
This is a repost of the blog here
As early as 2016, we set out a bold, new vision reimagining batch data processing through a new “incremental” data processing stack - alongside the existing batch and streaming stacks.
While a stream processing pipeline does row-oriented processing, delivering a few seconds of processing latency, an incremental pipeline would apply the same principles to columnar data in the data lake,
delivering orders of magnitude improvements in processing efficiency within few minutes, on extremely scalable batch storage/compute infrastructure. This new stack would be able to effortlessly support regular batch processing for bulk reprocessing/backfilling as well.
Hudi was built as the manifestation of this vision, rooted in real, hard problems faced at Uber and later took a life of its own in the open source community. Together, we have been able to
usher in fully incremental data ingestion and moderately complex ETLs on data lakes already.
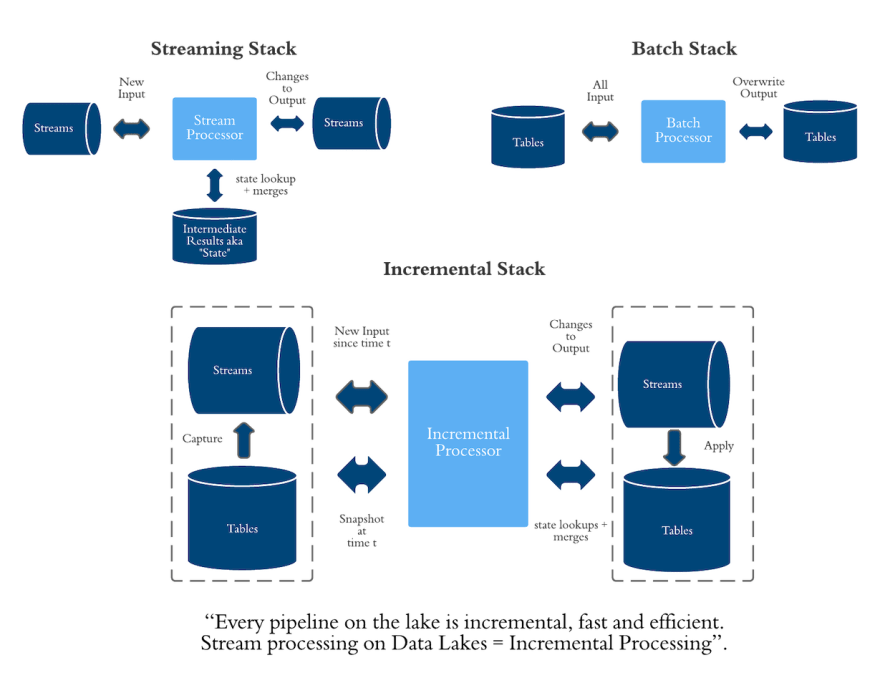
Today, this grand vision of being able to express almost any batch pipeline incrementally is more attainable than it ever was. Stream processing is maturing rapidly and gaining tremendous momentum,
with generalization of stream processing APIs to work over a batch execution model. Hudi completes the missing pieces of the puzzle by providing streaming optimized lake storage,
much like how Kafka/Pulsar enable efficient storage for event streaming. Many organizations have already reaped real benefits of adopting a streaming model for their data lakes, in terms of fresh data, simplified architecture and great cost reductions.
But first, we needed to tackle the basics - transactions and mutability - on the data lake. In many ways, Apache Hudi pioneered the transactional data lake movement as we know it today. Specifically, during a time when more special-purpose systems were being born, Hudi introduced a server-less, transaction layer, which worked over the general-purpose Hadoop FileSystem abstraction on Cloud Stores/HDFS. This model helped Hudi to scale writers/readers to 1000s of cores on day one, compared to warehouses which offer a richer set of transactional guarantees but are often bottlenecked by the 10s of servers that need to handle them. We also experience a lot of joy to see similar systems (Delta Lake for e.g) later adopt the same server-less transaction layer model that we originally shared way back in early '17. We consciously introduced two table types Copy On Write (with simpler operability) and Merge On Read (for greater flexibility) and now these terms are used in projects outside Hudi, to refer to similar ideas being borrowed from Hudi. Through open sourcing and graduating from the Apache Incubator, we have made some great progress elevating these ideas across the industry, as well as bringing them to life with a cohesive software stack. Given the exciting developments in the past year or so that have propelled data lakes further mainstream, we thought some perspective can help users see Hudi with the right lens, appreciate what it stands for, and be a part of where it’s headed. At this time, we also wanted to shine some light on all the great work done by 180+ contributors on the project, working with more than 2000 unique users over slack/github/jira, contributing all the different capabilities Hudi has gained over the past years, from its humble beginnings.
This is going to be a rather long post, but we will do our best to make it worth your time. Let’s roll.
Data Lake Platform
We have noticed that, Hudi is sometimes positioned as a “table format” or “transactional layer”. While this is not incorrect, this does not do full justice to all that Hudi has to offer.
Is Hudi a “format”?
