This is a Plain English Papers summary of a research paper called AI Models Struggle with Scientific Reasoning in Long Documents, New Benchmark Shows. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
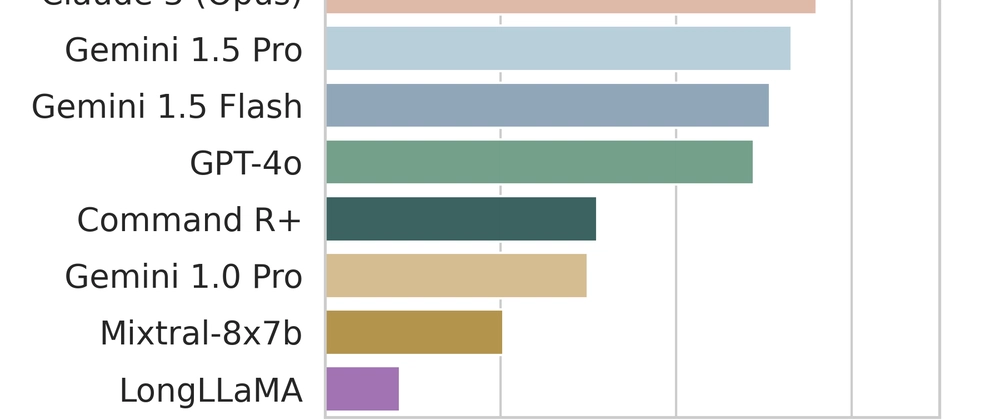
- CURIE is a new benchmark for evaluating large language models (LLMs) on scientific reasoning with long contexts
- Tests 8 different reasoning tasks across multiple scientific disciplines
- Contains 1,280 test examples with context lengths up to 128,000 tokens
- Evaluates 10 different LLMs including Claude 3, GPT-4, and Llama 3
- Performance improves with newer, larger models but still falls short of human experts
Plain English Explanation
CURIE represents a significant step forward in how we test AI systems' ability to understand scientific content. Think of it as a comprehensive exam for LLMs that specifically focuses on their ability to work with long scientific papers and documents.
Current LLMs face a chall...

Top comments (0)