
Machine learning pipelines contain a sequence of independent and separate steps that define a machine learning workflow for solving a specific problem. The goals of a machine learning pipeline are:
- Improve the quality of models developed and deployed to production.
- Make it easy to reuse components to create end-to-end solutions without rebuilding each time.
- Allow individuals and teams to focus more on developing new solutions than maintaining existing solutions. Simplify the end-to-end orchestration of the standard machine learning workflow for projects with little to no intervention from the ML team.
This will be a two-part article: In this article (first part), you will get an overview of an ML pipeline and how it automates the ML workflow, what Apache spark is and why you should build ML pipelines with it. You'll also learn about the rich ML ecosystem Apache Spark provides and the challenges of building ML models and pipelines with Apache Spark.
In the second article, you will use Apache Spark to build and deploy a real-time ML pipeline on Amazon EMR, MLeap, and SageMaker.
Let's jump right into it! 🚀🚀
Steps in the machine learning process
The steps in an ML pipeline are based on the typical ML workflow. There are various stages in the ML workflow, and the steps within these stages account for the processes in most machine learning projects.

Three stages in a machine learning workflow | Source: Author.
Most machine learning projects will require you to deploy models to production, which this workflow focuses on. In the image above, there are three stages of the workflow:
Data acquisition and feature management: Collecting, assessing, cleaning, etc.
Experiment management and model development.
Production model management.
What does a machine learning pipeline look like?
A machine learning pipeline takes the steps from the machine learning workflow that are repeatable and separates them into individual components that can be combined to solve a specific problem. It simplifies the steps in the (ML) workflow.

Typical machine learning pipeline with various stages highlighted | Source: Author.
Why build machine learning pipelines with Spark
Apache Spark is a fast and general open-source engine for large-scale, distributed data processing. Its flexible in-memory framework allows it to handle batch and real-time analytics alongside distributed data processing.
Here are the primary reasons you might want to consider building ML pipelines with Spark:
- The Spark engine is optimized for big data workloads and, generally, scaling applications. Production pipelines often have to deal with the complexity of batch or streaming data. Spark can perform ETL, streaming, machine learning, and graph processing on batch or streaming data in production.
- Spark data processing is fast because of its distributed, in-memory data processing engine, which efficiently scales production pipelines.
- Spark provides a unified engine for building data and machine learning pipelines into an efficient application for production machine learning applications, making deployment of the pipelines easy.
- Spark is open-source and platform-agnostic: Your ML pipelines built on Spark are portable and can be moved across platforms and infrastructure. Most platforms and cloud vendors offer services that can run Spark applications.
Apache Spark machine learning ecosystem
Spark is used in several machine learning systems in production, from recommendation engines to real-time fraud detection systems and customer analytic engines. For a real-world use case, Spark is a central component in Payoneer’s real-time fraud detection system.
The general Spark ecosystem includes:
- Spark core API: The foundation of the Spark ecosystem and provides an interface to run distributed processing jobs on data with Scala, Java, Python, SQL, or R.
- Spark MLib: The machine learning component of Apache Spark.
- Spark Streaming: The component for real-time data processing and analytics.
- Spark SQL: Uses DataFrames as an interface for working with data in Spark.
- GraphX: For performing graph data processing and running graph database jobs at scale.
Spark works locally on stand-alone clusters and on Hadoop YARN, Apache Mesos, Kubernetes, and other managed Hadoop platforms.
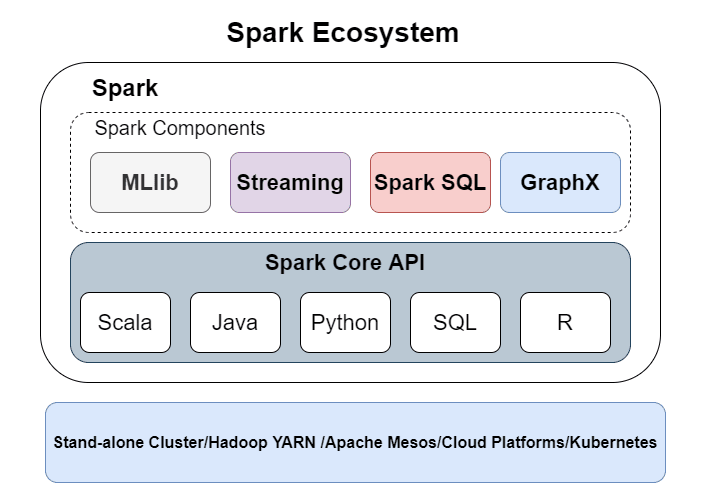
Spark ecosystem illustration. | Source: Author.