Hudi was not designed as a general purpose table format, tracking files/folders for batch processing. Rather, the functionality provided by a table format is merely one layer in the Hudi software stack. Hudi was designed to play well with the Hive format (if you will), given how popular and widespread it is. Over time, to solve scaling challenges or bring in additional functionality, we have invested in our own native table format with an eye for incremental processing vision. for e.g, we need to support shorter transactions that commit every few seconds. We believe these requirements would fully subsume challenges solved by general purpose table formats over time. But, we are also open to plugging in or syncing to other open table formats, so their users can also benefit from the rest of the Hudi stack. Unlike the file formats, a table format is merely a representation of table metadata and it’s actually quite possible to translate from Hudi to other formats/vice versa if users are willing to accept the trade-offs.
Is Hudi a transactional layer?
Of course, Hudi had to provide transactions for implementing deletes/updates, but Hudi’s transactional layer is designed around an event log that is also well-integrated with an entire set of built-in table/data services. For e.g compaction is aware of clustering actions already scheduled and optimizes by skipping over the files being clustered - while the user is blissfully unaware of all this. Hudi also provides out-of-box tools for ingesting, ETLing data, and much more. We have always been thinking of Hudi as solving a database problem around stream processing - areas that are actually very related to each other. In fact, Stream processing is enabled by logs (capture/emit event streams, rewind/reprocess) and databases (state stores, updatable sinks). With Hudi, the idea was that if we build a database supporting efficient updates and extracting data streams while remaining optimized for large batch queries, incremental pipelines can be built using Hudi tables as state store & update-able sinks.
Thus, the best way to describe Apache Hudi is as a Streaming Data Lake Platform built around a database kernel. The words carry significant meaning.
Streaming: At its core, by optimizing for fast upserts & change streams, Hudi provides the primitives to data lake workloads that are comparable to what Apache Kafka does for event-streaming (namely, incremental produce/consume of events and a state-store for interactive querying).
Data Lake: Nonetheless, Hudi provides an optimized, self-managing data plane for large scale data processing on the lake (adhoc queries, ML pipelines, batch pipelines), powering arguably the largest transactional lake in the world. While Hudi can be used to build a lakehouse, given its transactional capabilities, Hudi goes beyond and unlocks an end-to-end streaming architecture. In contrast, the word “streaming” appears just 3 times in the lakehouse paper, and one of them is talking about Hudi.
Platform: Oftentimes in open source, there is great tech, but there is just too many of them - all differing ever so slightly in their opinionated ways, ultimately making the integration task onerous on the end user. Lake users deserve the same great usability that cloud warehouses provide, with the additional freedom and transparency of a true open source community. Hudi’s data and table services, tightly integrated with the Hudi “kernel”, gives us the ability to deliver cross layer optimizations with reliability and ease of use.
Hudi Stack
The following stack captures layers of software components that make up Hudi, with each layer depending on and drawing strength from the layer below. Typically, data lake users write data out once using an open file format like Apache Parquet/ORC stored on top of extremely scalable cloud storage or distributed file systems. Hudi provides a self-managing data plane to ingest, transform and manage this data, in a way that unlocks incremental data processing on them.
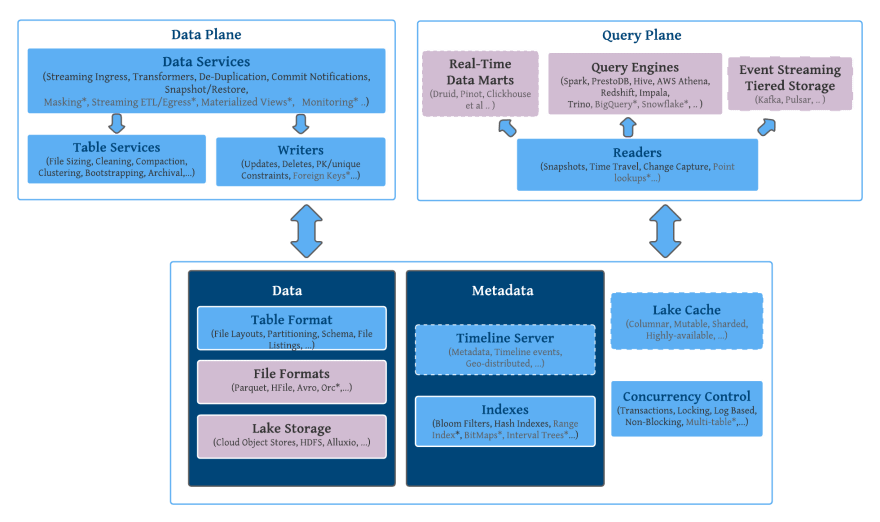
Furthermore, Hudi either already provides or plans to add components that make this data universally accessible to all the different query engines out there. The features annotated with * represent work in progress and dotted boxes represent planned future work, to complete our vision for the project.
While we have strawman designs outlined for the newer components in the blog, we welcome with open arms fresh perspectives from the community.
Rest of the blog will delve into each layer in our stack - explaining what it does, how it's designed for incremental processing and how it will evolve in the future.
Lake Storage
Hudi interacts with lake storage using the Hadoop FileSystem API, which makes it compatible with all of its implementations ranging from HDFS to Cloud Stores to even in-memory filesystems like Alluxio/Ignite. Hudi internally implements its own wrapper filesystem on top to provide additional storage optimizations (e.g: file sizing), performance optimizations (e.g: buffering), and metrics. Uniquely, Hudi takes full advantage of append support, for storage schemes that support it, like HDFS. This helps Hudi deliver streaming writes without causing an explosion in file counts/table metadata. Unfortunately, most cloud/object storages do not offer append capability today (except maybe Azure). In the future, we plan to leverage the lower-level APIs of major cloud object stores, to provide similar controls over file counts at streaming ingest latencies.
