In this article, we will see how to scrape medium blogs using node.js. Web Scraping Blogs Posts using Node.js
Recent Node.js article
Building P2P Video Chat Application using webRTC and Node.js
Apache Kafka for Node.js Developers
Set up
- Express - we will be using express to show the scrap results in the browser.
- Request - it is used to make API calls to medium blogs to get the data.
- Cheerio - it is used to manipulate the DOM in the response data from the URL. consider it just like JQuery.
- Handlebars - View engine to render the web pages in the express application.
Let's set up the project to scrape medium blogs. Create a Project directory.
$ mkdir nodescraper
$ cd nodescraper
$ npm init --yesInstall all the dependencies mentioned above.
$ npm install express request cheerio express-handlebarsGetting Blog posts from Medium
we will be scraping blog posts based on the tag of it. Medium provides a search bar where we can search for blogs based on tags.
we are going to use it to scrape all the blog posts for a particular tag.
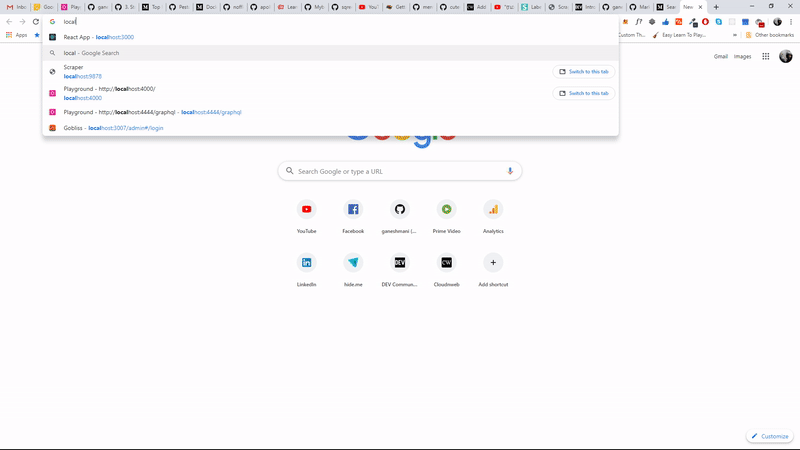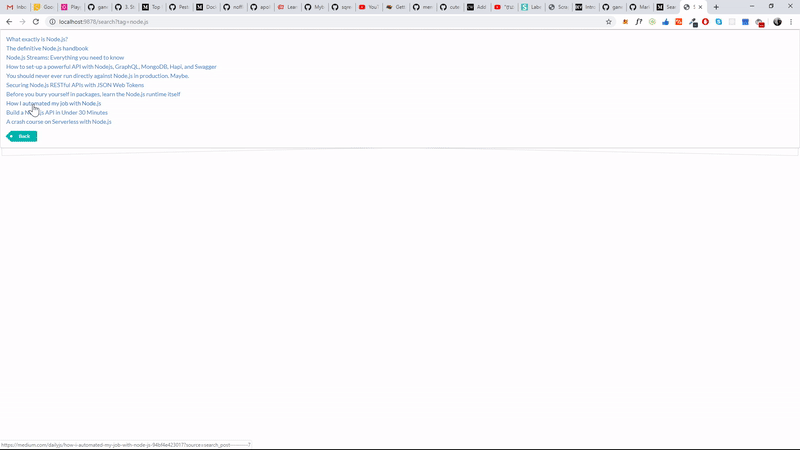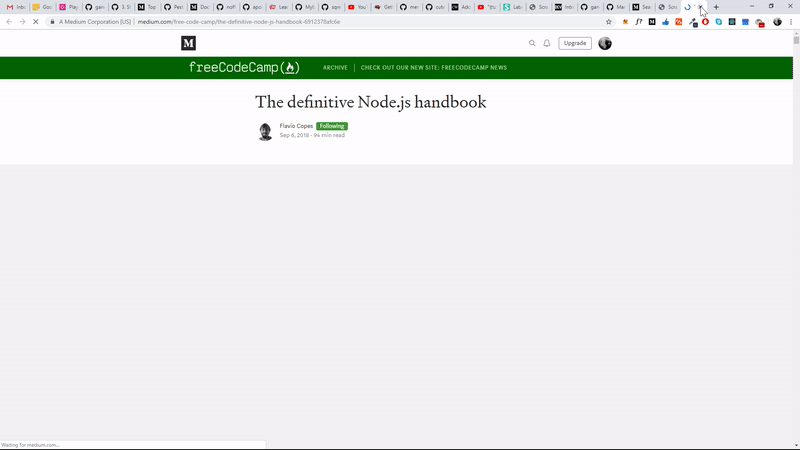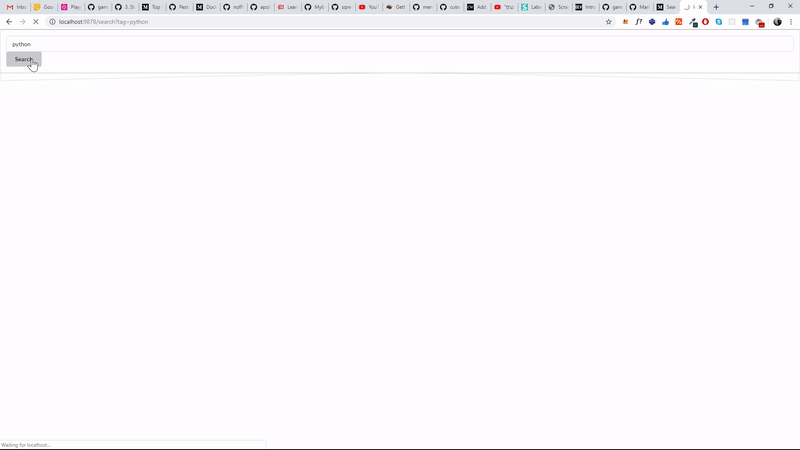
For Example, if you are going to scrape node.js blog post in the medium.you can search through the url https://medium.com/search?q=node.js .
After that, open the Inspector in chrom dev tools and see the DOM elements of it.
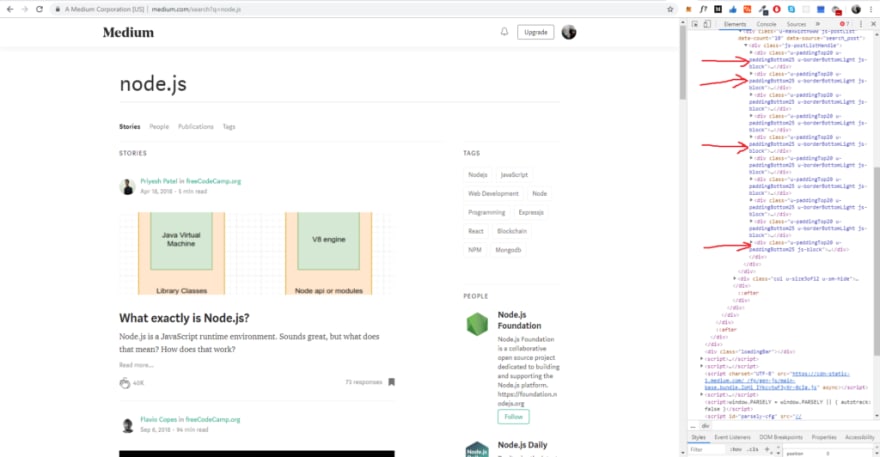
