(Heroku and Salesforce - From Idea to App, Part 3)
This is the third article documenting what I’ve learned from a series of 10 Trailhead Live video sessions on Modern App Development on Salesforce and Heroku. In these articles I’m walking you through how to combine Salesforce with Heroku to build an “eCars” app—a sales and service application for a fictitious electric car company (“Pulsar”) that allows users to customize and buy cars, service techs to view live diagnostic info from the car, and more. In case you missed my first article, you can find the link to it below and start from the beginning. Otherwise, if you’re specifically looking for data modeling, you’re in the right place.
Modern App Development on Salesforce and Heroku
Jumping Into Heroku Development
Just as a quick reminder: I’ve been following this Trailhead Live video series to brush up and stay current on the latest app development trends on these platforms that are key for my career and business. I’ll be sharing each step for building the app, what I’ve learned, and my thoughts from each session. These series reviews are both for my own edification as well as for others who might benefit from this content.
The Trailhead Live sessions and schedule can be found here:
https://trailhead.salesforce.com/live
The Trailhead Live sessions I’m writing about can also be found at the links below:
https://trailhead.salesforce.com/live/videos/a2r3k000001n2Jj/modern-app-development-on-salesforce
https://www.youtube.com/playlist?list=PLgIMQe2PKPSK7myo5smEv2ZtHbnn7HyHI
On the last episode…
Last session, we walked through Heroku buildpacks and learned how to start building on Heroku with a particular web language. The buildpacks were nicely structured, with intuitive instructions and installation steps for getting Heroku and your local machine set up to develop on one of the supported languages. We also ran through the process of using the command line, VS Code, and specific Heroku git commands to deploy a sample Lightning Web Components (LWC) app to a new Heroku app environment. Not bad for under an hour’s work!
In this episode, we’re going to get into the bones of any modern application: the data layer.
One of the things I find funny about data modeling is that almost everybody does it in their regular work, but rarely do people think too deeply about it (unless they’re developers or DBAs). There’s also a really steep learning curve when you graduate from a flat file like Excel to a multi-table relational database like Access. Every client I talk to can describe, to a degree, what kind of data their business needs to track. But going beyond that—initiating the right conversations with clients, reading between the lines, and teasing out the best data model of their application—is somewhat of an art form. Data modeling also seems to be a bit of an underappreciated part of the application-building process. Speaking from experience, getting the data model right or wrong for an application can mean the difference between a smoothly performing app that generates useful, insightful data and an app that gets “spaghettified” with workarounds and code to make up for the data modeling missteps made at the outset.

A lot harder when you’re already a few million rows down the data rabbit hole!
Data Modeling in Salesforce Using Point-and-Click Methods
As we dive into our data modeling for the eCars app, there are two things worth noting about Salesforce’s data modeling features:
- Standard Objects establish a data model right out of the gate for Salesforce applications.
- Custom Objects and Custom Fields provide the ability to rapidly extend and prototype additional data requirements for any application.
They also touch on Big Objects and External Objects, but in my experience, these rarely come into play except for enterprise-level implementations that have large data sets and external data sources. For the most part, Standard and Custom Objects covers 80% or more of the use cases in my experience.
One major Salesforce data-modeling feature that requires experience and attentiveness is its attached dependencies and automatically generated metadata components. Many “freebies” and metadata dependencies come attached (i.e. conveniently created for you) to the custom objects, fields, and relationships that one creates in the system. For example, when you create custom objects and fields, the system already allows you to set and handle some things conveniently like creating a tab, default list views, page layouts, reports, and the security model down to the field level.
Creating a relationship field, such as a lookup or master-detail relationship, also conveniently renders the child object (i.e. the table on the “many” side of a one-to-many relationship) as a related list on the parent object’s record page so that navigation is easy and intuitive. Some key things to know about the two different relationship fields are below and also demonstrates the kinds of “freebies” or metadata dependencies that are generated with each type (rollups, sharing rules, etc.).

