If understanding the inner workings of SQL and NoSQL databases didn’t leave your head spinning, I’d like to dust off a database relic, the Multi-Version database. These systems are actually a fairly simple concept and have been around for decades. Why haven’t you heard of them? Unless you spend your time reading academic papers it’s probably because they never got traction because of hardware constraints. When Multi-Version databases were introduced, storage was for the 1%… Now that storage is a lot cheaper, Multi-Version systems can be revisited as an applicable and cost-effective database solution.
Multi-Version databases are important because:
- immutable datastores enhance security
- accessible versioning provides in-depth analytics and auditing
- updates to your data are faster
On a more technical note they:
- reduce locking overhead
- don’t require pages to be re-packed
- eliminate the need for manual snapshots
Multi-Version and Data Storage
While Uni-Version Systems (SQL and NoSQL) only keep track of the current state of the database, Multi-Version systems track every change that has occurred in the system. Data is never truly altered or removed, updated data is added to the data files; data is immutable.
As a result, an append-only system increases the amount of storage used by an application. Initially, this made Multi-Version systems an expensive data management method.
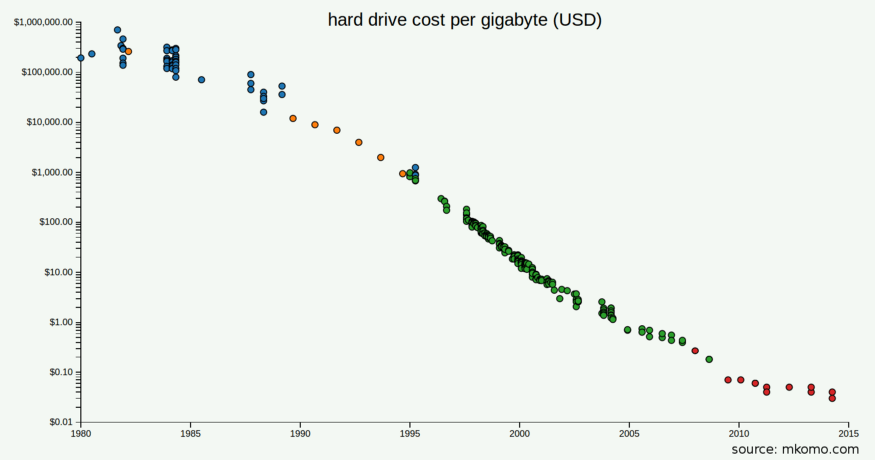 Historic prices of hard drive space, from Matt Komorowski.
Historic prices of hard drive space, from Matt Komorowski.
In the 1980s, shortly after the Multi-Version database was conceived, storage cost was upwards of $100,000 per Gb…. today storage costs less than $.05 per Gb. The major decrease in storage costs lets us reconsider the Multi-Version database.
Updating Your Data
In order to maintain the state of a Uni-Version system, the database management system has to use complicated control measures to coordinate access to recourses and prevent data corruption.