File Format
Hudi is designed around the notion of base file and delta log files that store updates/deltas to a given base file (called a file slice). Their formats are pluggable, with Parquet (columnar access) and HFile (indexed access) being the supported base file formats today. The delta logs encode data in Avro (row oriented) format for speedier logging (just like Kafka topics for e.g). Going forward, we plan to inline any base file format into log blocks in the coming releases, providing columnar access to delta logs depending on block sizes. Future plans also include Orc base/log file formats, unstructured data formats (free form json, images), and even tiered storage layers in event-streaming systems/OLAP engines/warehouses, work with their native file formats.
Zooming one level up, Hudi's unique file layout scheme encodes all changes to a given base file, as a sequence of blocks (data blocks, delete blocks, rollback blocks) that are merged in order to derive newer base files. In essence, this makes up a self contained redo log that the lets us implement interesting features on top. For e.g, most of today's data privacy enforcement happens by masking data read off the lake storage on-the-fly, invoking hashing/encryption algorithms over and over on the same set of records and incurring significant compute overhead/cost. Users would be able to keep multiple pre-masked/encrypted copies of the same key in the logs and hand out the correct one based on a policy, avoiding all the overhead.
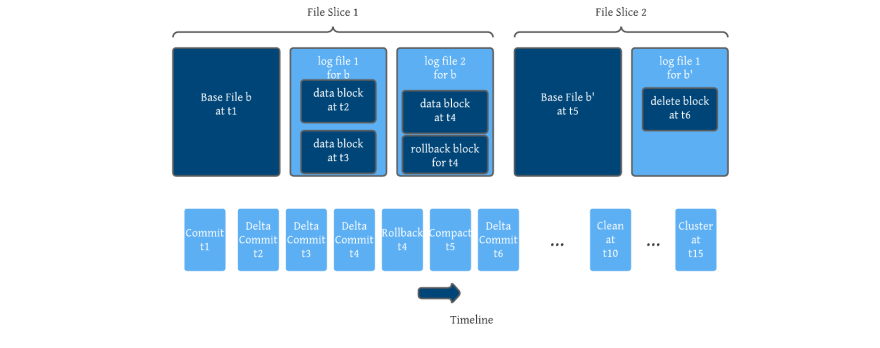
Table Format
The term “table format” is new and still means many things to many people. Drawing an analogy to file formats, a table format simply consists of : the file layout of the table, table’s schema and metadata tracking changes to the table. Hudi is not a table format, it implements one internally. Hudi uses Avro schemas to store, manage and evolve a table’s schema. Currently, Hudi enforces schema-on-write, which although stricter than schema-on-read, is adopted widely in the stream processing world to ensure pipelines don't break from non backwards compatible changes.
Hudi consciously lays out files within a table/partition into groups and maintains a mapping between an incoming record’s key to an existing file group. All updates are recorded into delta log files specific to a given file group and this design ensures low merge overhead compared to approaches like Hive ACID, which have to merge all delta records against all base files to satisfy queries. For e.g, with uuid keys (used very widely) all base files are very likely to overlap with all delta logs, rendering any range based pruning useless. Much like state stores, Hudi’s design anticipates fast key based upserts/deletes and only requires merging delta logs within each file group. This design choice also lets Hudi provide more capabilities for writing/querying as we will explain below.

The timeline is the source-of-truth event log for all Hudi’s table metadata, stored under the .hoodie folder, that provides an ordered log of all actions performed on the table. Events are retained on the timeline up to a configured interval of time/activity. Each file group is also designed as it’s own self-contained log, which means that even if an action that affected a file group is archived from the timeline, the right state of the records in each file group can be reconstructed by simply locally applying the delta logs to the base file. This design bounds the metadata size, proportional to how often the table is being written to/operated on, independent of how large the entire table is. This is a critical design element needs for supporting frequent writes/commits to tables.
Lastly, new events on the timeline are then consumed and reflected onto an internal metadata table, implemented as another merge-on-read table offering low write amplification. Hudi is able to absorb quick/rapid changes to table’s metadata, unlike table formats designed for slow-moving data. Additionally, the metadata table uses the HFile base file format, which provides indexed lookups of keys avoiding the need for reading the entire metadata table to satisfy metadata reads. It currently stores all the physical file paths that are part of the table, to avoid expensive cloud file listings.
A key challenge faced by all the table formats out there today, is the need for expiring snapshots/controlling retention for time travel queries such that it does not interfere with query planning/performance. In the future, we plan to build an indexed timeline in Hudi, which can span the entire history of the table, supporting a time travel look back window of several months/years.