This all results in the ability to immediately interact with and prove out your data model in your app and make tweaks and adjustments quickly. I can’t count how many times this has come in handy when working with clients on the initial vision of their apps. Instead of having to create ERDs and work up the data model before putting pencil to paper, we can just go directly to prototyping in real-time. Plus, the Schema Builder conveniently draws out the ERD as the data model is built out. You’ll also see in the video that it’s possible to build out the data model visually directly on the Schema Builder!
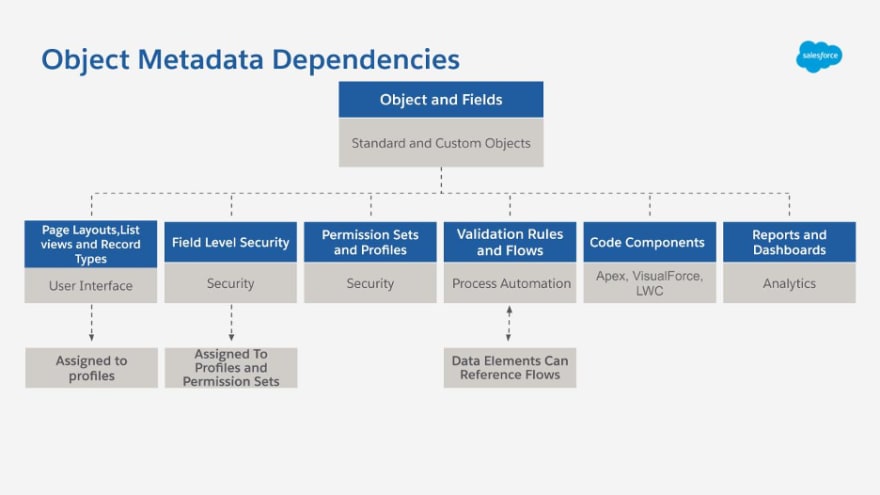
Pretty nice when the data model comes with these freebies as it’s being built out
Building the eCars Data Model
By using the point-and-click data modeling features of Salesforce, we should be able to build out the entire eCars data model in under 20 minutes. The screengrab from the Salesforce Schema Builder tool below shows us the different tables/objects that are part of the app, how they’re related to each other (they’re all Lookup relationships here, no Master-Detail relationships so far) and which fields are required or automatically generated upon record creation.

A written interpretation of the data model’s relationships could be as follows:
- A car can have zero, one, or more Configurations.
- Each configuration can have zero, one, or more Car Options.
- A Vehicle Order can act as a parent and/or child for a Configuration and vice versa.
- A Lead can be related to zero, one, or more Configurations. (The data model implies that a Lead can be interested in multiple Configurations.)
Understanding what limitations and implications a data model conveys is one of the key skills in app development I’ve grown to appreciate.
Heroku Data Services
Data modeling on Heroku, on the other hand, follows some of the more traditional tools you might expect with SQL databases. Still, there are several GUI tools to help as well, which I’ll mention later. Heroku also features several important add-ons for scalability.
The four major data services we’ll focus on for the eCars app are:
- Heroku Postgres (primary relational database)
- Heroku Redis (in-memory key-value data store)
- Apache Kafka (distributed streaming platform)
- Heroku Connect (Connect Salesforce Data and Heroku Postgres)
Let’s look at each of those to see how we’ll use them.
For Heroku, while other 3rd-party databases are available in the Elements marketplace, the officially supported database of choice is Heroku Postgres and is appropriately the most popular Heroku add-on. Heroku, like Salesforce, allows you to create your data model on Postgres using both command-line methods such as in VS Code as well as through a UI via the Heroku application manager. I’ve also used pgAdmin to manage Postgres databases as well and have used it in conjunction with Heroku Postgres databases. I don’t know any people who purely live in the command-line when it comes to databases, but I’m willing to bet they’re pretty fast on the keys!
For the eCars app, we’ll use Postgres to store our basic relational data—customer information, car information, etc.
This is actually my first exposure to Redis and Kafka. However, after Julián explained the use cases for each, I can see how these are very important data services for highly scalable applications. Scalability seems to be more and more of a recurring theme for Heroku also.
