In this post, we will take a look at the evolution of recurrent architectures of neural networks and why the concept of attention is so exciting.
After reading this post, you should be able to appreciate why the Transformer architecture, introduced in the paper Attention Is All You Need (from which the title of this post is also borrowed), uses only attention mechanisms to achieve previously unimaginable feats like OpenAI's GPT-3.
Recurrent Networks
In feedforward networks, information flows in one direction: from the input layer, through your hidden layers, to the output layer. This type of architecture works for tasks like image classification, where you need to look at the entire input just once.

Recurrent networks, on the other hand, are well suited for inputs like natural language that are recurrent in nature: made up of word after word in a sequence. They take one input at a time from the sequence. With each input, they also get their previous output - this enables recurrent neural networks to process the input as a sequence.

An easier way to visualize recurrent networks is to "unroll" them - draw them separately for each time step.

Although RNNs have access to their previous output, they are not very good at remembering things that came long before in a sentence. These are more commonly known as "long-term dependencies".
LSTMs
LSTMs (short for Long Short Term Memory networks) are a type of recurrent network that has a vector called the "cell state" that helps it remember long-term dependencies.

At each time step, an LSTM performs the following operations:
- It decides how much information it should forget from its cell state, using a hidden layer called the forget gate.
- It decides what new information it should remember given the current input, using a hidden layer called the input gate.
- It decides what information it should use from its memory to provide an output, using a hidden layer called the output gate.

The above diagram is a little over-simplified so that it is easy to visualize the main parts that an LSTM is made up of. Let's take a closer look at each of the gates to see what goes on underneath.
The Forget Gate

The forget gate concatenates the current input and previous output and passes it through a hidden layer with a sigmoid activation. The output of this layer is then multiplied elementwise with the context vector.
Since sigmoid activations are between 0 and 1, values close to 0 instruct the LSTM to forget information in those parts of the cell state, and retain information where the sigmoid activation values are close to 1.
The Input Gate
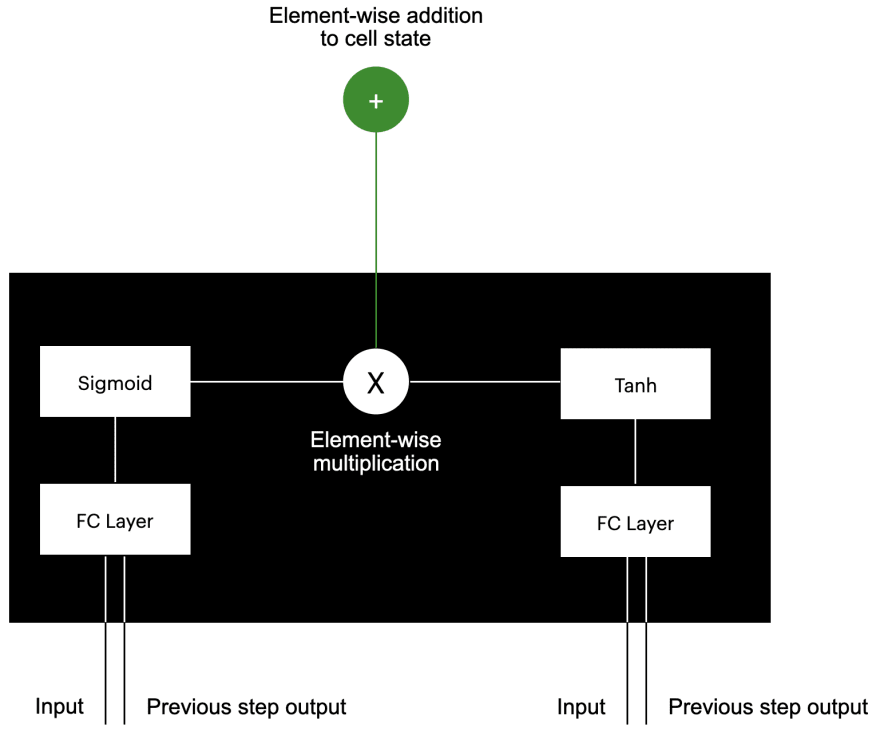
The input gate also works on the concatenation of the current input and previous output.
There is a sigmoid layer that decides which values to keep (between 0 and 1), and there is a tanh layer that provides values for what could be stored in the context vector. These two outputs are multiplied by each other and then added element-wise to the context vector.
The Output Gate