Indexes
Indexes help databases plan better queries, that reduce the overall amount of I/O and deliver faster response times. Table metadata about file listings and column statistics are often enough for lake query engines to generate optimized, engine specific query plans quickly. This is however not sufficient for Hudi to realize fast upserts. Hudi already supports different key based indexing schemes to quickly map incoming record keys into the file group they reside in. For this purpose, Hudi exposes a pluggable indexing layer to the writer implementations, with built-in support for range pruning (when keys are ordered and largely arrive in order) using interval trees and bloom filters (e.g: for uuid based keys where ordering is of very little help). Hudi also implements a HBase backed external index which is much more performant although more expensive to operate. Hudi also consciously exploits the partitioning scheme of the table to implement global and non-global indexing schemes. Users can choose to enforce key constraints only within a partition, in return for O(num_affected_partitions) upsert performance as opposed to O(total_partitions) in the global indexing scenarios. We refer you to this blog, that goes over indexing in detail. Ultimately, Hudi's writer path ensures the index is always kept in sync with the timeline and data, which is cumbersome and error prone to implement on top of a table format by hand.
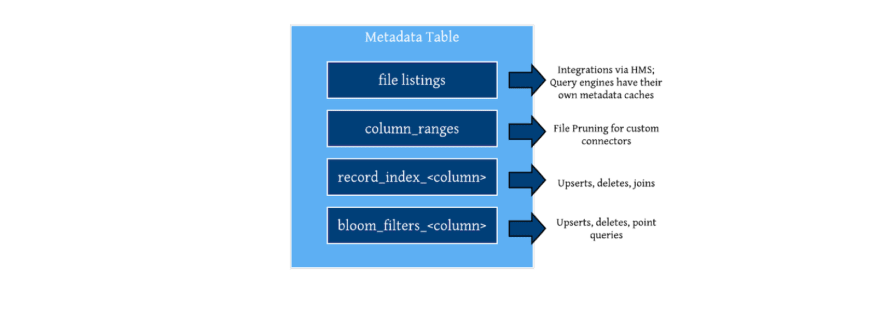
In the future, we intend to add additional forms of indexing as new partitions on the metadata table. Let’s discuss the role each one has to play briefly. Query engines typically rely on partitioning to cut down the number of files read for a given query. In database terms, a Hive partition is nothing but a coarse range index, that maps a set of columns to a list of files. Table formats born in the cloud like Iceberg/Delta Lake, have built-in tracking of column ranges per file in a single flat file (json/avro), that helps avoid planning costs for large/poorly sized tables. This need has been largely reduced for Hudi tables thus far, given Hudi automatically enforces file sizes which help bound time taken to read out stats from parquet footers for e.g. However, with the advent of features like clustering, there is a need for writing smaller files first and then reclustering in a query optimized way. We plan to add indexed column ranges, that can scale to lots of small files and support faster mutations . See RFC-27 to track the design process and get involved.
While Hudi already supports external indexes for random write workloads, we would like to support point-lookup-ish queries right on top of lake storage, which helps avoid the overhead of an additional database for many classes of data applications. We also anticipate that uuid/key based joins will be sped up a lot, by leveraging record level indexing schemes, we build out for fast upsert performance. We also plan to move our tracking of bloom filters out of the file footers and into its own partition on the metadata table. Ultimately, we look to exposing all of this to the queries as well in the coming releases.
Concurrency Control
Concurrency control defines how different writers/readers coordinate access to the table. Hudi ensures atomic writes, by way of publishing commits atomically to the timeline, stamped with an instant time that denotes the time at which the action is deemed to have occurred. Unlike general purpose file version control, Hudi draws clear distinction between writer processes (that issue user’s upserts/deletes), table services (that write data/metadata to optimize/perform bookkeeping) and readers (that execute queries and read data). Hudi provides snapshot isolation between all three types of processes, meaning they all operate on a consistent snapshot of the table. Hudi provides optimistic concurrency control (OCC) between writers, while providing lock-free, non-blocking MVCC based concurrency control between writers and table-services and between different table services.
Projects that solely rely on OCC deal with competing operations, by either implementing a lock or relying on atomic renames. Such approaches are optimistic that real contention never happens and resort to failing one of the writer operations if conflicts occur, which can cause significant resource wastage or operational overhead. Imagine a scenario of two writer processes : an ingest writer job producing new data every 30 minutes and a deletion writer job that is enforcing GDPR taking 2 hours to issue deletes. If there were to overlap on the same files (very likely to happen in real situations with random deletes), the deletion job is almost guaranteed to starve and fail to commit each time, wasting tons of cluster resources. Hudi takes a very different approach that we believe is more apt for lake transactions, which are typically long-running. For e.g async compaction that can keep deleting records in the background without blocking the ingest job. This is implemented via a file level, log based concurrency control protocol which orders actions based on their start instant times on the timeline.
