
1. Overview of Kafka ksqlDB & Kafka Connect
ksqlDB:
- ksqlDB is Kafka’s SQL-based stream processing engine.
- It allows you to perform real-time analysis and ad hoc queries on Kafka topics using SQL-like syntax.
- Ideal for rapid prototyping, testing, and even certain production analytics—but for complex, long-lived applications, consider using the Java Streams API for enhanced maintainability.
Kafka Connect:
- Kafka Connect is a framework to reliably and scalably ingest data into Kafka (source connectors) or push data out of Kafka to external systems (sink connectors).
- It offers a rich ecosystem of pre-built connectors (for databases, cloud storage, Elasticsearch, etc.) and is available both in open source and through managed services like Confluent Cloud.
2. ksqlDB: Key Concepts and Usage
a. Interactive Querying and Prototyping
-
Quick Analysis:
ksqlDB provides a user-friendly interface to run SQL queries on your Kafka streams.-
Example:
CREATE STREAM rides_stream AS SELECT render_id, trip_distance, payment_type, passenger_count FROM rides_topic EMIT CHANGES; -
You can then run queries like:
SELECT * FROM rides_stream EMIT CHANGES;
-
-
Persistent Queries:
- You can create persistent queries (tables) that continuously aggregate or transform data.
-
For instance, grouping by payment type to get counts over time:
CREATE TABLE payment_counts AS SELECT payment_type, COUNT(*) AS cnt FROM rides_stream GROUP BY payment_type EMIT CHANGES; Persistent queries create internal topics that hold the state, which can be used for dashboards or further processing.
b. Production Considerations
- Maintainability: Although ksqlDB is excellent for rapid experimentation, in production you might want to use the Java Streams API with explicit version control over deployed SQL commands.
- Deployment: ksqlDB requires a separate cluster (or managed service) distinct from your primary Kafka Streams cluster. This introduces additional maintenance and cost considerations.
-
Usage Scenarios:
- Quick data exploration and proof-of-concepts.
- Building real-time dashboards.
- Ad hoc stream processing for monitoring or debugging.
3. Kafka Connect: Key Concepts and Usage
a. Purpose and Functionality
- Data Integration: Kafka Connect provides an easy way to ingest data from external sources (like databases, cloud storage, or files) into Kafka topics or export Kafka data to external systems.
-
Connector Ecosystem:
- Numerous connectors are available out of the box (e.g., for Elasticsearch, S3, JDBC, Snowflake).
- Both Confluent Cloud and the open-source Kafka Connect offer various connector plugins.
b. Setting Up and Configuration
-
Configuration Flow:
- In Connect, you define a connector configuration, specifying the topic, connection parameters (e.g., URI, credentials), and data formats.
- The Connect worker manages the lifecycle of connectors, scaling them based on throughput.
-
Example Scenario:
For instance, to export data to Elasticsearch, you would:
- Create a connector configuration (typically via REST API or UI).
- Specify the Kafka topic to read from, along with connection details for your Elasticsearch cluster.
- Once the connector is deployed, data flows continuously from Kafka to Elasticsearch.
c. Production Considerations
-
Resource Requirements:
- Running Kafka Connect may require additional infrastructure, particularly if you need custom connectors or need to scale out ingestion/export.
-
Connector Management:
- Ensure proper monitoring and error handling. Many connectors support automatic retries, but you should be prepared to manage schema evolution and data format changes.
-
Integration:
- For managed deployments (e.g., Confluent Cloud), many connectors are available as a service, reducing operational overhead.
4. Integrating ksqlDB and Kafka Connect
a. Complementary Roles
- ksqlDB for In-Stream Analytics: Use ksqlDB to query, transform, and aggregate stream data on the fly. It offers immediate insights and testing of your Kafka data.
- Kafka Connect for Data Movement: Use Kafka Connect to bring data into Kafka (from databases, logs, etc.) or to push data out of Kafka (to dashboards, storage systems, search engines).
b. Example Workflow
-
Data Ingestion:
- Use a Kafka Connect source connector to ingest data from a SQL database into a Kafka topic.
-
Real-Time Analysis:
- Use ksqlDB to create streams and tables from the ingested data, applying filtering, aggregation, or joins.
-
Data Export:
- Use a Kafka Connect sink connector to export processed results (e.g., aggregated metrics) to an external system like Elasticsearch or a data warehouse.