Resilient Distributed Datasets (RDD)s: The building blocks of Spark
Resilient Distributed Datasets (or RDDs) is Spark’s fundamental data structure and the lowest level API for working with datasets. DataFrames and the Spark APIs are built on the RDDs, and understanding this is crucial to using Spark. The RDDs make Spark so fast as they are in-memory objects in which all operations in Spark are performed.
RDDs are:
- Partitioned: Split across data nodes in a cluster.
- Immutable: Once objects are created in an RDD, nothing can change them. While performing certain operations, you cannot alter the content in a single RDD.
- Resilient: They are fault-tolerant because they can be reconstructed automatically on the remaining nodes, and the job will still be completed even if a computing node crashes.
There are only two operations permitted in RDD:
Transformation: Takes an RDD as input and creates an entirely new RDD with the operation you want to perform reflected on the RDD. Transformation refers to a series of changes to an RDD.
Action: You request a result, which causes Spark to execute a series of transformations on the RDD.
Spark follows lazy evaluation: It keeps track of a series of transformations performed on your data and groups the transformations efficiently when an action is requested.
Components of Spark ML
spark.ml and spark.mllib are the packages available to do ML on Spark. This guide uses the spark.ml package to build an end-to-end ML pipeline. Nowadays, production ML systems rely on ML pipelines for high-performance functions. spark.ml is optimized for ML pipelines and high-performance ML.
The documentation states that the spark.ml package aims to provide a uniform set of high-level APIs built on DataFrames that help users create and tune practical machine learning pipelines. DataFrames provide a data interface for other Spark applications to connect to.
At the high level, the components of the spark.ml package include:
Algorithms
These include machine learning algorithms for supervised and unsupervised learning problem types. For supervised learning, Spark ML comes with various:
- Classification,
- Regression,
- CART (Classification and Regression Trees),
- And tree-based algorithms (random forests, gradient-boosted trees).
Learn more about the specific algorithms the package supports in this preview. The package supports clustering algorithms for unsupervised learning problem types such as K-Means, LDA, GMM, and so on.
The package also supports algorithms for specialized machine learning problems such as recommendations. As of the time of this writing, it only supports the collaborative filtering technique to build recommendation systems.
Workflows
Workflows in the Spark ML package help organize the commonly used steps in the machine learning process. They make it easy to run the sequence of steps repeatedly with different configurations. You probably see a pattern here because that is similar to what ML pipelines help you accomplish.
As per the documentation, let’s look at the main concepts in a Spark ML pipeline:
These concepts are high-level abstractions, and when chained together into a single ML pipeline, they form a machine learning workflow.

Machine learning pipeline in Spark. | Source: Author.
The concepts are similar to the Scikit-learn project. They follow Spark’s “ease of use” characteristic giving you one more reason for adoption. You will learn more about these main concepts in this guide.
Before you build your ML pipeline in Spark, you will need to learn about the concepts highlighted earlier: DataFrames, Transformers, Estimators, Pipeline, and Parameter. After learning these concepts, you will use your knowledge to build an ML pipeline and deploy it for online inference.
Working with data in Spark: DataFrames
Spark provides different ways of working with data in its data interfaces. They include:
Earlier in this guide, you already learned about RDDs, as Spark 1.x is built on RDD, and you may only work with them for advanced and custom applications. Working with Spark 2 and above, you are more likely to use the DataFrames or Datasets interface.
For this guide, you will use DataFrames as it has a similar feel to using Pandas, and the Datasets API is not available for Python (or R)—only Java and Scala.
What are DataFrames in Spark?
DataFrames are a Pandas-like, intuitive high-level API for working with data in Spark. It organizes data in a structured and tabular format in rows and columns, similar to a spreadsheet and a relational database management system. If you have worked with Pandas before, you should be familiar with DataFrames.
DataFrames are built on top of RDDs, which means they inherit virtually all the characteristics of RDDs. As you'd typically do with Pandas, you can perform operations on the DataFrame in Spark.
To create a DataFrame in Spark, take the following steps:
- Locate the data source.
- Read the text file.
- Read the directory of the text file.
- Create a DataFrame.
#1. Locate the data source.
data_dir = '/content/sample_data/california_housing_train.csv'
#2. Read the text file.
rawData = spark.read\
.format('csv')\
.option('header', 'True')\
.option('ignoreLeadingWhiteSpace', 'true')\
.load(data_dir) # 3. Read the directory of the text file.
#4. Create a DataFrame.
dataset = rawData.toDF('longitude', 'latitude', 'housing_median_age',
'total_rooms', 'total_bedrooms', 'population',
'households','median_income', 'median_house_value'
)
Transformers
The transformer abstraction uses an algorithm to take in a DataFrame as input and convert it to another DataFrame. They are great for preparing datasets in your Spark ML environment: you can write transformations that convert raw input data in your pipeline to a dataset that has been cleaned and prepared.
