
Intro
I know I'm late to the party, but just recently had the opportunity to start using nullable reference types more seriously, so thought of gathering the first steps taken to go all-in with it.
To avoid writing nullable reference types a million times, I'll often abbreviate to NRTs throughout the post.
Enable nullable reference types
Nullable reference types are considered a breaking change, they are disabled by default to avoid annoying folks out of nowhere. As we enable them we're saying we're tired of NullReferenceExceptions and need all the help we can get 🙂.
Enabling is easy, as it's just a matter of going to our projects csproj file (or Directory.Build.propsif we want to simplify applying these settings to multiple projects) and add <Nullable>enable</Nullable>.
An example project file would be:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net5.0</TargetFramework>
<Nullable>enable</Nullable>
</PropertyGroup>
</Project>
The enable value enables all the features, but there are alternative values, namely warnings, annotations and disable. As I want to take as much advantage of NRTs as possible, I'll go with enable to have all the features. More details about the rest in the docs.
With things enabled, we now get warnings if, for example, we try to assign a null value to a string variable that's not marked as nullable (with a ? suffix):

Treat related warnings as errors
Enabling nullable reference types and starting to get warnings is a good start, but if we're "going all-in", it's not enough!
Warnings are too easy to ignore, so I want errors instead. Of course we could still escape them with a pragma disable or using the "damnit operator", but if in a PR I see a ! without a clear reason or a comment explaining why it's there, be sure I'll ask 🙂.
Treating warnings as errors is not something specific to NRTs, but as it's something I did it in this context, might as well go through a few ways of doing it.
Some of our options:
- Code analysis rule set
- EditorConfig file
-
WarningsAsErrorselement incsprojorDirectory.Build.props
Code analysis rule set
A code analysis rule set is what I've been using lately. Recently discovered a simpler alternative for the specific NRTs case (which I'll share in a minute), but it's still worth a mention.
Note: got the idea for this approach from this Cezary Piątek blog post, so won't go into many details, you can read his great post 🙂.
In summary, in Visual Studio we can create a "Code Analysis Rule Set". When we open the file we get a list of rules and their severity, which we can change as we choose.

As you can see in the image, we can even search for the rule text, so in this case I search for "null", to try and find all the rules related with NRTs.
A ruleset file is just an XML file, so if we know the rule ids, we can edit it directly.
<?xml version="1.0" encoding="utf-8"?>
<RuleSet Name="New Rule Set" Description=" " ToolsVersion="16.0">
<Rules AnalyzerId="Microsoft.CodeAnalysis.CSharp" RuleNamespace="Microsoft.CodeAnalysis.CSharp">
<Rule Id="CS8600" Action="Error" />
<Rule Id="CS8601" Action="Error" />
</Rules>
</RuleSet>
Then to have the rules apply, we need to reference the ruleset from csproj or Directory.Build.props. The previously shown csproj would become:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net5.0</TargetFramework>
<Nullable>enable</Nullable>
<CodeAnalysisRuleSet>$(MSBuildThisFileDirectory)RuleSet1.ruleset</CodeAnalysisRuleSet>
</PropertyGroup>
</Project>
Note that I only touched a couple of the rules, which doesn't cover everything. Again, Cezary Piątek's blog post contains a list of relevant rules, but you could also take a look around in the rule set editor and see if there are more interesting rules you might want to change the severity.
EditorConfig file
An alternative to the rule set, a bit given away by the warning at the top of the previous rule set editor image, is using an EditorConfig file.
An EditorConfig file is useful for more things, namely describing coding styles that should be respected for a given project, but it can also be used to configure the severity of the rules.
Clicking the warning Visual Studio creates a .editorconfig file with the following content:
# NOTE: Requires **VS2019 16.3** or later
# New Rule Set
# Description:
# Code files
[*.{cs,vb}]
dotnet_diagnostic.CS8600.severity = error
dotnet_diagnostic.CS8601.severity = error
The relevant part of our use case are the lines where the severity is set for rule with id CS8600. These lines follow the format dotnet_diagnostic.<rule ID>.severity = <severity>. There are also formats to set severity for a category of rules or all rules for a given analyzer, more details in the docs.
WarningsAsErrors element in csproj or Directory.Build.props
Yet another option to treat warnings as errors is using the WarningsAsErrors element in csproj or Directory.Build.props.
Following the same approach as in the previous sections, just adapted for this WarningsAsErrors element, we'd have a csproj as follows:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net5.0</TargetFramework>
<Nullable>enable</Nullable>
<WarningsAsErrors>CS8600;CS8601</WarningsAsErrors>
</PropertyGroup>
</Project>
There is another way to use this WarningsAsErrors element though, making things much easier. Instead of listing all the nullable related rule ids in there, we can do <WarningsAsErrors>nullable</WarningsAsErrors>. Now this is much better! 😀
Regardless of which of these approaches we go with, we should now see an error instead of a warning (noted by the red squiggles), so we need to handle it.