5. Best Practices and Considerations
a. For ksqlDB
- Use for Prototyping and Quick Insights: Leverage ksqlDB for interactive data exploration and simple aggregations.
- Monitor Persistent Queries: Persistent queries create internal state topics—monitor these for lag and resource usage.
- Plan for Production: Consider transitioning complex processing logic to the Java Streams API if your application grows in complexity.
b. For Kafka Connect
- Connector Management: Regularly review connector configurations and monitor connector health. Use Kafka Connect REST APIs to manage and scale connectors.
- Data Format Consistency: Ensure that your connectors are configured with consistent data formats (e.g., JSON, Avro) to prevent schema mismatches.
- Scalability: Plan for scaling Connect workers if your data throughput increases.
c. Integration Strategies
- End-to-End Testing: Test your pipelines by simulating both ingestion (via Connect) and transformation/analysis (via ksqlDB). Validate that data flows correctly between systems.
- Resource Allocation: Understand the resource implications of running multiple clusters (ksqlDB and Kafka Connect). Consider managed services if operational overhead is a concern.
- Cost Management: For proof-of-concept or prototyping, managed services like Confluent Cloud can reduce complexity, but evaluate cost implications for production workloads.
1. Overview Kafka Schema Registry
-
Purpose:
The Kafka Schema Registry is a centralized service that manages and enforces schemas for Kafka data. It ensures that producers and consumers “speak the same language” by maintaining a contract (schema) for the data format.
-
Why It’s Important:
- Compatibility: Prevents errors when the data format evolves over time.
- Contract Enforcement: Acts as a dictionary that both producers and consumers use to encode and decode messages.
- Data Integrity: Helps ensure that changes in the data format (e.g., field types or structures) do not break existing applications.
2. The Problem It Solves
- Producer–Consumer Mismatch: If a producer changes the message format (for example, changing a field type from string to integer) without coordinating with consumers, it can break data processing downstream.
- Schema Evolution Issues: Applications often need to evolve the data schema over time. Without a formal schema, such changes can lead to incompatibilities and runtime failures.
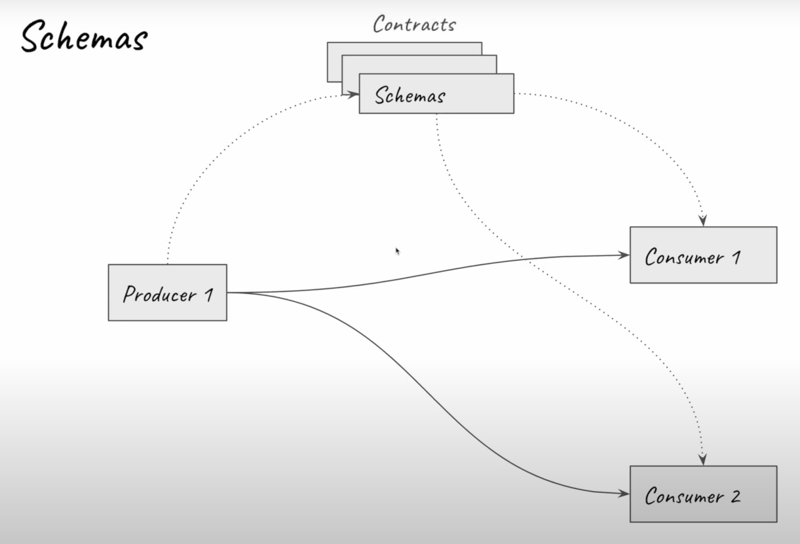
3. How Schema Registry Works
a. Schema Registration and Retrieval
-
Registration:
- When a producer sends data, it first registers its schema with the Schema Registry.
- The registry assigns a unique identifier (ID) to the schema.
- This schema ID is then embedded in each message, so that consumers can retrieve the schema and decode the message correctly.
-
Consumption:
- Consumers use the schema ID in the message to fetch the corresponding schema from the registry.
- The retrieved schema acts as a “contract” that tells the consumer how to deserialize the message.
b. Schema Compatibility and Evolution
-
Compatibility Levels:
The Schema Registry supports several compatibility modes:
- Backward Compatibility: New schemas can read data produced with old schemas. (E.g., if a new field is added with a default value, older messages are still readable.)
- Forward Compatibility: Data written with an old schema can be read by consumers using a new schema.
- Full Compatibility: Combines both backward and forward compatibility—any schema version can work with any other.
- None: No compatibility is enforced.