Since DataFrames are immutable, the transformation does not perform in-place operations on the DataFrame but appends one or more columns containing the result of the transformation.
Trained models are also transformers as they implement a .transform() method on a DataFrame to append predictions to it. Here’s an example of a feature transformer that normalizes a Vector to have unit norm:
from pyspark.ml.feature import Normalizer
dataFrame = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
# Normalize each Vector using $L^1$ norm.
normalizer = Normalizer(inputCol="features", outputCol="normFeatures", p=1.0)
l1NormData = normalizer.transform(dataFrame)
l1NormData.show()
# Normalize each Vector using $L^\infty$ norm.
lInfNormData = normalizer.transform(dataFrame, {normalizer.p: float("inf")})
lInfNormData.show()
Learn about other feature transformers in the Spark ML package in the documentation.
Estimators
Estimators are slightly different from transformers but complement them in the ML pipeline. Estimators call a .fit() method on a DataFrame. You are applying an algorithm to a dataset which could be a case of training an ML algorithm to generate a model.
Here’s an example of an estimator fitting on a DataFrame to produce a transformer:
from pyspark.ml.classification import LogisticRegression
# Load training data
data = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
# Split the data into training and test sets (30% held out for testing)
(trainingData, testData) = data.randomSplit([0.7, 0.3])
lr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fit the estimator on the training data
lrModel = lr.fit(trainingData)
# Fitted estimator is now a transformer that can transform another DataFrame
predictions = lrModel.transform(testData)
Pipelines
Pipeline() combines different transformers and estimators into a workflow to be run in a specific order. In a Pipeline, each stage is either a transformer or an estimator.
The estimators and transformers perform operations on the input data stored in a DataFrame. Here’s an example of a Pipeline with stages that involve:
-
Feature transformers (
[StringIndexer](),OneHotEncoder(),VectorAssembler()),- And an estimator (Random forest classifier):
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF, Tokenizer
# Prepare training documents from a list of (id, text, label) tuples.
training = spark.createDataFrame([
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)], ["id", "text", "label"])
# Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
# Fit the pipeline to training documents.
model = pipeline.fit(training)
To get more details on pipelines and how they work, check out the documentation.
Parameters
Parameters are design settings for estimator and transformer algorithms.
# Estimator parameters
RandomForestClassifier(labelCol='Label', featuresCol='features', maxDepth=5)
# Example of Transformer parameters StringIndexer(inputCol="Categircal Column,
outputCol="Indexed_Column')
In the case of an estimator, the parameter for an algorithm like random forest could be a value assigned to the maxDepth (maximum depth) of a tree––the hyperparameter of the model. In the case of a feature transformer like StringIndexer(), the parameters are inputCol and outputCol.
Challenges of deploying machine learning pipelines with Spark
You have learned how Spark makes it easy to develop ML pipelines on distributed systems. However, some challenges are associated with deploying ML pipelines built with Spark:
Pipelines are tightly coupled with Spark runtime, making it complex to manage dependencies, pipeline versions, and compatibility with production environments.
Scoring Spark models is difficult for real-time systems (where scoring requires less than 100ms latency) because it is optimized for batch scoring.
To use a trained model (or pipeline) without Spark runtime, you will need to:
- Write custom readers for Spark’s native format; or
- Create your custom format; or
- Export to a standard format––this is not supported within Spark as of this writing and will require a custom solution.
To score models outside of Spark, you must write your custom translation between Spark ML components and an existing ML library.
Everything is custom and will take a lot of work, but luckily, you don’t have to do all the work here. In THE second article, you will use MLeap, a library that does the heavy lifting in terms of serializing Spark ML Pipeline for real-time inference and also provides an execution engine for Spark so you can deploy pipelines on non-Spark runtimes.
Conclusion
Apache Spark has a rich ecosystem for building machine learning models and pipelines that aid your worklow. In the first of a 2-part article, you learnt the why you should consider building ML pipelines with Spark, what Apache Spark offers you with its rich ML ecosystem, and the challenges of using Spark to build ML pipelines (which is mostly the aspect of slow model scoring).
In the next article, you will learn the various methods you can access and run Spark for your projects. More importantly, you'll learn:
- How to build and deploy a machine learning pipeline with Spark on Amazon EMR,
- Serialize the pipeline with MLeap to run in real-time,
- Serve the pipeline through an Amazon SageMaker endpoint.
References and resources
References
- Machine Learning with Spark - Second Edition | Packt (packtpub.com)
- What is Apache Spark?
- Productionizing Spark ML pipelines with the portable format for analytics(Challenges of deploying machine learning models with Spark)

Top comments (0)