Getting too much data than what is needed, getting less data than we want, querying multiple endpoints for required data. These are some of the things we have to accept when working with RestAPIs. Almost anyone who has worked with databases has experienced this.
But GraphQL is different. Writing a single query is enough to give us the data we want. Here are some of the points that make GraphQL queries more efficient and intuitive -
- Nesting related data
- Getting the data we ask for, nothing more, nothing less
- Defining the shape of the query result with our queries
So what does a GraphQL query look like? How do you determine what the structure of the query result will be regardless of how the data is fetched? Do you really get what you ask for without anything extra? Let's find out.
Is GraphQL different from a database?
GraphQL is indeed different from databases like SQLite, MongoDB, and Firebase. It is a query language for APIs. While databases store data, GraphQL can help us fetch that data more efficiently. What makes GraphQL different from usual methods of fetching data is the amount of control we have.
Generally, we send a request to the database or the server asking for the required data. Even though the data might be organized in tables (like in SQLite) or some other format (like Firebase, where each data entry is a document), most of the time, we get more than what we may require. So it now comes to us to sift through that data and look for what we need.
An example
Here's a simple example from Firebase. Let's say you have a database with a collection of cities. Each city is a document inside that collection containing the name of the city and other information like the temperature, population, etc.
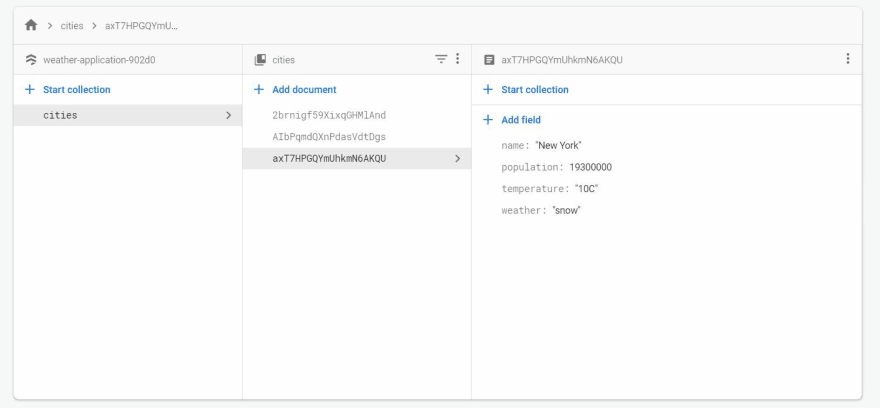
You only want the temperature of a particular city. So, you write a query with the name of the city as a condition. Firebase gives you the document where the city's name is the one you specified and then you extract the temperature of the city from the result Firebase gave you. This process might look something like this -

At first glance, this is a regular query giving us what we asked for. But what about that extra information that comes along with the temperature? Can GraphQL do a better job?
The GraphQL way
To get the same data, with GraphQL, we first have to define a schema -

This is a GraphQL schema. It tells GraphQL what a possible query might be and anything related it needs to know regarding that query.
Here, we have defined a possible query called city which will have an argument. This argument will be the name of the city we want to fetch data for. This city query will return a data type of City. We have also defined what this City data type looks like and the various fields it includes. Now we can write a query -

That's it! This is all we need and GraphQL gives us exactly what we asked for in the same format -

We have exactly what we need. No extra information, no need to invoke a chain of object properties to get the data we want.
Of course, behind the scenes, we still have to actually fetch the data from Firebase. And the way this data is fetched is the same as what we did before. So, what's the difference?
The most notable difference is the query size and refactoring time. This is what makes GraphQL so efficient to work with. The GraphQL query when compared to the Firebase code we wrote before is quite small. Adding new queries or refactoring existing ones also requires less time.
Fetching new data requires you to consider where and how the data is nested or you may have to fetch it from a different endpoint. With GraphQL, all you need to consider is how the new data relates to the current query.
After fetching the temperature of a specific city from a group of cities, if you want to fetch the details of a user living in that city, no need to write a different query:

Even though the user's data might be in a different collection, our query does not require any major changes.
Wrapping up
Ultimately, when we actually fetch the data from a database, GraphQL is no different from RestAPIs. The advantage with using GraphQL however comes with where this data fetching occurs.
Using RestAPIs, we need to change our queries and possibly refactor code when the required data changes. When using GraphQL, we define what to fetch, how to fetch it, where to fetch it from and GraphQL takes care of the rest. Essentially, after we tell GraphQL how to fetch data we get the data we want in the required form with queries.
The data fetching process is already defined, all we have to change are the queries. This makes GraphQL better to work with than RestAPIs in some situations.
Does this mean you're better off using GraphQL than RestAPIs? Not at all. Both have their own pros and cons depending on where they are used. The choice you make between either should be based on what your project needs. If you need caching on requests, ... then RestAPIs will suit your needs better.
GraphQL can do much more than simply fetch data from databases. The official documentation is worth reading to know more. If you want to learn how to implement GraphQL in the language you want, here is a series of tutorials from Prisma.

Top comments (0)