
This retrospective was presented as a talk at Cakefest 2019 in Tokyo Japan
Background: Our specialty is human movement data, we collect anonymized telemetry over millions of devices each day. This consists of some device information (OS, Brand, Model, Wireless capabilities etc). Also consists of Location data (Latitude, Longitude, Altitude etc).
By understanding human movement and intersecting this data with other datasets we can help businesses understand their customers – we can provide insights to allow a business to accurately predict customer intent / requirements.
We maintain a database of Millions of US POI’s, both shape data and ‘point’ data. By spatially joining the human movement data with this POI data we can get context as to the locations people visit and use this to determine intent.
Big Data: Due to the size of these data sets and the complexity in spatial processing, a normal RDBMS simply won't cut it or allow us to process this data within the 24 hour window we require - let alone allow us to create an interface that allows a human being to design their own audiences on-the-fly and receive instant estimates of the audience size.
The previous article I wrote discusses some of the challenges we faced early on in our development of this platform (https://www.linkedin.com/pulse/what-functional-big-data-dan-voyce), This article describes our methodology of testing various solutions before and after that - to bring us to the final solution we are currently using to process over 200B rows each day in under an hour.
The problem:
"To create a system where a customer can design their own audience by choosing and combining customer intents"
I won't go heavily into the analysis of this problem in this article but we eventually landed upon a system that would generate a "query" (not necessarily SQL) that we can run against our data warehouse to produce the audience.
The tricky part of this - was "How do we get an estimate displayed to the customer of the audience size"?
As the end user can design an audience from any combination of 8 filters (each containing 100's - 1000's of options) pre-caching the counts on each processing wasn't really feasible - especially since we were also providing the ability to filter between specific dates.
The solution:
There are a few well known methods for producing fast estimation of large datasets which I won't go into in this article but in both cases they came with a set of problems we needed to overcome, in the end it all came down to the choice of the underlying data warehouse / query engine we decided to use. This is what this article will focus on.
Why count(distinct()) is king - but definitely not equitable.
As developers most of us understand what count(distinct()) does, what many people don't understand (or think about) is HOW it does what it does.
Counting distinct entities in a huge dataset is actually a hard problem, it is slightly easier if the data is sorted but re-sorting data on each insert becomes expensive depending on the underlying platform used.
Generally a count distinct performs a distinct sort and then counts the items in each "bucket" of grouped values.
If you need a 100% accurate count then this is unfortunately pretty much the only way you can get it on a randomised dataset, there are tricks you can do in how things are structured in the platform to make things more efficient (partitioning, clustering / bucketing for example) but it essentially still has to perform the same operations.
Thankfully we are not in the position where we immediately require a 100% accurate answer - an estimate with a reasonable error margin is just fine for what we need. This opens up a few more options.
Rejected methods / platforms
These were methods we started to test out early on, we had a number of requirements that some were not able to provide (for example Geospatial processing is a pre-requisite we had as many of the counts we would have to provide would be based on Geospatial predicates).

Final method / platform choices
Which ever method we chose it would still need to be underpinned by a solid and future proof data warehouse, in the end we decided upon 2 to power different parts of the platform (to eventually be consolidated into a single data warehouse later in the process).
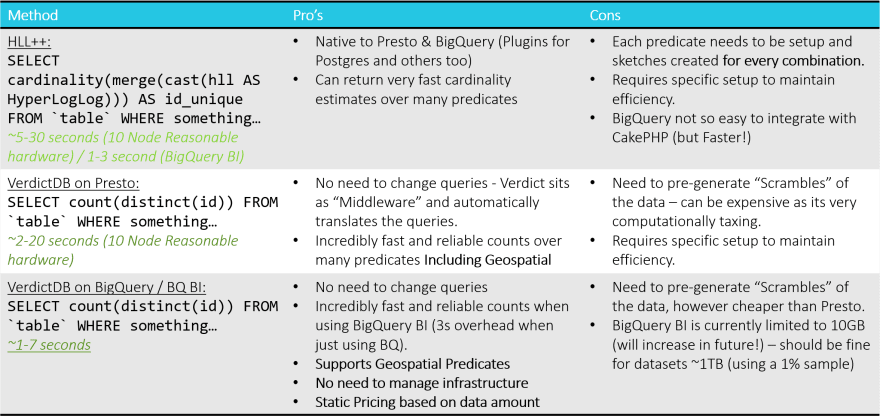
HyperLogLog++
For many years this was the gold standard in cardinality estimation, for static datasets it is still the recommended method as it is easily stored, very low maintenance and can merge counts from multiple "columns" to get an overall count. Unfortunately for us our queries were not static, we would have had to create a HLL sketch for every single combination of columns which wasn't feasible.
VerdictDB / Keebo
Early on during the process we started working with the guys at VerdictDB. VerdictDB is a fantastic product that uses probability / statistical theory to create estimates of cardinality on large datasets. With the support of the team at Verdict we were able to create a bridge to incorporate this into each of our platforms.
Presto
Presto is a query engine designed to provide an "SQL on Anything" type of interface for data. As all of our data was stored in Google Cloud Storage it was a natural choice. It is blazingly fast even with a small number of nodes and completely customisable. You can see why companies such as Teradata and Starburst data have adopted it to power their platforms.
There was a fair bit of optimisation required around the ORC format we chose to use with Presto but once this was completed we could power our Fast counts with a minimal 3 node cluster running over the scrambles and a 10 node cluster to perform the pre-processing required.
As long as good housekeeping was maintained on the data, the fast counts would usually return within around 5-7 seconds.
BigQuery
BigQuery is a Google product based on Dremel, it uses a massively parallel architecture to plan queries across a huge number of nodes all packaged as a fully managed and on-demand service to the user.
BigQuery BI is an in-memory caching service provided which cuts down on the 3s overhead to queries issued to BigQuery. By caching the scrambles and linking our infrastructure directly into this, we were able to ensure that the query would return in around 2 seconds on average.
Conclusion
With the use of VerdictDB both Presto and BigQuery provided the speed required to allow a human interface to our Data Warehouse, BigQuery out performed Presto in a number of areas when BigQuery BI was thrown into the equation, and although this is still in beta offering only 10GB (should be enough to cache a 1% scramble of 1TB of data), it has huge potential in offering a cost-effective and fast interface to Big Data.
If you want to avoid vendor lock-in then Presto is a fantastic choice, throwing more nodes at the situation would easily get the speed down to the BigQuery equivalent. There are also several other options that exist that could be used as the query interface once the scrambles are built on Presto!

|
Daniel Voyce - CTO Daniel leads the technology strategy, architecture and development at LOCALLY.
|

Top comments (0)