
In this article, we'll be rewinding back to the very beginning of the AWS Well-Architected Framework to understand how and why it came to be, and why is it of utmost importance, but very often underrated, for serverless developers to learn, understand and apply this framework of best-practices. We'll also be looking into how the framework has evolved and how it should be used in 2021.
For a more in-depth deep dive into each of the five pillars, you can download this free e-book, which dissects the pillars and explains the importance and how to implement these best practices in real life in an easily understandable manner.
The History of AWS Well-Architected Framework
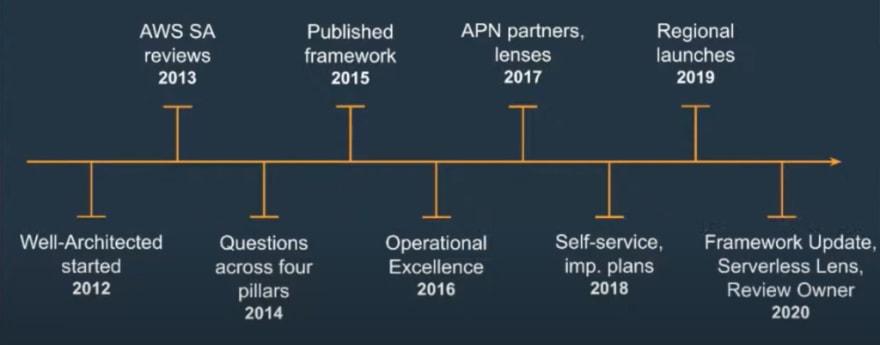
History of the Well-Architected Framework
In 2012, the AWS Well-Architected Framework came about in response to the build out of its portfolio. The industry and user feedback consistently showed that while there was plenty of documentation on the services, there wasn't enough of best practice. As ever, AWS listened to its users and published its first framework in 2015.
In 2016, the Operational Excellence pillar was introduced, again as a result of user feedback. The original Well-Architected Framework was rightly technically heavy, but more was needed and wanted for operational posture improvements, understanding how to reduce heavy lifting, and improve the day-to-day running of AWS infrastructure.
By the next year, there was now a massive proliferation of services and AWS wanted to cater for the segregation of environments seeing that the AWS Service Reviews were very different between classic architecture and serverless. So, in 2017, lenses were introduced which would overlay the original framework enabling speaking to specific workloads. It meant that the Reviews and adoption of AWS could be much more refined. We'll dig deeper into the lenses later on in this article.
Today, in 2020, there have been some big framework updates including updates to all pillars. AWS has also launched a Serverless Lens, which can be found in the Well-Architected tool within the console.
Why use Well-Architected?
- Customers want to build and deploy faster
Often, customers start in experimentation and workloads tend to develop organically with increasing additions. It's most common that in this growth process, a deviation of best practice can happen to make it harder to layer that complexity on the top. For this reason, we and AWS want to teach customers to align what they already have with best practices to ensure faster deployment and a better security posture.
- Lower or Mitigate Risks
Risks* span all pillars of the Framework (Reliability, Performance, Operational Excellence, Cost, and Security), and the Review process works to lower or mitigate risks over a period of time. Many customers find that they aren't sure what their risk profile is*, which becomes a big worry for C-level profiles who start asking "where do we sit in our risk profile?" and "how do we work to reduce that over a 6-12 month period?"
- Make Informed Decisions
With education and knowledge comes more power and* informed decisions*. Let's say a customer who has a 2-3 year old workload needs to be redeployed into a new environment, which has segregated accounts. Their options are; improve the existing environment or migrate the workload to a new one. The Well-Architected Review will be able to show the work needed for the remediations, including the upfront changes, ongoing maintenance, and costs.
- Learn AWS Best Practice
We have found that the happiest customers are those that feel well-educated from an AWS platform and service point of view. This includes instilling best practices, knowledge of new releases, the release cycles, and how services evolve. From here, they are more willing to share and build greater trust with AWS as a service.
