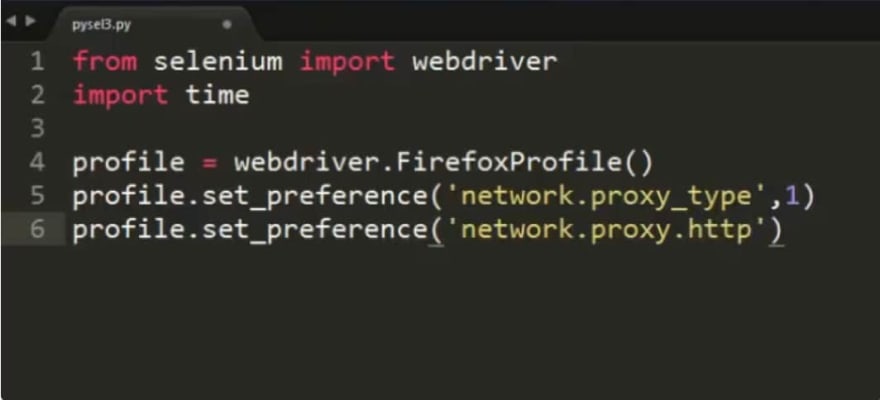
But this is just the beginning of integrating proxies with your Selenium web crawler. There’s much more you can do:
- You can program Selenium to implement a system that sets the frequency of an IP address visiting a target website per day or per hour and then disables that IP address for 24 hours once it reaches its limit.
- You can set Selenium to record the IP addresses that get blacklisted. This lets you streamline the process of requesting new IP addresses because you only need to replace the ones that are blocked.
- You can increase Selenium’s page-load waiting time to adjust for timeouts. If you are overtaxing the target server and using proxies, you may need to adjust page-load wait times to make Selenium more patient. Investing in a higher quality proxy can ensure faster response times.
Now there are lots of rotating proxy services in the market, The rotating proxy work as "backconnect" that offer proxy API to rotate the IP addresses automatically, if you use those type of services, that will save lots of time on proxies setting up.
With a powerful tool like Selenium supported by top-shelf proxies that you can rely on, you will be able to seamlessly gather data from anywhere on the Internet without exposing any vulnerabilities. Enjoy and happy crawling!

Top comments (0)