The output gate then multiplies elementwise the output of a sigmoid gate with the context layer passed through a tanh activation. The tanh activation helps bring the context vector in a range of -1 to 1 and the sigmoid activation helps select which parts of the context should be used for the output.
For a better understanding of what happens inside LSTMs, take a look at this blog post.
GRUs
GRUs (short for Gated Recurrent Units) are different from LSTMs in two major ways:
- GRUs don't have a separate cell state. The hidden state of the cell and its output are the same.
- GRUs have just 2 gates instead of 3 - the reset gate and update gate. The assumption is that if the network is trying to forget something from the hidden state, then it is because it wants to store some other information there. Therefore, we don't need separate forget and input gates. The additive inverse of the forget gate can be used as the input gate.
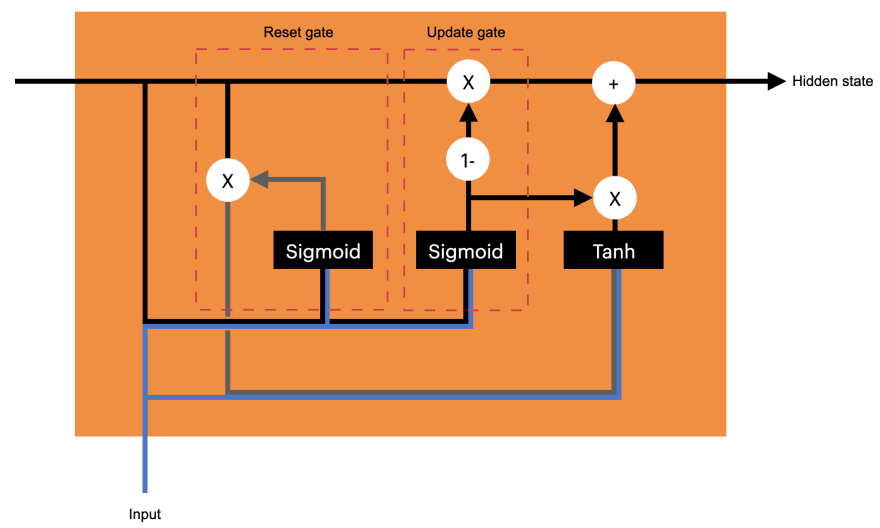
The reset gate decides what information from the hidden state needs to be supressed during this time step.
The update gate acts like a combination of the forget gate and input gate in an LSTM.
Sequence modelling with Encoder-Decoder architecture
Although LSTMs and GRUs perform better than vanilla RNNs, they have a problem that they have one output for each input at every time step.
This is not a problem for tasks like sentiment analysis where we are interested in just the last output. However, for tasks like language translation where the length of the output sequence and even the position of the translated words with respect to each other can be different, this is a major limitation.
Sequence-to-sequence (often abbreviated seq2seq) models solve this problem by splitting the entire process into two steps.
- The input sequence is first run through an encoder. The encoder generates a fixed vector representation of the input at the last time step.
- This fixed representation is then run through a decoder which produces the output sequence of interest.

The importance of paying attention
A major limitation of seq2seq models is that the encoder tries to cram all the information it can into a single vector. The model is therefore limited by how much information it can put in there. Also, the information in this vector will be biased towards the last few words that the encoder has seen most recently.
An attention layer works on all the output states of the encoder. At each step, the decoder looks at its previous output and a weighted sum of all the encoder outputs that the attention layer generates.

The attention layer is a fully connected layer that is trained to select the right encoder output to focus on at each given timestep. It is a fully connected network that receives the previous output of the decoder and all the hidden states of the encoder. The output is a scalar value for each encoder output that acts as the "weightage" for that time step.
These scalar values are passed through a softmax layer to ensure they add up to 1, and then multiplied by the corresponding encoder outputs and added together.
The resulting vector of the weighted sums of the encoder outputs is provided as an input to the decoder along with the output of the decoder at the previous time step. That way, the decoder can "see" which part of the input it needs to focus on to generate the next output.

The concept of attention is so powerful that the Transformer architecture used by models like GPT-3 does away completely with recurrent and convolutional operations and uses only attention!
Further reading
I highly recommend the following articles that helped me understand what I have written in this post:

Top comments (1)
I like your RNN topic "gate" explanation it is very good.
I also write blog on RNN please visit my blog and provide me your valuable thoughts: - RNN