What is the Well-Architected Framework?
What is the AWS Well-Architected Framework?
The pillars are the cornerstone of any AWS architecture, where the vertical segregation can be applied to any workload whether that is Serverless, EC2 or Big Data.
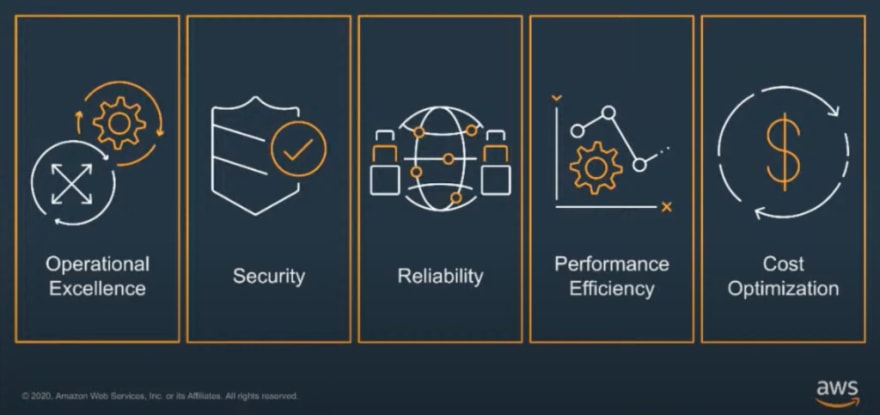
AWS Well-Architected Framework pillars
- Operational Excellence is the ability to understand how customers use their workloads. For example, how much time an employee spends on routine tasks, or how business objectives are being met?
- It's crucial that security is at depth and at every layer, and for it to be aligned with every service. This should always be a Day 1 initiative.
- Reliability is the ability to withstand a geo-specific event or even something more local. Things to consider are; what steps have been taken so that no matter the event, your service can still run as needed?
- Performance often bleeds into scalability. For example, on Black Friday, can your environment scale and remain elastic? Can it cope with a 5,6,7 fold increase? This also works in reverse. We want to avoid over the deployment of services that are too compute-heavy, which will have an impact elsewhere.
- Cost -- a pillar that always comes with a welcome smile. Cost optimization is so often a positive with customers. It's important to know how services evolve, different cost modeling options, and how to spot instances for some areas of architecture. It also includes working with a partner to recode, using microservices, and using Lambda.
Design principles
The design principles represent the goals we are aiming to achieve in each pillar. Looking at the objectives of the workloads is key here, and when running a Review, there will be many questions, architectural diagrams, and a gathering of information before the review itself. The quest here is to have a data-driven, informative review.
Intent of Review

AWS Well-Architected review
The intent of a Review is to provide insight into best practices for AWS. It's important to remember that it is not aligned with an audit or any regulatory body and that the data isn't shared. It's there to simply improve posture against all Well-Architected Framework pillars.
The Reviews provide pragmatic, proven advice that AWS knows work and that which is tailored to the customer's need.
For example, if the customer has a tight security posture requirement, we will bias the review towards that.
When it comes to an AWS Review, it's important to keep in mind that these aren't intended as a one-time check. These reviews and best practice sessions should be run with regular cadence; twice a year is often sufficient to avoid any glaring holes, and for any holes that are found, we want to find them early. Its simple, regular cadence provides greater efficiency.
Well-Architected Lenses
The Well-Architected Lenses were created to be specific to workload type. While the same review over diverse workloads was positive, AWS wanted to allow more specificity and so over the coming years, more lenses will emerge into the Well-Architected tool itself.
The design principles are specific to each lens, and the lens documentation includes popular scenarios; for instance, the Serverless Lens includes restful APIs and mobile devices. There is also the High-Performance Review and a lens for IoT.
At its core, the lenses are there to enable maximum effect to work towards a customer's business outcome.
