"tell me who your friends are and ill tell you who you are". That's the idea of which the k-nearest neighbor algorithm is based.
You can represent data in a vector space. This could be length (x) and weight (y), size(x) and price(y) or whatever you want.
Given a 2 dimensional space, it looks for the k nearest neighbors. Any point in the space can be part of a group/class. Meaning the closest points are likely to tell the class of a new point.
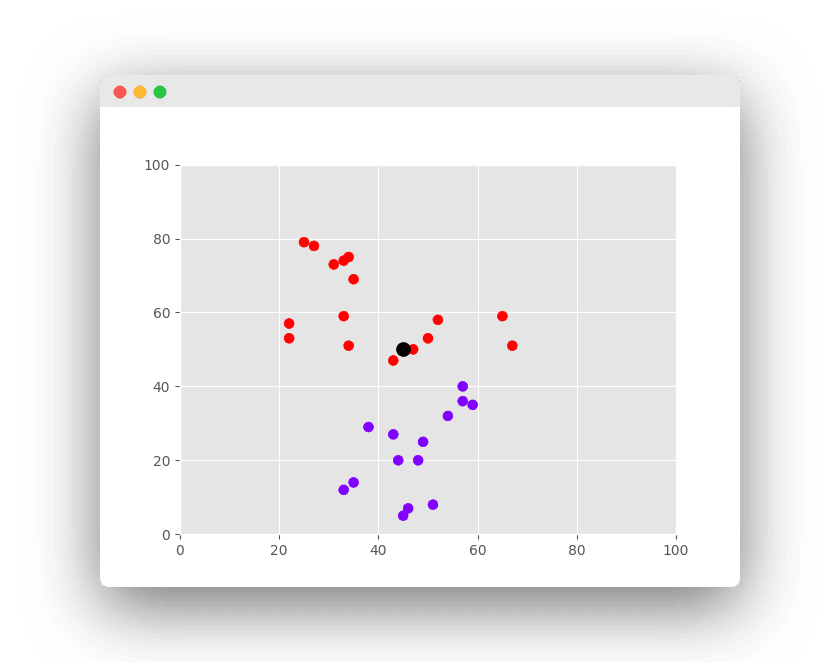
In the image above there is a red and blue group. The new black point is most likely to belong to the red group, as it is surrounded by red neighbors.
read more: k-nearest neighbors

Top comments (0)