Modern applications have to run lightning fast as consumers have come to expect that kind of performance. And even though solid-state drives might improve performance, the reality is that on-disk databases are just not going to be as fast as in-memory data. So, to get high-volume apps running super fast, you can see why you need something like Heroku Redis or Salesforce Platform Cache to store some of the higher-volume information that powers the app in fast, high-performance memory. Otherwise, the database would buckle under the number of requests.
On top of that, modern applications typically run on distributed cloud infrastructure and may be using multiple data sources which need a lot of real-time throughput. In front of the data sources are a collection of services, and we need a way to reliably and quickly pass messages among them. Apache Kafka on Heroku fits the bill for this requirement, especially in large enterprise applications. Apache Kafka is an event-streaming platform that will allow our eCars app to potentially scale to very high loads in a distributed app architecture. It also makes sense that there isn’t a free tier for this service, as I can imagine the expense it takes just to run one Kafka cluster.
Finally, Heroku Connect allows Salesforce data to connect with Heroku Postgres in a bi-directional manner with a quick set-up. This saves us from having to do a custom integration between Salesforce and Heroku Postgres, but usually the deciding factor is the cost. Using Heroku Connect will allow us to seamlessly and easily connect Salesforce data to Heroku Postgres in a bi-directional fashion in near real-time.
One thing I’d like to clarify (since it used to confuse me) is the difference between Heroku Connect and Heroku External Objects. While Heroku Connect works with Salesforce standard and custom objects, Heroku External Objects is strictly a uni-directional OData service, meant to allow Heroku Postgres tables to sync to Salesforce External Objects. The naming can get confusing, so it’s important to keep this nuance in mind. Heroku External Objects also comes with the Heroku Postgres add-on while Heroku Connect is a paid service.
Concluding Thoughts
That’s an overview of data modeling on both Salesforce and Heroku, and how we’ll get them to work together.
As I mentioned previously, I’m of the opinion that getting the data model right is probably one of the most important things when it comes to designing applications. If it goes wrong, everything can turn into a futile exercise, from the way data is collected to what the business intelligence/analytics tools produce.
I got introduced to this mode of thinking pretty early on, before I even started my career. A USC Marshall Business School instructor named Douglas Shook taught a database class to business students like me. I still credit that class, its data-modeling lessons, and the bit of SQL it taught us, with my eventual pursuit of Salesforce as my career. We did countless homework problems and quizzes where he would give the class a bunch of receipts and a report from a shoe store or something, and then ask us to draw an ERD for a possible database system that generated them. When I reflect on that experience, I definitely have some renewed appreciation for how Salesforce and Heroku make it simple to handle the data aspects of an app now.
If you want to take a deeper dive into data modeling considerations, I recommend taking a look at this article that Mohith wrote on Data Model Design Considerations When Building Salesforce Apps.
In the next article, we’re going to look at how we can customize the front-end UI components of Salesforce for our eCars app, all without writing any code.
If you haven’t already joined the official Chatter group for this series, I certainly recommend you do so. That way, you can get the full value of the experience and also pose questions and start discussions with the group. Oftentimes, there are valuable discussions and additional references available there such as the slides from the presentation.
About me: I’m an 11x certified Salesforce professional who’s been running my own Salesforce consultancy for several years. If you’re curious about my backstory on accidentally turning into a developer and even competing on stage on a quiz show at one of the Salesforce conventions, you can read this article I wrote for the Salesforce blog a few years ago.

Top comments (1)
"Near real time" is doing a lot of heavy lifting in the Heroku Connect description. In practice its polling based, so you're looking at 2 to 10 minute sync intervals depending on the edition. For the eCars inventory use case thats probably fine, but the moment you need live diagnostic data from vehicles hitting Postgres in real time, that gap becomes visible to users.
The cost point is also worth revisiting. Heroku Connect's pricing scales with row count, and the eCars data model has several objects that could grow fast. We hit this exact tradeoff at Stacksync.
At what data volume does the Connect cost start competing with a custom integration in your experience?