The Serverless Lens Design Principles
- Speedy, Simple, Singular
It's important that functions remain concise and single function in their nature. Customers are already moving away from the monolith design, however what's showing is Lambda code running in a tentacle manner. We don't want a Swiss army knife Lambda style!
- Concurrency
Making full use of the concurrency model is a trade-off made at the start. Remember that you don't need to look at the total number of requests.
- Share Nothing
Functions, by their nature, are short-lived and so, the underlying infrastructure isn't guaranteed. Instead, persistent storage with a decoupled nature is preferred for durable requirements.
- No Hardware Affinity
By using technology and hardware in an agnostic method means that code will work over a breadth of time.
- Orchestration
This is undoubtedly one of the key benefits of Serverless. Chaining functions together is akin to our standard monolith designs, so please be mindful and don't fall into that trap. AWS has state machine structures to build out the complex orchestration needed, so make full use of this.
With this in mind, combining functions that are precise means that you can build out those complex workflows much more easily.
- Event driven
A biggie in Serverless. Make use of this principle to ensure events and responses align with business functionality.
- Failures and Duplicates
Another major component in Serverless. Ensure that appropriate retries for downstream calls are included within your code.
Challenges for Serverless Teams
When it comes to Serverless, there is a lot of surface area, functions, and managed services making a complex environment to understand and navigate.
As a result of this, often a significant amount of time is spent on debugging, as opposed to building.
The ability to respond to incidents quickly and to have the confidence that you'll know of them before any customers find out and in real-time.
Continuing to follow best practices as other areas become a priority.
Some of the common issues are:
- How can I be sure I'm following them as I should?
- I want somebody to tell me what they are, and recommend how to be better!
How Can Tooling Help?
Observability
With such a large surface area and so much data moving around, observing your infrastructure is one of the hardest elements to keep up with. To make this easier, data should be centralized and made as accessible as possible.
It's incredibly important to not see logs, metrics, and traces in only silos, but instead to look across the spectrum of your managed services. Asking, how does your SQS queue interact with your Lambda functions?
Tooling also helps in reducing time to discovery and resolution. Good tooling tells you when something is wrong, what has gone wrong, and the best way to fix it. Through this, it naturally encourages best practices too making it the best way to automate all of the above.
Tooling for Serverless, particularly monitoring, security, alert and failure detection should come down to automation and abstraction.
Looking at Cognito and SQS queues, for a team to use SQS, they need to first implement them, and then understand the risks and monitor them. Once you start adding new queues and functions, that sort of alert coverage and monitoring for unknown failures must always be extended to the rest of the infrastructure.
It's important, therefore, that tooling constantly adjusts itself to the ever-changing infrastructure.
A bit of a no-brainer but so important to highlight is that tooling helps to manage underlying the infrastructure. The log pipeline and log ingesting can be managed, as can an alarm or alerting system. This really is the Serverless way!
As touched on before, it also enables learning. A good tool, such as Dashbird, makes it understandable and clear as to how the system has worked historically, and how the changes have affected the system to perform over time.
Achieving Well-Architected for Serverless with Dashbird

Three pillars of Dashbird
Single Pane of Glass for All Activity
Dashbird connects to your AWS account with read-only-permission and ingests all data across all managed services including logs, metrics, and traces. If anything happens in your infrastructure, there is just one place to see all the information, and you're able to view on an account level, detailed transaction, or execution level.
This one place means you can avoid going around looking for the relevant data and we see this as increased effectiveness to enable companies to build faster.
Automatic Detection
Dashbird will see everything in your logs that indicates failure or look at a metric's data point across any managed services showing higher delay or failure, which you will be automatically alerted of. The app will also tell you what you should be focused on so you don't have to manage this.
Well-Architected and Best Practice Insights
By looking at all data points of the system, we realized we can actually do a lot more abstraction and automation using the data we have already. It made sense then that Dashbird performed checks on how to improve architecture to follow best practices.
