
This is a very important metric. How much time you waste waiting for a response after a change. For example, you changed the code, how much time you need to wait to see if there is a type error, if there is a lint error (linter), if tests are failing, to wait until browser reloads, to wait until server reloads, to wait until UI redraws, to wait until it compiles etc.
There can be different types of speed (not a research data, if you have research on this subject please point me in the right direction):
- milliseconds - the ideal response. You will not notice it. Example, OCaml recompilation.
- seconds - slow enough to notice, not slow enough to be distracted. You will get annoyed eventually
- minutes - slow enough to get distracted. You will most likely switch context to something else, like reading a blog or talking to a colleague, and you will get back to it when it is long time finished.
If feedback loop, for example, to run a test suite for big application takes 30min (😱yes, this can happen) it means that you have only 16 loops per day. You know this talk about the 10x developer, it can happen that is just because they know how to minimize feedback loop. See Justin Searls talk " How to Stop Hating Your Tests", he explains it very well. Gary Bernhardt, the person behind the destroyallsoftware, also talks about the importance of the feedback loop all the time.
As you can guess this is a hard problem, or maybe not hard but with the least priority (if the developer follows "make it work, make it right, make it fast" principle).
Hot (module) reload
Hot (module) reload - one of the popular workarounds is to keep the system running and reload only parts of it, the downside of this approach is that some state can stack and you will not be able to get out of it until full restart (cache invalidation is a hard problem). They've struggled with this issue in Rails for a long time, there were at least three attempts to fix it: spork, zeus, spring. As far as I know, there are still some subtle errors happen from time to time. react-hot-loader and Flow server also suffer from those issues, to name a few. This problem is hard only when you have to deal with mutable things, otherwise this solvable task, for example in Erlang you can reload system in the production.
Preserve state
In addition to hot reload you can preserve state between reloads, by extracting out state and keeping other code as "pure" as possible. This is what they do in Redux (one of the examples), so when application reloads (assuming that something except store was reloaded) it will be in the same state as before, so you can resume your interaction with the system, without the need to recreate the state.
Watch mode
Related, but not necessarily the same trick is a watch mode e.g. rerun command every time file on the disk is changed. This saves some milliseconds. This technique can be combined with the first one.
Notifications
If you have no other choice than run long commands - you can send notifications at the end of the operation. See lmk and undistract-me.
TDD specific recieps
- Prefer unit tests over integration tests
- Mock out IO operations, like network calls
- Make sure that tests are isolated, this way you can run it in parallel
Immediate response
Switching between windows or terminal tabs also contributes to the feedback loop. It is nice to show the results of testing or type-checking in IDE without the need to switch to the different window, without the need to run some command explicitly. For example, in vscode-jest they show the status of each test inline
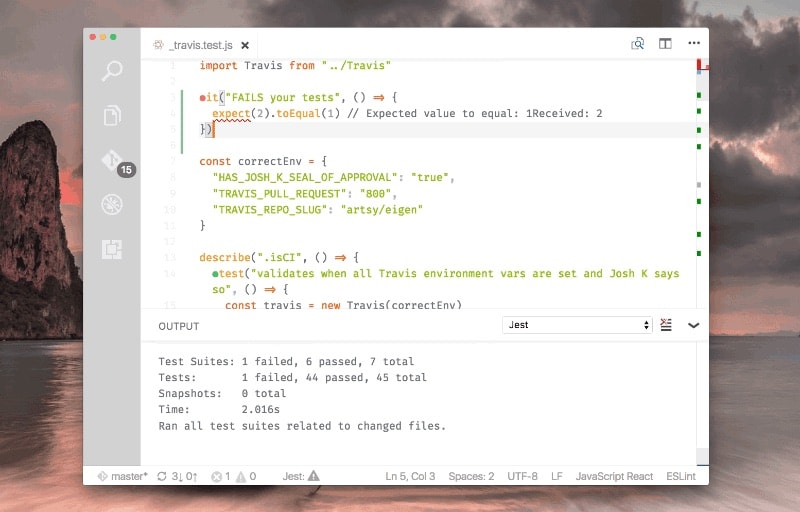
Or for example, Chrome Developer tools evaluates expression before you press enter key

Photo by Oliver Hale on Unsplash

Top comments (1)
Some things are mixed up, let's clear up
Typically in case of big test suite people use "focus" feature e.g. run test suites only related to the part they change, and if they lucky enough they get isolated part, so running this test suite is enough (this way feedback loop is a bit smaller). Then they commit it and hope it will not break in CI. While test runs, people switch to something else, to the next ticket for example, and then can happen that CI is broken and they need to switch context back to fix it.
Or different approach, people simply give up TDD - they just code everything without running tests and come back to PR only if CI fails.
Does it sound familiar?