Software at Scale
 Software at Scale
Software at Scale
Quadratic C.I. Cost Growth
A significant portion of cost of software infrastructure at a technology organization is due to CI/CD (Continuous Integration/Continuous Deployment). It is easy to overlook CI cost since CI isn’t strictly required to operate a software application, but it’s a critical component of the software development lifecycle.
A less obvious aspect of CI cost is that, in some cases, it can increase at a quadratic rate over time. John Micco, the ex lead of the Google Test Automation Platform group, mentioned that Google would spend more on CI than the rest of its compute combined if it didn’t introduce serious optimizations along the way.
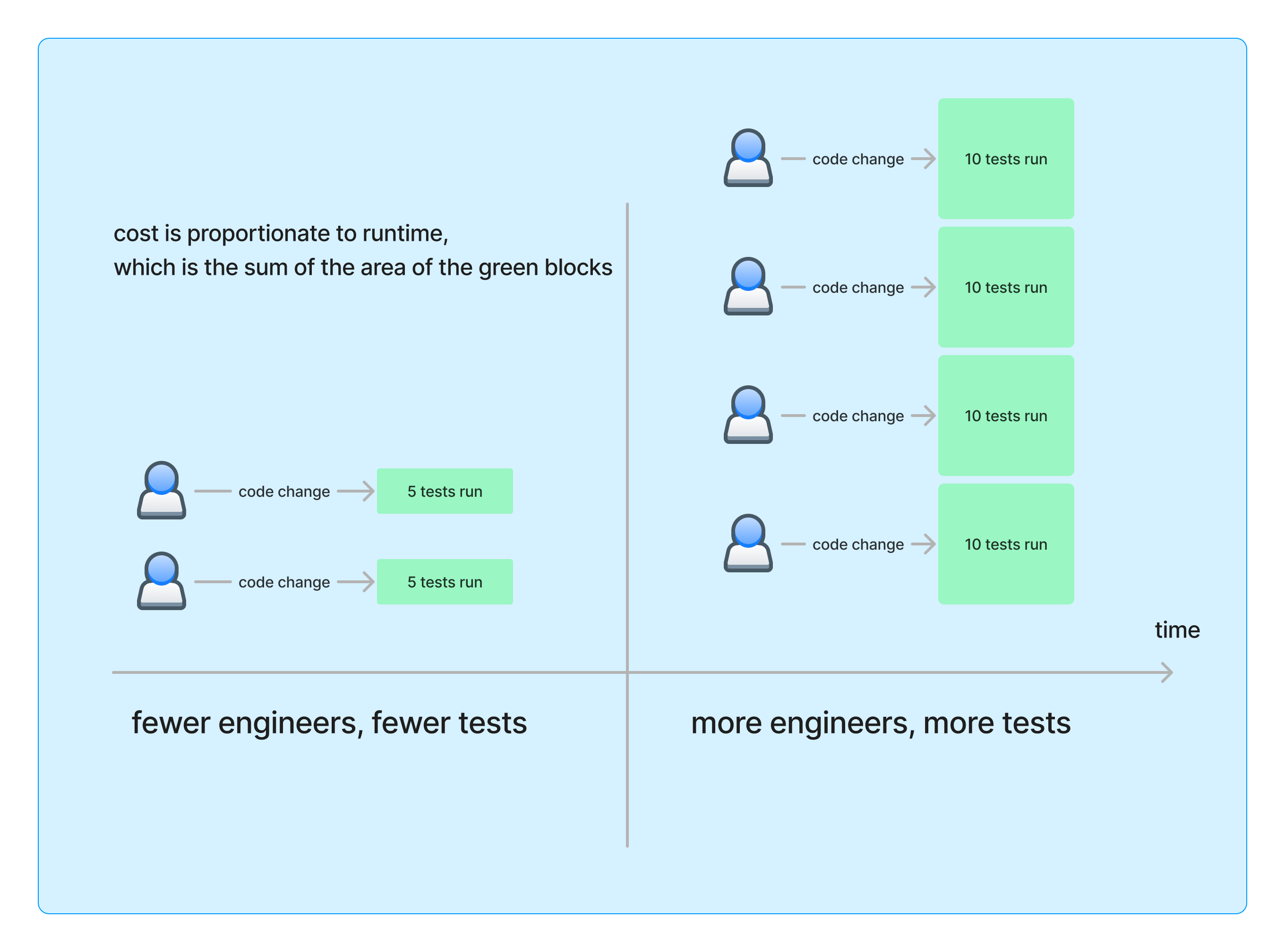
We’ll explore the worst-case scenario: an engineering organization that uses a monorepo (a single repository that stores all the code and assets for a project) and runs the entire test suite on every code change (no selective testing).
There are two primary dimensions to the growth in CI cost. The first dimension is the size of the engineering team. As the engineering team grows, the number of code changes to the monorepo being tested in the CI system often grows linearly1.
The second dimension is the size of the codebase and the corresponding size of the test suite. Codebases and test suites often grow with new features over time. Additionally, software engineers are often hesitant to delete tests unless they’re confident that the system under test is deprecated and unused. So every code change tests a slightly larger codebase, which takes some more CPU time. Since there’s no selective testing, each test adds CPU time, regardless of parallelism.
In summary, as the organization grows, there are more code changes, and there’s more CPU time spent testing each change. Multiplying the increasing number of code changes with the growing CPU time needed for each change results in a quadratic rate of growth in CI CPU time, which is proportionate to resource use.
There are several strategies to mitigate this growth. Selective testing is a key strategy for reducing costs and ensuring faster feedback times from CI on code changes. Examples include Tinder and Dropbox for algorithmic selective testing and machine-learning approaches from larger organizations like Meta. Additionally, there are products and organizations focused on selective testing as a service. Other approaches include file-based test selection. Multirepo systems sidestep the problem but have other downsides like trickier code-sharing.
CI cost can also be much harder to optimize through one-time projects. It’s hard to meaningfully reduce the test-suite size in a large organization, and there’s often no easy way to retrofit better test selection in a poorly structured codebase. Other options like running fewer tests may disproportionately affect developer velocity.
Maintaining lower CI costs involves general code quality improvements. This includes ensuring the codebase remains modular, preventing the blind copying of slow and inefficient test patterns, and making sure that sufficient test tooling, like mocks and fakes, is available for developers to use.
Overall, CI cost exhibits the challenging combination of growing quadratically and being hard to optimize. By actively monitoring CI costs and employing strategic optimization techniques, organizations can maintain a balance between resource efficiency and robust testing, fostering a sustainable software development lifecycle.
If it doesn’t grow linearly, that might be another developer velocity problem to debug.