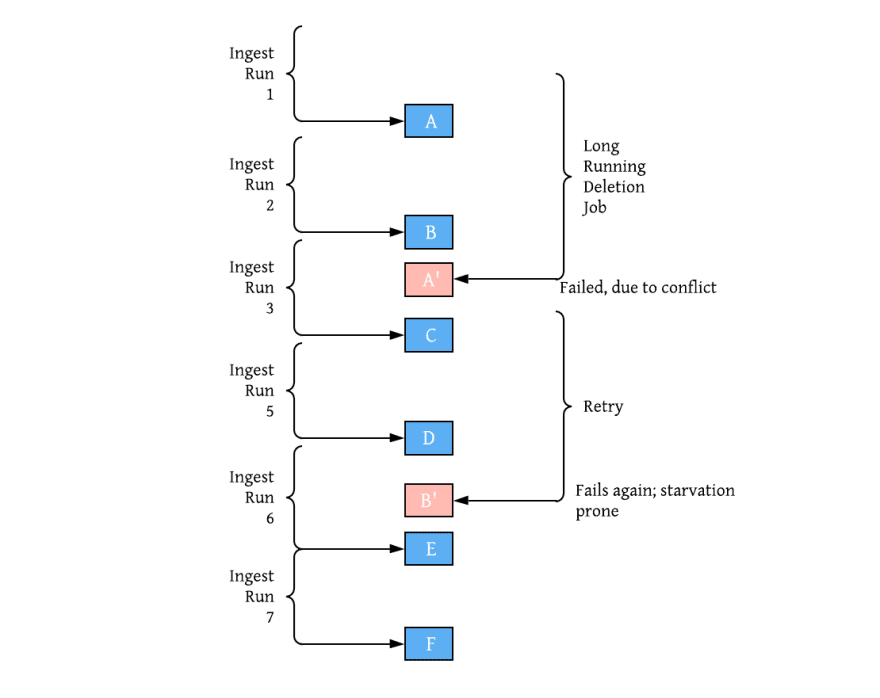
We are hard at work, improving our OCC based implementation around early detection of conflicts for concurrent writers and terminate early without burning up CPU resources. We are also working on adding fully log based, non-blocking concurrency control between writers, where writers proceed to write deltas and conflicts are resolved later in some deterministic timeline order - again much like how stream processing programs are written. This is possible only due to Hudi’s unique design that sequences actions into an ordered event log and the transaction handling code is aware of the relationship/interdependence of actions to each other.
Writers
Hudi tables can be used as sinks for Spark/Flink pipelines and the Hudi writing path provides several enhanced capabilities over file writing done by vanilla parquet/avro sinks. Hudi classifies write operations carefully into incremental (insert, upsert, delete) and batch/bulk operations (insert_overwrite, insert_overwrite_table, delete_partition, bulk_insert) and provides relevant functionality for each operation in a performant and cohesive way. Both upsert and delete operations automatically handle merging of records with the same key in the input stream (say, a CDC stream obtained from upstream table) and then lookup the index, finally invoke a bin packing algorithm to pack data into files, while respecting a pre-configured target file size. An insert operation on the other hand, is intelligent enough to avoid the precombining and index lookup, while retaining the benefits of the rest of the pipeline. Similarly, bulk_insert operation provides several sort modes for controlling initial file sizes and file counts, when importing data from an external table to Hudi. The other batch write operations provide MVCC based implementations of typical overwrite semantics used in batch data pipelines, while retaining all the transactional and incremental processing capabilities, making it seamless to switch between incremental pipelines for regular runs and batch pipelines for backfilling/dropping older partitions. The write pipeline also contains lower layers optimizations around handling large merges by spilling to rocksDB or an external spillable map, multi-threaded/concurrent I/O to improve write performance.
Keys are first class citizens inside Hudi and the pre-combining/index lookups done before upsert/deletes ensure a key is unique across partitions or within partitions, as desired. In contrast with other approaches where this is left to data engineer to co-ordinate using MERGE INTO statements, this approach ensures quality data especially for critical use-cases. Hudi also ships with several built-in key generators that can parse all common date/timestamps, handle malformed data with an extensible framework for defining custom key generators. Keys are also materialized with the records using the _hoodie_record_key meta column, which makes it possible to change the key fields and perform repairs on older data with incorrect keys for e.g. Finally, Hudi provides a HoodieRecordPayload interface is very similar to processor APIs in Flink or Kafka Streams, and allows for expressing arbitrary merge conditions, between the base and delta log records. This allows users to express partial merges (e.g log only updated columns to the delta log for efficiency) and avoid reading all the base records before every merge. Routinely, we find users leverage such custom merge logic during replaying/backfilling older data onto a table, while ensuring newer updates are not overwritten causing the table's snapshot to go back in time. This is achieved by simply using the HoodieDefaultPayload where latest value for a given key is picked based a configured precombine field value in the data.
Hudi writers add metadata to each record, that codify the commit time and a sequence number for each record within that commit (comparable to a Kafka offset), which make it possible to derive record level change streams. Hudi also provides users the ability to specify event time fields in incoming data streams and track them in the timeline.Mapping these to stream processing concepts, Hudi contains both arrival and event time for records for each commit, that can help us build good watermarks that inform complex incremental processing pipelines. In the near future, we are looking to add new metadata columns, that encode the source operation (insert, update, delete) for each record, before we embark on this grand goal of full end-end incremental ETL pipelines. All said, we realized many users may simply want to use Hudi as an efficient write layer that supports transactions, fast updates/deletes. We are looking into adding support for virtual keys and making the meta columns optional, to lower storage overhead, while still making rest of Hudi's capabilities (metadata table, table services, ..) available.
