This is a Plain English Papers summary of a research paper called AI Breakthrough: New Training Method Makes Language Models Better Team Players with 46% Performance Boost. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
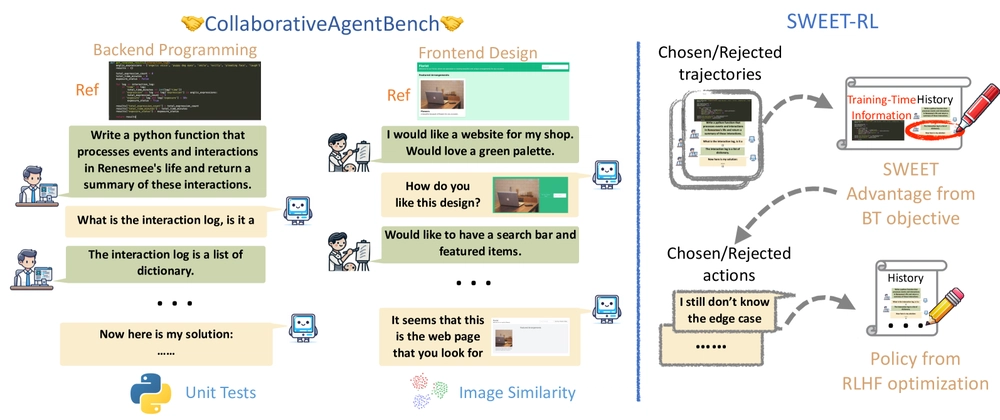
- SWEET-RL is a reinforcement learning framework for training LLM agents on multi-turn collaborative reasoning tasks
- Introduces ColBench, a benchmark of six collaborative reasoning tasks
- Uses Self-play With Evolving External Teachers (SWEET) methodology
- Achieves up to 46% performance improvement over base models
- Trained agents show better temporal reasoning and decision-making
- Demonstrates generalization to new tasks and improved human collaboration
Plain English Explanation
Training AI to work well with humans over multiple exchanges is challenging. Most AI systems today are designed to respond to one-off questions, but real collaboration requires back-and-forth conversation, careful reasoning, and teamwork.
The researchers behind SWEET-RL develo...

Top comments (0)