Psst, stay tuned, we have a big announcement coming out on Thursday 25 February. Intrigued? Sign up for the announcement and we'll send it straight to your inbox (no spam, we promise).
The Importance of Centralizing and Democratizing Monitoring Data
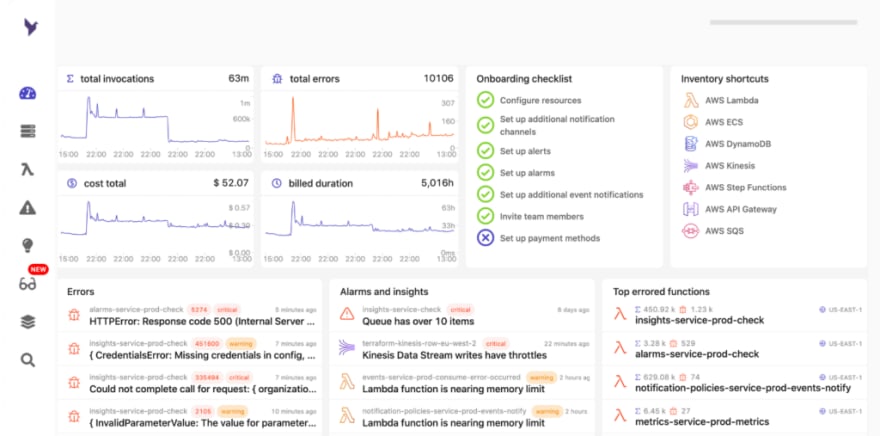
You should aim to have one managed, automatically scalable central place for all the data you have and need for your infrastructure and to have it as readily available and accessible as possible.
Dashbird is designed to give back development time, confidence, and understanding of the system, allowing you to search, query, visualize logs metrics, and traces. You can also go into the transaction level to see other services a function has interacted with, and see relevant cold starts, memory usage, and retries. Seeing this shows how retries are linked in time and if they were successful. Dashbird also offers this for a wider range of AWS services, not just functions.
Managed Failure Detection from Logs and Metrics
When you onboard, Dashbirs immediately starts discovering and ingesting data from your resources. For example, let's say you have 1000 Lambda functions; once connected to Dashbird, we will tell you the code exceptions, timeouts, configuration issues on all of them and act as an incident management platform. We also look at invocations and any underlying event to cause this, and the same goes for metrics too.
There is a broad variety of failure checks within Dashbird, including high delays in SQS or consuming items at a slower pace than they're entering the queue. These sorts of issues will be found in real-time, and again, work within other services looking at ECS clusters or Kinesis throttling for example.
Continuous Well-Architected Security and Cost Optimisation Insights
Currently, we have over 70 community curated Well-Architected checks, across a different variety of elements; risk of running into memory outage, over-provisioned resources, encrypting database requirements, or whether detailed monitoring is enabled or if logging is enabled.
We've ensured that we cover all five of the Well-Architected pillars and provide an actionable list of items showing you what incident affects your system in which pillar and to what extent.
Why Developers use Dashbird?
Dashbird increases reliability and iteration speed. Developers have said they're able to up to 80% work faster with the aid of Dashbird saying something is wrong and telling them the ins and outs of their system. It also helps in the development workflow.
At Dashbird, we understand that the core idea and value of serverless is to focus on the customer and the ability to avoid undifferentiated heavy lifting. That's what we provide. We give the focus back to developers to only think about the end-customer and to not be distracted by debugging and alarm management or to worry if something is working or not.
We also help users to achieve industry best practice, with an effect on cost optimization, performance-optimized and the overall management of the posture of your infrastructure.
This article was put together based on a Dashbird webinar with Tim Robinson, Well-Architected Framework's Geo Lead at AWS, and Taavi Rehemägi, CEO at Dashbird.

Top comments (0)