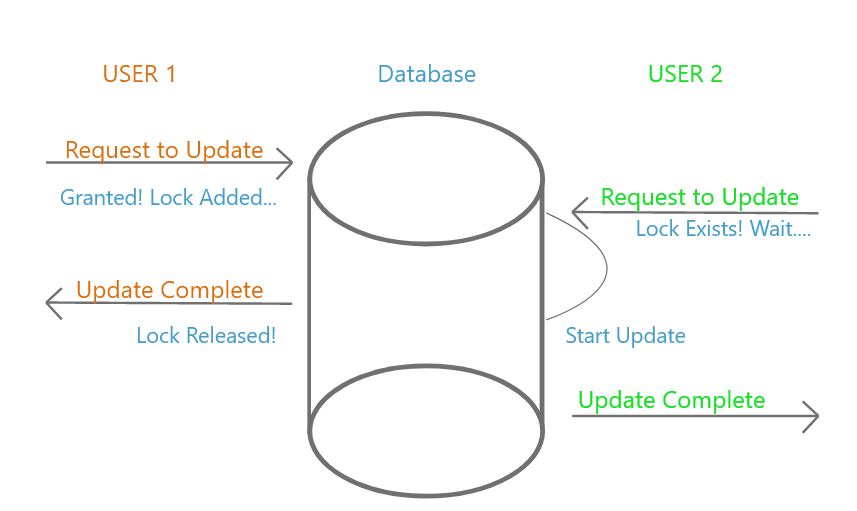 (Figure 1)
(Figure 1)
When access is granted to the resource, the data is said to have a “lock” on it. When User 1 requests to update a value (figure 1), a lock is added to the system. Data can’t be accessed by another source until the lock is released, hence, User 2 has to wait until the lock is released to perform an update. Locking makes resources inaccessible for an undefined period of time. Locking systems require downtime and compute, increasing the overhead associated with large transaction loads.
Multi-version systems don’t require complex locking mechanisms because data can only be added to the end of the file. In this fashion, requests for updates can be handled concurrently. By eliminating traditional locking, removing and updating data is inherently faster, allowing applications to run at higher speeds and certain data cleaning processes become obsolete.
Data Cleaning
When packed data is deleted or updated in a Uni-Version system, the space allotted to the original data is no longer in use and deemed inaccessible.
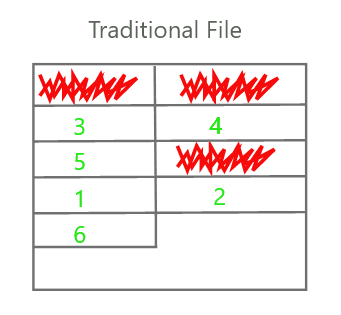 (figure 2) Red scribbles represent empty space in a data file.
(figure 2) Red scribbles represent empty space in a data file.
Inaccessible space provides no value until it’s eventually recycled and made usable by the database management system during a process commonly called database “vacuuming”. For example, when updating a specific value, the system deems the old value unusable, appends the updated data to the end of the file, and cleans the empty space during the next vacuum cycle.
When data is “updated” or “deleted” in a multi-version system, the updated record is simply added to the end of the file. Previous data is never modified, instead, all changes are written to the next free slot. Multi-Version data mutations require only fetching the next free slot, there is no need to find the original tuple. This method decreases the number of data pages that are potentially brought into memory, increasing mutation speed, and reducing the amount of time that resources are locked.
Analytics
In traditional systems, snapshots are used to track changes to the database after the snapshot was created. Snapshots are commonly used for time-based analytics and auditing. As an application grows and analytics begin to develop, snapshots become a daily routine for teams.
Since Multi-Version databases track full database history, fine-grain snapshotting can be easily integrated into the system. Snapshots don’t rely on user commands as all versions of the database are accessible at all times. Fine-grained snapshots provide additional dimensions to your data. For example, in a Multi-Version database, it would be possible to get the state of a table before a specific value was updated. A rich data-history provides the analytics team access to insightful queries that span database versions.
 (figure 3) A time travel query.
(figure 3) A time travel query.
Conclusion
In conclusion, database implementations should adapt to the hardware that supports them. We have been relying on the same Uni-Version systems for the past 30 years. Is this the best implementation? How can we adapt our management systems to capitalize on the efficiency of cloud computing? Multi-Version databases were once an unrealistic and expensive solution, yet revisiting them uncovers a lot of programmatic benefits that are no longer constrained by costs. As the emphasis shifts from storage size to speed and analytics, a Multi-Version implementation becomes an effective choice for data-driven applications.

Latest comments (2)
I definitely subscribe to this philosophy of immutable data. But is there a DB that supports this natively?
Greg, you should check out Blockpoint Systems. They are setting up free trials for first adopters, you can sign up here if you're interested.