Less null checks and guard clauses, but still some
The goal of using nullable reference types is to be more confident that our code won't go kaboom with a NullReferenceException out of nowhere, as the compiler will be checking if the code and types involved are respecting the rules, information we didn't really have before.
Having this extra confidence and guidance from the compiler means we can reduce the usage of null checks and guard clauses throughout our code, but unfortunately not get completely rid of.
When types are appended with the ?, meaning it should be null, it should go without saying that we need to do the check, but even cases where there's no ? might need the check.
Code under our control, within the NRTs context is the one that gives us the most confidence, where normally the only way we should get an exception is if we use the null-forgiving (or similar error disabling strategy) wrongly. Now at the edges is where troubles come from.
I call "edges" to the the places where our code interacts with what's outside our NRTs context. An example of edge is getting an HTTP request, where the client might have not correctly created the payload, sending null for a property that cannot be null.
While this is a clear edge, as an HTTP request is something that's even outside our application's process boundaries, there are less immediately noticeable edges, like libraries, either as a consumer or producer.
If we're using a library that's not updated to take advantage of NRTs, the compiler will be oblivious and just not warn us at all, so we need to do the required checks, as if we also weren't using NRTs.
If we're developing a library, it might be used by a client that's not using this new feature (or maybe has it enabled but is ignoring the warnings 🤪), so we need to sanitize all the inputs.
Even with these gotchas, we should still get benefits from this feature, we just need to remember to correctly handle the edges and ensure that from the entry point onwards we have things tidy. If that's the case, the rest of our code should become simpler and less polluted with null checks and guard clauses.
Help the compiler help you
As we setup things and start using nullable reference types, there might be situations where we notice we either do checks that shouldn't be needed, as we know the thing isn't null, or we use the null-forgiving operator, which even if we know we're doing the right thing, still feels a bit dirty 😅.
As an example, let's imagine we create an extension method on string to get the first three letters, but as we're careful, we consider that a string might be smaller than that, so we use the popular C# Try* pattern. The method would look something like this:
public static bool TryGetFirstThreeLetters(
this string someValue,
out string? firstThreeLetters)
{
if(someValue.Length >= 3)
{
firstThreeLetters = someValue.Substring(0, 3);
return true;
}
firstThreeLetters = null;
return false;
}
At first glance, it looks ok, we're checking the size (no null check as it's not string?) and returning accordingly.
Now the problem arises when we use this method:
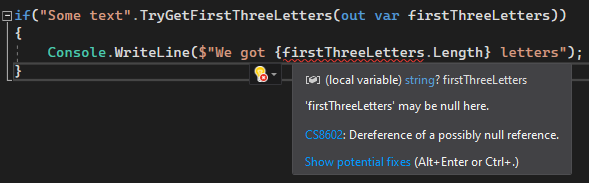
As we can see in the image, we get an error because we're using the firstThreeLetters variable without checking if it's null, which we know it isn't because the method returned true. We could use the null-forgiving operator, but it's a bit annoying to do so in such scenarios.
Fortunately, the C# team thought about this and much more, so we have a bunch of attributes we can use to help the compiler help us (more details in the docs).
For this specific case, we can use the NotNullWhen attribute, which gets a bool value as parameter, indicating that if the method returns a value that matches it, then the annotated parameter won't be null, even if it is a nullable reference type.
The method's signature would now look like this:
public static bool TryGetFirstThreeLetters(
this string someValue,
[NotNullWhen(true)] out string? firstThreeLetters)
And when we use it, we now have no compiler errors:

Be sure to check out the docs, as this is just one example, but it illustrates that we have ways to keeps things simpler, without being forced into null checks and ! everywhere (although there we certainly be such cases as well).
Outro
That does it for this quick look at some first steps to work with nullable reference types. We looked at:
- How to enable NRTs
- Treating warnings as errors to really make us respect the constraints
- Remembering there are edges where the compiler is flying blind
- Attributes that provide additional information to the compiler
Again, I know I'm late to the party, as it began last year, but hopefully these first steps are useful for folks who join the party even later 🙂.
Links in the post:

Top comments (0)