Readers
Hudi provides snapshot isolation between writers and readers and allows for any table snapshot to be queries consistently from all major lake query engines (Spark, Hive, Flink, Presto, Trino, Impala) and even cloud warehouses like Redshift. In fact, we would love to bring Hudi tables as external tables with BigQuery/Snowflake as well, once they also embrace the lake table formats more natively. Our design philosophy around query performance has been to make Hudi as lightweight as possible whenever only base columnar files are read (CoW snapshot, MOR read-optimized queries), employing the engine specific vectorized readers in Presto, Trino, Spark for e.g to be employed. This model is far more scalable than maintaining our own readers and users to benefit from engine specific optimizations. For e.g Presto, Trino all have their own data/metadata caches. Whenever, Hudi has to merge base and log files for a query, Hudi takes control and employs several mechanisms (spillable maps, lazy reading) to improve merge performance, while also providing a read-optimized query on the data that trades off data freshness for query performance. In the near future, we are investing deeply into improving MoR snapshot query performance in many ways such as inlining parquet data, special handling of overwrite payloads/merges.
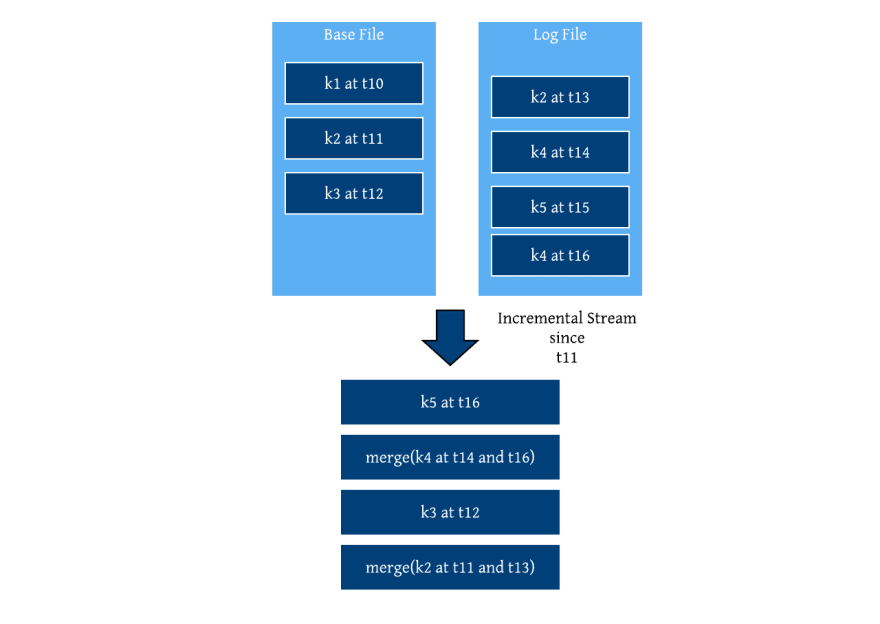
True to its design goals, Hudi provides some very powerful incremental querying capabilities that tied together the meta fields added during writing and the file group based storage layout. While table formats that merely track files, are only able to provide information about files that changed during each snapshot or commits, Hudi generates the exact set of records that changed given a point in the timeline, due to tracking of record level event and arrival times. Further more, this design allows large commits to be consumed in smaller chunks by an incremental query, fully decoupling the writing and incremental querying of data. Time travel is merely implemented as an incremental query that starts and stops at an older portion of the timeline. Since Hudi ensures that a key is atomically mapped to a single file group at any point in time, it makes it possible to support full CDC capabilities on Hudi tables, such as providing all possible values for a given record since time t, CDC streams with both before and after images. All of these functionalities can be built local to each file group, given each file group is a self-contained log. Much of our future work in this area will be around bringing such a powerful set of debezium like capabilities to life in the coming months.
Table Services
What defines and sustains a project’s value over years are its fundamental design principles and the subtle trade offs. Databases often consist of several internal components, working in tandem to deliver efficiency, performance and great operability to its users. True to intent to act as state store for incremental data pipelines, we designed Hudi with built-in table services and self-managing runtime that can orchestrate/trigger these services to optimize everything internally. In fact, if we compare rocksDB (a very popular stream processing state-store) and Hudi’s components, the similarities become obvious.

There are several built-in table services, all with the goal of ensuring performant table storage layout and metadata management, which are automatically invoked either synchronously after each write operation, or asynchronously as a separate background job. Furthermore, Spark (and Flink) streaming writers can run in continuous mode, and invoke table services asynchronously sharing the underlying executors intelligently with writers. Archival service ensures that the timeline holds sufficient history for inter service co-ordination (e.g compactions wait for other compactions to complete on the same file group), incremental queries. Once events expire from the timeline, the archival service cleans up any side-effects from lake storage (e.g. rolling back of failing concurrent transactions). Hudi's transaction management implementation allows all of these services to be idempotent and thus resilient to failure via just simple retries. Cleaner service works off the timeline incrementally (eating our own incremental design dog food), removing file slices that are past the configured retention period for incremental queries, while also allowing sufficient time for long running batch jobs (e.g Hive ETLs) to finish running. Compaction service comes with built-in strategies (date partitioning based, I/O bounded), that merges a base file with a set of delta log files to produce new base file, all while allowing writes to happen concurrently to the file group. This is only possible due to Hudi's grouping of files into groups and support for flexible log merging, and unlocks non-blocking execution of deletes while concurrent updates are being issues to the same set of records. Clustering service functions similar to what users find in BigQuery or Snowflake, where users can group records that are often queried together by sort keys or control file sizes by coalescing smaller base files into larger ones. Clustering is fully aware of other actions on the timeline such as cleaning, compaction, and it helps Hudi implement intelligent optimizations like avoiding compaction on file groups that are already being clustered, to save on I/O. Hudi also performs rollback of partial writes and cleans up any uncommitted data from lake storage, by use of marker files that track any files created as a part of write operations. Finally, the bootstrap service performs one time zero copy migration of plain parquet tables to Hudi, while allowing both pipelines to operate in parallel, for data validation purposes. Cleaner service is once again aware of these bootstrapped base files and can optionally clean them up, to ensure use-cases like GDPR compliance are met.
