This is a Plain English Papers summary of a research paper called Breakthrough AI Model Creates Ultra-Realistic Videos by Processing All Frames at Once. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
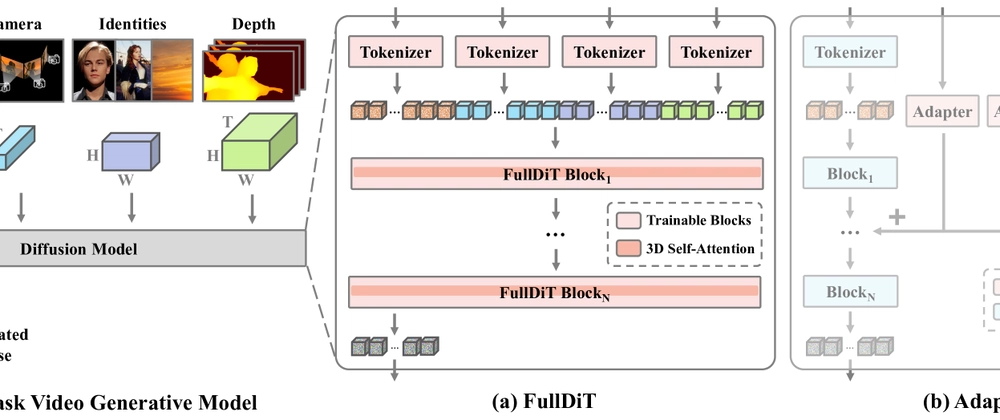
- FullDiT is a multi-task video generative foundation model using full attention across both space and time
- Processes entire video sequences simultaneously rather than frame-by-frame
- Achieves state-of-the-art results in text-to-video, image-to-video, and video inpainting
- Uses hierarchical attention for efficiency while maintaining performance
- Trains on a mixture of synthetic and real video data
- Demonstrates superior temporal consistency compared to prior models
Plain English Explanation
Imagine you're trying to tell a story with a series of images. The traditional way would be to draw each frame separately, then flip through them to create motion. But what if you could see all frames at once while drawing, ensuring everything flows perfectly? This is what Full...

Top comments (0)