( This is a placeholder for my learning in the space of MLOps, updated almost daily, until I complete the course )
Intro
Generally, a machine learning engineer / modeler would start their project in a Jupyter notebook environment to create a model.
Machine learning does not end with creating a good model. ( with some good accuracy )
But, the focus is to put the model into production.
How do you deploy a machine learning model into production, so that, it can be used for making predictions, given some input data ?
What is MLOps ?
MLOps is a discipline of building and maintaining production machine learning applications, with the processes and tools.
Ponderings
Some of the ponderings/ questions we need to answer is:
- What goes into the lifecycle of a production machine learning application ?
- How will a model be deployed ?
- How will a model be updated in production, as and when it is tuned by the modelers, to improve accuracy ?
- What goes into testing the model ? Do we some integration tests, which run on machine learning models, just as we have them for normal software projects ?
Project Lifecycle of a production machine learning application
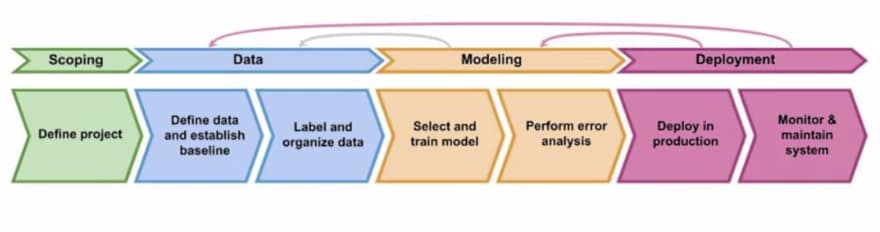
courtesy: Andrew Ng
What goes into the process of MLOps ?
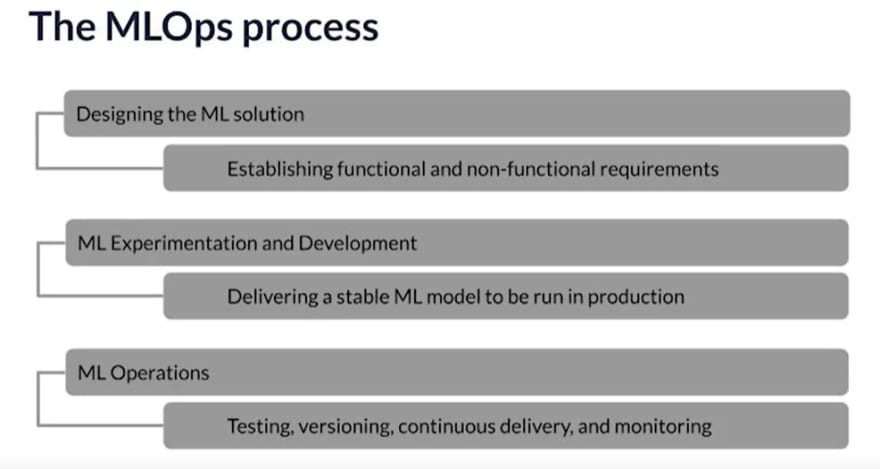
courtesy: Andrew Ng
Data drift
The machine learning model which you have developed in your lab would be trained on some data. Once you deploy this model into production, you might encounter several issues and one of them is data drift. What this means is that, the distribution of data which was used , during the time of training, will be very different from the distribution of data during inference. So, accordingly the model needs to be retrained, taking into account the data drift.
Importance of 'Production machine learning' knowledge
You might be working on a product which is performing some kind of inference in production. And this product operates continuously in production. So, the knowledge of modern software practices is very essential to maintain your product.
Model creation vs Model deployment & maintenance
The scenario of model creation will be way different from the scenario of model deployment. For example, during model deployment, there might be a case that, you deploy on smartphones. And the requirement from end users could be that, the data on their device, should never leave that device for privacy. Then the model deployment/maintenance should be such a way that, model on the smartphone/device is continuously updated/refreshed, whenever the model is updated/tuned.
The objective is to have a very good sense of entire lifecycle of a machine learning project.
Reality of machine learning projects
Let's assume that, our usecase is this. We have a manufacturing factory which makes smartphones. The job of machine learning system is to take pictures of the manufacturing assembly line containing the smartphone. And figure out, whether a smartphone is defective or not. If the smartphone is defective, then the inspection module will remove the smartphone from the assembly.
It starts with training the model. The final step is to put the model into a prediction server, by setting up API interfaces.
These API interfaces of prediction server could be hosted in the cloud. OR, we could have the edge deployment itself, where the API interfaces of prediction server is available within the factory itself, without relying on internet connection.
Within the lab/jupyter notebook, we might be able to train the model and check its accuracy, it might be very accurate on the testing dataset. But, in practice, in production deployment, based on the real world data, the model may not perform very well due to various reasons. One of the reason is data drift. In lab, we might be working with training dataset, where the lighting is good enough. But, for example, in a manufacturing factory, which could be a edge deployment, the lighting conditions might not be so good that, there might be some darker images, sent to the prediction server. And the prediction server might not do well on these kinds of images.
What about the amount of code involved in machine learning ? OR the amount of aspects to deal with, in machine learning projects ? We might assume that, we should be responsible just for the model code or just the algorithm. But, in reality, the ecosystem consists of several moving parts which enables the prediction. The entire infrastructure required for machine learning, will require various components for :
- Configuration
- Data collection
- Data verification
- Feature extraction
- Serving infrastructure
- ML model code
- Monitoring infrastructure
- Analysis tools
- Process management tools
- Machine resource management tools.
So, ML code is just 5-10% of the overall ecosystem.
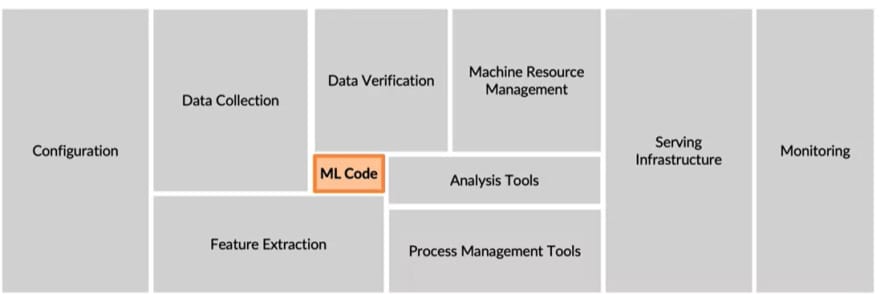
courtesy: Andrew Ng.
Learning continues....

Top comments (0)