We are always looking for ways to improve and enhance our table services in meaningful ways. In the coming releases, we are working towards a much more scalable model of cleaning up partial writes, by consolidating marker file creation using our timeline metaserver, which avoids expensive full table scans to seek out and remove uncommitted files. We also have various proposals to add more clustering schemes, unlock clustering with concurrent updates using fully log based concurrency control.
Data Services
As noted at the start, we wanted to make Hudi immediately usable for common end-end use-cases and thus invested deeply into a set of data services, that provide functionality that is data/workload specific, sitting on top of the table services, writers/readers directly. Foremost in that list, is the Hudi DeltaStreamer utility, which has been an extremely popular choice for painlessly building a data lake out of Kafka streams and files landing in different formats on top of lake storage. Over time, we have also built out sources that cover all major systems like a JDBC source for RDBMS/other warehouses, Hive source and even incrementally pulling data from other Hudi tables. The utility supports automatic checkpoint management tracking source checkpoints as a part of target Hudi table metadata, with support for backfills/one-off runs. DeltaStreamer also integrates with major schema registries such as Confluent's and also provides checkpoint translation from other popular mechanisms like Kafka connect. It also supports de-duplication of data, multi-level configuration management system, built in transformers that take arbitrary SQL or coerce CDC log changes into writable forms, that combined with other aforementioned features can be used for deploying production grade incremental pipelines. Finally, just like the Spark/Flink streaming writers, DeltaStreamer is able to run in a continuous mode, with automatic management of table services. Hudi also provides several other tools for snapshotting and incrementally exporting Hudi tables, also importing/exporting/bootstrapping new tables into Hudi. Hudi also provides commit notifications into Http endpoints or Kafka topics, about table commit activity, which can be used for analytics or building data sensors in workflow managers like Airflow to trigger pipelines.
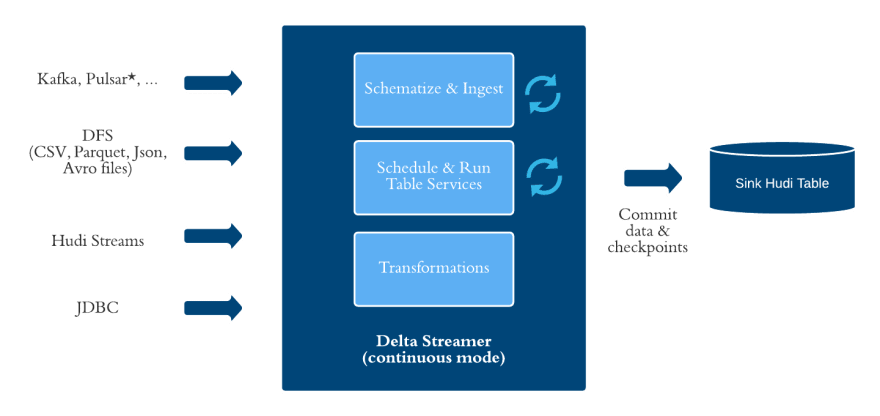
Going forward, we would love contributions to enhance our multi delta streamer utility, which can ingest entire Kafka clusters in a single large Spark application, to be on par and hardened. To further our progress towards end-end complex incremental pipelines, we plan to work towards enhancing the delta streamer utility and its SQL transformers to be triggered by multiple source streams (as opposed to just the one today) and unlock materialized views at scale. We would like to bring an array of useful transformers that perform masking or data monitoring, and extend support for egress of data off Hudi tables into other external sinks as well. Finally, we would love to merge the FlinkStreamer and the DeltaStreamer utilities into one cohesive utility, that can be used across engines. We are constantly improving existing sources (e.g support for parallelized listings of DFS sources) and adding new ones (e.g S3 event based DFS source)
Timeline Metaserver
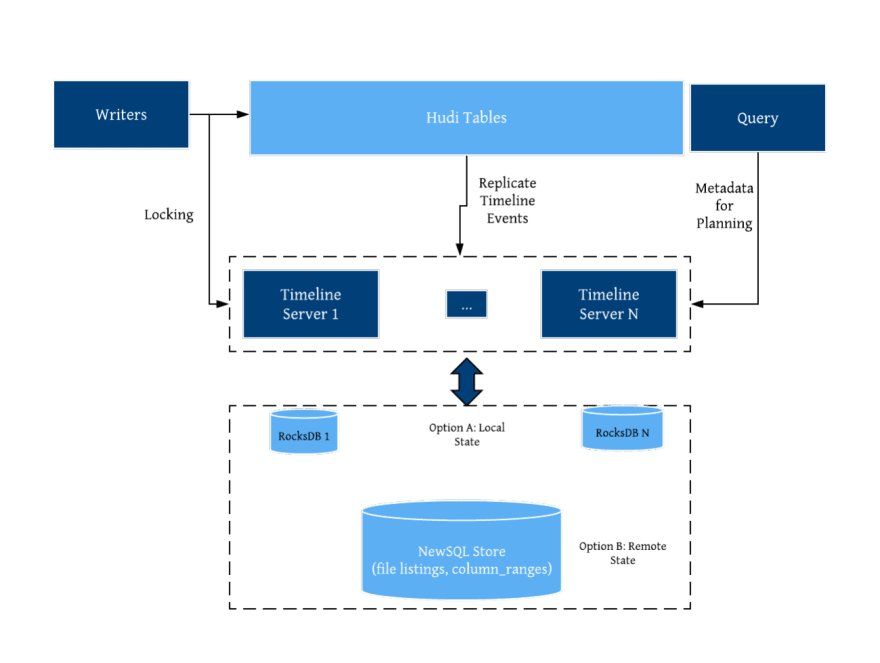
