
This article is part of a series on “Testing Serverless Applications” based on lessons I’m teaching in the Serverless Testing Workshop.
In the last article, we covered the three core goals driving why we write automated tests and the trade-offs that we need to make in order to reach satisfactory levels of confidence, maintainability and feedback loop speed.
You may have been left wondering "how do I get to a sufficient level of confidence?". A typical answer to this could be along the lines of: "write a load of unit tests and aim for as close to 100% code coverage as possible".
And while unit tests and automated code coverage measurement can be part of building up confidence in your serverless system, in my experience they are a small part.
In this article, I'll argue that you should favour integration and end-to-end (E2E) tests for maximising the confidence delivered by your automated test suite.
What can go wrong?
Before deciding what tests to write for a given use case, we need to first understand our failure modes. A failure mode is a specific way in which a system-under-test can fail, and it can have any number of root causes. If we know what these modes are, then we can write tests to "cover" as many of the failure modes as is feasible.
Aside: There are many failure modes for which we shouldn't write automated tests that run in pre-production environments as they're too costly/difficult to simulate in a test. For these we can instead employ testing in production techniques to detect.
Let's illustrate this with an example...
Consider the Simple Web Service pattern from Jeremy Daly's excellent collection of Serverless microservice patterns (that I must've now referenced about 5,932 times in previous articles):

This pattern is by far the most common in serverless applications that I've built and involves a synchronous request-response cycle from API Gateway thru a single-purpose Lambda function thru DynamoDB and back again.
Let's make our example more concrete and say that we're adding a new REST API endpoint for a sports club management app that allows managers to create a new club: POST /clubs.
So what could go wrong here? What tests should we write? Let's look at the deployment landscape for this use case to help answer these:

The light red boxes depict source areas made up of code or configuration that we (as the developer) write and which are then deployed to a target environment.
Each source area can be a cause of several failure modes. Let's look through each in turn:
-
API GW Method config:
- Path or method configured incorrectly (e.g. wrong case for path parameter)
- Missing or incorrect CORS
- Missing or incorrect Authorizer
-
API GW to Lambda integration config:
- IAM permission for APIGW to call Lambda function
- Misconfigured reference to Lambda function
-
Lambda execution config:
- Insufficient memory allocated
- Timeout too low
-
Handler function code:
- Business logic bug, e.g. client request validated incorrectly or user incorrectly authorized
- Incorrect mapping of in-memory object fields to DynamoDB item attributes (e.g. compound fields used for GSI index fields in single table designs)
-
Lambda to DDB integration config:
- Incorrect IAM permissions for Lambda function role to make request to DynamoDB
- Incorrect name/ARN of DynamoDB table
-
DynamoDB table config
- Incorrect field name or type given for hash or sort keys of a table or GSI when table was provisioned
Covering these failure modes with tests
If you look through each failure listed above, very few of them can be covered by standard in-memory unit tests. They're predominantly integration configuration concerns.
The diagram below shows the coverage scope and System-under-test (SUT) entrypoint for each of the three test granularities (unit, integration and E2E):
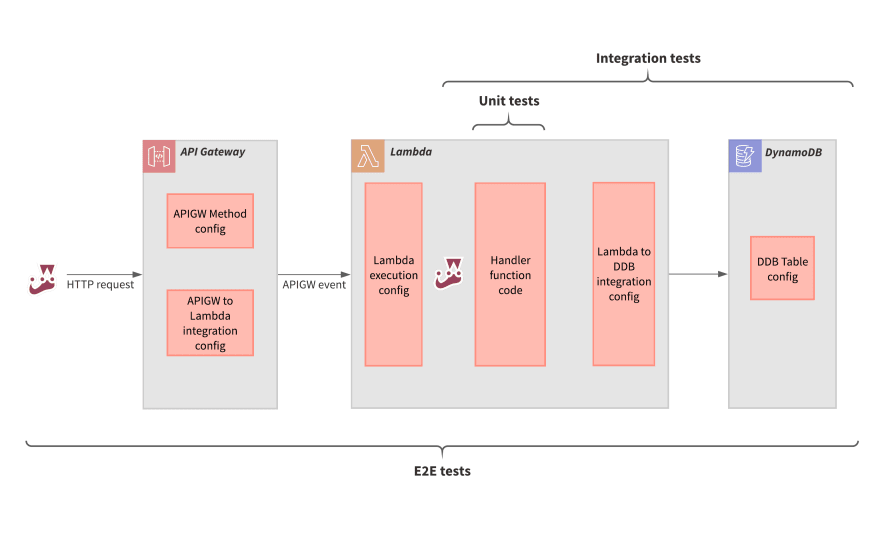
An important point for this particular use case is that each test level covers everything that the level below covers, i.e. integration tests will cover everything that unit tests do and E2E tests will cover everything that integration tests do.
So then why not only write E2E tests? Let's look at the key properties of each type of test for our example use case to see what they have to offer:
- Unit tests:
- Test and Lambda handler code execute on local machine
- SUT entrypoint could either be the Lambda handler function or modules used within the handler
- No deployment required — uses test doubles to stub out calls to DynamoDB
- Can use automated code coverage tools
- Integration tests:
- Test and Lambda handler code execute on local machine
- SUT entrypoint is typically the Lambda handler function
- Requires partially deployed environment (DynamoDB table)
- Can use automated code coverage tools
- E2E tests:
- Only test code runs on local machine
- SUT entrypoint is the APIGW endpoint in the cloud which receives a HTTP request from our test
- Requires fully deployed environment (APIGW resources, Lambda function, IAM roles and DynamoDB table)
- Cannot use automated code coverage tools
The key benefit that integration tests give over E2E tests is that they allow for much faster iterative development. Their deployment overhead is low (one-off provisioning of a DynamoDB table) whereas E2E tests require deploying the most frequently changing areas (the handler code) every time.
And it's also possible to craft different event inputs for an integration test in order to test the business logic failure modes that you might otherwise consider writing a unit test for. For single-purpose Lambda functions with minimal business logic such as this, I often don't bother writing any unit tests and just cover off the business logic inside my integration tests.
Aside: Given the similarity between the entrypoint input events to the E2E and integration tests (a HTTP request and an APIGatewayProxyEvent), it's possible to get 2-for-1 when writing your test cases whereby a single test case can be run in one of two modes by switching an environment variable. I cover this technique in my workshop and I'll try to write more on it soon.
Conclusion
We've looked at the Simple Web Service pattern here but I've found value in leading with integration and E2E tests for almost any serverless use case that involves the triggering of a single-purpose Lambda function that calls on to a single downstream AWS service, e.g. S3-> Lambda-> DynamoDB, or SNS -> Lambda -> SES.
You definitely still can write unit tests in addition to integration and E2E tests (and there are many valid reasons why you might still want to do so). But my point here is that you may not have to for many serverless use cases where business logic is often simple or non-existent.
Unit tests are no longer the significant drivers of confidence from your test suite that they once were in server-based monolithic apps. In serverless apps, integration and E2E tests are king.
If you're interested in learning more about testing serverless apps, check out my 4-week Serverless Testing Workshop, starting on November 2nd, 2020. The workshop will be a mixture of self-paced video lessons alongside weekly live group sessions where you will join me and other engineers to discuss and work through different testing scenarios. If you sign up by October 28th you'll get a 25% earlybird discount.

Top comments (1)
Good article, I've used Mocha test scenario's to do exactly this. It's hard to get a handle on all the specific issues that can occur in a live environment that you simple cannot fully replicate offline.