This is a Plain English Papers summary of a research paper called AI Model Learns to Balance Visual and Language Processing for Better Performance. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
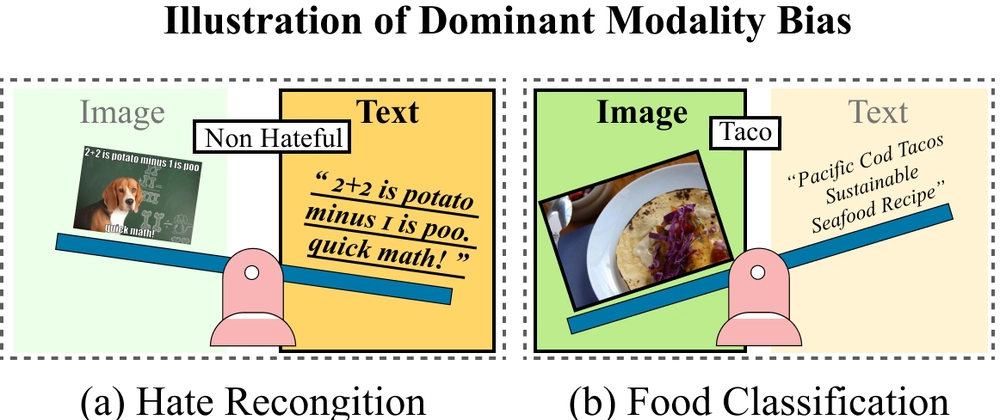
- Vision-Language Models (VLMs) often develop modality bias where they favor either visual or textual information
- See-Saw Modality Balance method identifies and corrects these imbalances during training
- Introduces Gradient Signal Preservation to prevent loss of important features
- Creates Dominant Modality Score to quantify and track bias during training
- Improves model performance on VL tasks by 2.3-4.5% across multiple benchmarks
Plain English Explanation
When we train AI models to understand both images and text, they often develop a preference for one type of information over the other. It's like a child who pays more attention to pictures in a book while ignoring the words, or vice versa. This imbalance can make the AI less e...

Top comments (0)