-
Schema Evolution:
- Producers may need to evolve the schema over time. For instance, a producer might change a field type or add new fields.
- The Schema Registry enforces the defined compatibility rules and rejects any schema changes that would break compatibility.
- This allows you to make enhancements without disrupting existing consumers.
4. Avro and Other Supported Formats
-
Avro:
- Avro is the most commonly used serialization format with Schema Registry.
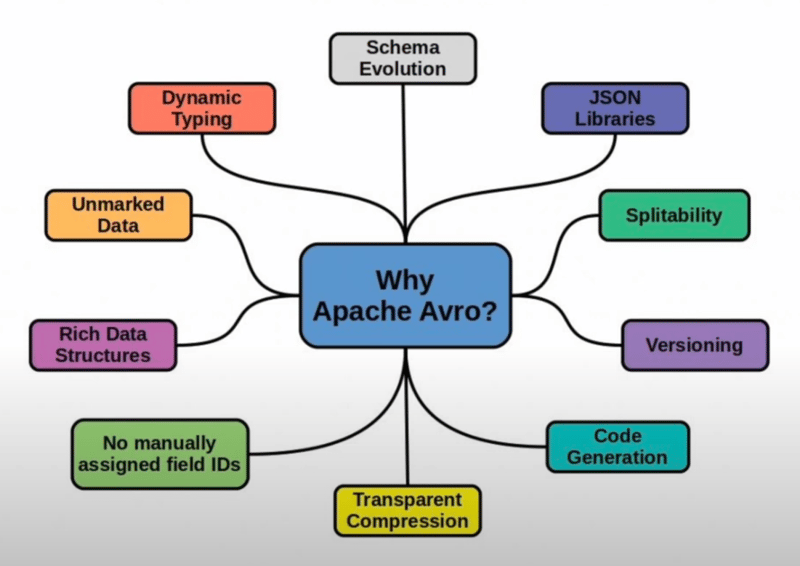
- **Features:**
- Compact binary encoding for efficiency.
- Schemas defined in JSON format, which makes them human-readable.
- Supports complex data types (e.g., unions, arrays, maps, enums) and features like default values.
- **Usage:**
Avro’s built-in support for schema evolution (through its compatibility rules) makes it ideal for dynamic, high-volume Kafka environments.
-
Other Formats:
- JSON Schema and Protobuf are also supported, each with its own advantages depending on the use case.
5. Schema Registry in Practice
a. Integration with Kafka
-
Producer Side:
- Producers use Avro (or other) serializers that are integrated with the Schema Registry.
- When a producer sends a message, the serializer registers the schema (if not already registered) and writes the schema ID into the message payload.
-
Consumer Side:
- Consumers use corresponding deserializers that read the schema ID from the message and retrieve the schema to deserialize the data.
-
Example Workflow:
- Producer registers schema → gets schema ID.
- Producer sends message (with embedded schema ID) to a Kafka topic.
- Consumer reads message → uses schema ID to fetch schema from registry.
- Consumer deserializes message using the schema.
b. Tools and Plugins
-
Gradle/Maven Plugins:
- Use plugins to auto-generate Avro classes from
.avscfiles. This simplifies schema management and code generation. - When changes are made to the schema file, re-running the build regenerates the classes, ensuring that producers and consumers are using the latest contract.
- Use plugins to auto-generate Avro classes from
-
Schema Registry UI:
- Many schema registry implementations (e.g., Confluent Schema Registry) provide a user interface to view registered schemas, compare versions, and manage compatibility settings.
6. Best Practices
-
Define Compatibility Settings:
- Set an appropriate compatibility level (backward, forward, full) based on your application’s needs.
- For instance, “full” compatibility is ideal when you need to ensure that all schema versions can interoperate.
-
Avoid Incompatible Changes:
- Changes such as renaming fields, changing field types without defaults, or removing required fields are typically disallowed.
- Plan schema changes carefully to maintain consumer compatibility.
-
Version Management:
- Treat the schema as a versioned contract. Use schema evolution strategies to add new fields (with default values) or deprecate old fields gradually.
-
Testing Schema Evolution:
- Simulate schema evolution in a test environment to ensure that producers and consumers remain compatible.
- Use tools like the TopologyTestDriver (for Kafka Streams) to verify that changes do not break downstream processing.
-
Documentation and Communication:
- Document your schema evolution strategy and communicate changes with all teams consuming the data.
- Maintain clear version histories to trace changes and ensure proper rollback if needed.

Top comments (0)