This is a Plain English Papers summary of a research paper called New AI Model Runs 3x Faster by Learning Which Words Matter Most When Processing Text. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
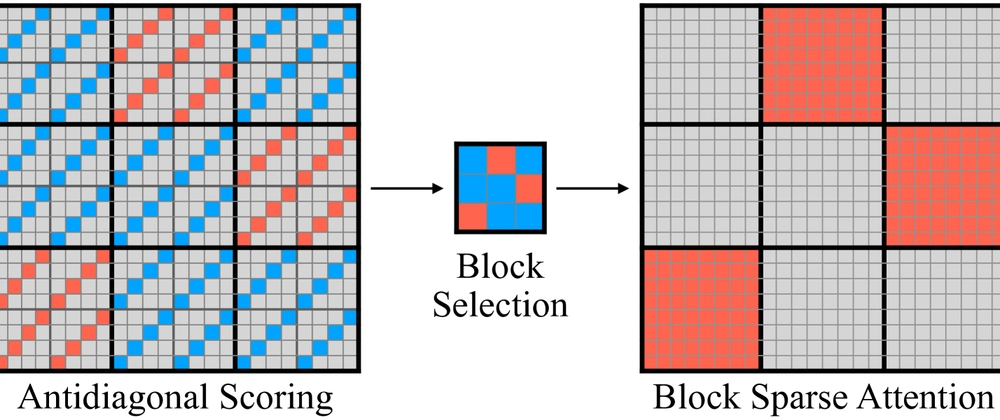
- XAttention proposes a novel way to handle attention in long sequences
- Uses block-sparse patterns with antidiagonal importance scoring
- Achieves 2-3x speedup with minimal quality loss
- Automatically identifies important token relationships without manual heuristics
- Outperforms other sparsity methods in language modeling and LLM inference
Plain English Explanation
Imagine trying to read a massive book while only being allowed to focus on a small portion at a time. That's the challenge large language models face when processing long texts. The "attention" mechanism, which helps these models understand relationships between words, becomes ...

Top comments (0)