Storing and serving table metadata right on the lake storage is scalable, but can be much less performant compared to RPCs against a scalable meta server. Most cloud warehouses internally are built on a metadata layer that leverages an external database (e.g Snowflake uses foundationDB). Hudi also provides a metadata server, called the “Timeline server”, which offers an alternative backing store for Hudi’s table metadata. Currently, the timeline server runs embedded in the Hudi writer processes, serving file listings out of a local rocksDB store/Javalin REST API during the write process, without needing to repeatedly list the cloud storage. Given we have hardened this as the default option since our 0.6.0 release, we are considering standalone timeline server installations, with support for horizontal scaling, database/table mappings, security and all the features necessary to turn it into a highly performant next generation lake metastore.
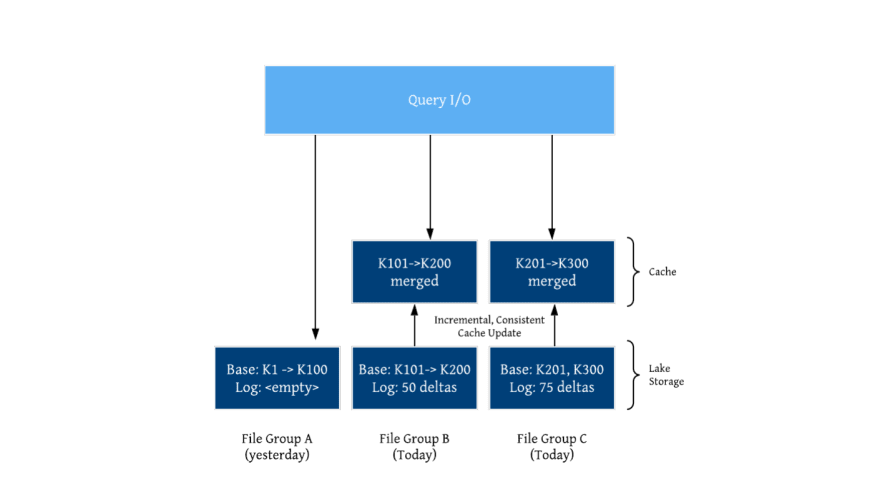
Lake Cache
There is a fundamental tradeoff today in data lakes between faster writing and great query performance. Faster writing typically involves writing smaller files (and later clustering them) or logging deltas (and later merging on read). While this provides good performance already, the pursuit of great query performance often warrants opening fewer number of files/objects on lake storage and may be pre-materializing the merges between base and delta logs. After all, most databases employ a buffer pool or block cache, to amortize the cost of accessing storage. Hudi already contains several design elements that are conducive for building a caching tier (write-through or even just populated by an incremental query), that will be multi-tenant and can cache pre-merged images of the latest file slices, consistent with the timeline. Hudi timeline can be used to simply communicate caching policies, just like how we perform inter table service co-ordination. Historically, caching has been done closer to the query engines or via intermediate in-memory file systems. By placing a caching tier closer and more tightly integrated with a transactional lake storage like Hudi, all query engines would be able to share and amortize the cost of the cache, while supporting updates/deletes as well. We look forward to building a buffer pool for the lake that works across all major engines, with the contributions from the rest of the community.
Onwards
We hope that this blog painted a complete picture of Apache Hudi, staying true to its founding principles. Interested users and readers can expect blogs delving into each layer of the stack and an overhaul of our docs along these lines in the coming weeks/months. We view the current efforts around table formats as merely removing decade-old bottlenecks in data lake storage/query planes, problems which have been already solved very well in cloud warehouses like Big Query/Snowflake. We would like to underscore that our vision here is much greater, much more technically challenging. We as an industry are just wrapping our heads around many of these deep, open-ended problems, that need to be solved to marry stream processing and data lakes, with scale and simplicity. We hope to continue to put community first and build/solve these hard problems together. If these challenges excite you and you would like to build for that exciting future, please come join our community.

Top comments (0)