If you see it carefully, it has a pattern. we can scrap it using the element class names.
Firstly, get the webpage elements using request package.
request(`https://medium.com/search?q=${tag}`,(err,response,html) => {
//returns all elements of the webpage
});Once you get the data, load the data to cheerio to scrap the data that you need.
const $ = cheerio.load(html);This loads the data to the dollar variable. if you have used JQuery before, you know the reason why we are using $ here(Just to follow some old school naming convention).
Now, you can traverse through the DOM tree.
Since we need only the title and link for the blog posts on the page. we will get the elements in the HTML using either the class name of it or class name of the parent element.
Firstly, we need to get all the blogs DOM which has .js-block as a class name.
$('.js-block').each((i,el) => {
//This is the Class name for all blog posts DIV.
}); Most Importantly, each keyword loops through all the element which has the class name as js-block.
Secondly, we scrap the title and link of each blog posts.
$('.js-block').each((i,el) => {
const title = $(el).find('h3').text();
const article = $(el).find('.postArticle-content').find('a').attr('href');
let data = {
title,
article
}
console.log(data);
}) This will scrap the blogs posts for a given tag.
Meanwhile, we will wrap this functionality with express application which takes a tag name as input and returns blogs for the particular tag.
Complete Source code can be found here

Top comments (1)
Sure..i will update it