
Data scientists and data analysts are constantly required to answer questions for the business. This could result in a more ad-hoc analysis or some form of model that will be implemented into a company's workflows.
But to perform data science and analytics, teams first need access to quality data from multiple applications and business processes. This means moving data from point a to point b. The general method of doing this is using an automated process known as an extract, transform, and load or ETL for short. These ETLs will usually load the data into some form of data warehouse for easy access. However, there is one major problem with ETLs and data warehousing.
Although necessary, ETLs require a lot of coding, know-how, and maintenance. Besides this work being time-consuming for data scientists to take on, not all data scientists are experienced with developing ETLs. Many times this work will fall on the data engineering teams who are swamped with bigger picture projects to bring in base layers of data.
This doesn't always line up with data scientists' needs who might have business owners who want the information and analytics fast.
Waiting until the data engineering team has time to pull in new data sources might not be a good option.
This is why several solutions have been developed in the past few years to reduce the amount of effort data scientists need to undertake to get the data they need. In particular, this has come in the form of data virtualization, automated ETLs, and No Code/low-code solutions.
Automated ETLs and Data Warehouses
Although ETLs in themselves are an automated process. They require a lot of manual development and maintenance.
This has led to the popularity of tools like Panoply which offer an easy to integrate automated ETLs and cloud data warehouse that can sync with lots of third-party tools like Salesforce, Google Analytics, and databases. Using these automated integrations, data scientists can quickly analyze the data without needing to deploy complex infrastructure.
No Python or EC2 instances are needed. All it requires is just a few clicks. Then, with a general understanding of what type of data you intend to pull in your team can have a populated data warehouse.
These automated ETL systems are very easy to use and often just require an end-user to set a data source and a destination. From there the ETLs can be set to run at specific times. All without any code.
Product example

As mentioned early, Panoply is an example of an automated ETL and data warehouse.
The entirety ingestion can be set up in the Panoply GUI where you can select a source and a destination and automatically ingest the data. Because Panoply comes with a built-in data warehouse, it automatically stores a replica of your data that can be queried using any BI or analytical tool you want with no concerns about jeopardizing operations or production. Approaching data infrastructure this way makes sense for users looking to keep things simple while still making access to nearly real-time data available throughout the organization.
In turn, this allows data scientists the ability to answer ad-hoc questions without needing to wait four weeks for the BI team to bring the data into the data warehouse.
Pros
- Easy to learn and implement
- Cloud focused
- Easy to scale
Cons
- Automated data warehouses and ETLs on their own won't manage complicated logic
- More complex transforms might require adding in a no-code/low-code ETL tool
No-Code/Low-Code
No code/low-code is a few steps away from automated ETLs. These types of ETL tools have a more drag and drop approach. This means there are set transformations and data manipulation functions that can be dragged and dropped into place. Other similar solutions might be more GUI based which allows users to dictate source, destination, and transformations. In addition, many of these No-code low-code solutions allow the end-user to see into the code if they want and edit it.
For users who have no code experience, this is a good solution. With no code/low code data scientists can develop ETLs with limited syntax in order to create some decently complex data pipelines. Instead of needing to set up a lot of complex infrastructures to manage when data pipelines run and what they are dependent on. The user just needs to understand at a high level where their data is, where they want it going, and when they want it going there.
Cons
- Limited customizability in code
- Each tool is different thus a developer must relearn an ETL at the next job
- No Code/low-code can be too easy and lead to bad high level design
Pros
- No coding experience technically required
- Easy to integrate into a lot of popular third-parties
- Many are cloud based solutions
Product example
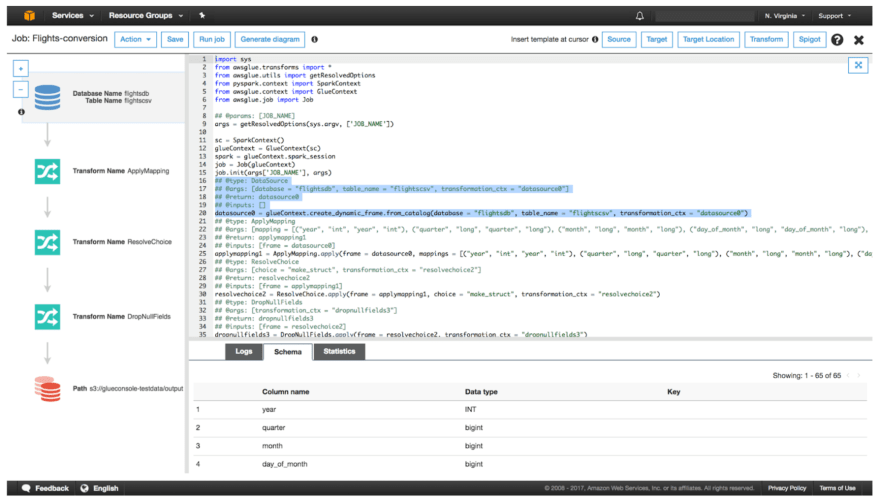
Image source: aws.amazon.com
There are a lot of products in this category. There are products like AWS Glue, Stitch, and FiveTran.
AWS Glue is a great example of a modern cloud-based ETL solution. This allows developers to set up jobs with a few clicks and the setting of parameters. This can allow data scientists the ability to move and transform data without as much code.
Glue being part of AWS easily integrates with other services like S3, RDS, and Redshift. This makes it very easy and intuitive to develop your data pipelines on AWS. However, there is one major caveat with AWS Glue. Unlike many other No-Code/Low-Code options, it was developed to run on AWS. This means if you suddenly decide to switch to a different cloud provider, you might have to spend a lot of time and money just switching from Glue to some other solution.
In the end, this is an important consideration your team should make prior to developing your ETLs.
Data virtualization
Data virtualization is a methodology that allows users to access data from multiple data sources, data structures and third-party providers. It essentially creates a single layer where regardless of the technology used to store the underlying data, the end-user will be able to access it through a single point.
Overall, data virtualization offers several advantages when your team needs access to data fast. Here are a few examples of how data virtualization can benefit your team.
Pros
- Allows data scientists to blend data from multiple databases
- Manages security and access management
- Real-time or Near Real-time data
Cons
- High learning curve
- Requires an administrator to manage
- Still requires users to think through design and data flows
Product example

One of the better-known providers of data virtualization is Denodo. Overall the product is arguably the most mature and feature-rich.
Denodo's focus on helping users gain access to their data in essentially a single service is what makes it so popular with its many customers. Everyone from healthcare providers to the finance industry relies on Denodo to relieve pressure off of BI developers and data scientists by reducing the necessity to create as many data warehouses.
Overall, these three options can help your team analyze data without putting in as much effort into developing complex ETLs.
Conclusion
Managing, blending, and moving data will continue to be a necessary task for data scientists and machine learning engineers. However, the process of developing these pipelines and their corresponding data warehouses doesn't have to take as long as it has in the past. There are a lot of great options for developing ETLs either with automatically integrating systems or through other methods like no-code/low-code and data virtualization. If your team is looking to reduce the workload on your data engineers, these are a lot of options. Your team might also might be spinning up a new data science team that will need data fed to them right away, then using a solution like Panoply might be a good option.
Thanks for reading.
What Is A Data Warehouse And Why Use It
Data Engineering 101: An Introduction To Data Engineering
SQL Best Practices --- Designing An ETL Video

Top comments (0)