
Author: @datastorydesign
What is SurrealDB?
That might be a strange question to start off a blog post about benchmarking, but it’s a very important one.
Why is it important?
Because that, to a large extent, determines what kind of benchmarks make sense to run against SurrealDB.
Let's therefore address that question first: What exactly is SurrealDB?
The challenge of multi-model benchmarking
SurrealDB is a multi-model database that natively handles all types of data: relational, document, graph, time-series, key-value, vector and full-text search and more, all in one place.
SurrealDB also handles all types of deployment environments, from embedded devices to distributed clusters. This is made possible by one of the fundamental architecture designs of SurrealDB, separating the storage layer from the computation layer.
SurrealDB also has a built-in security layer, along with API layers for REST, RPC, and GraphQL. This blurs the lines between a traditional database and a backend as a service (BaaS).
Users like you giving SurrealDB a try for the first time come from all kinds of previous databases:
- SQL and NoSQL
- Embedded and distributed
- Traditional database and backend as a service
Naturally, you want to know how it compares to your previous database. Possibly even multiple previous databases if you’re replacing multiple databases with SurrealDB.
This is also something we are very interested in. But considering the versatility of SurrealDB, it can get complicated very fast.
For example, how immediately and reliably data is flushed to disk is not the same across databases. There are many configuration options which can result in dramatically different performance metrics. In-memory databases, as the name suggests, don't even write to disk.
It's important to keep this in mind, as we're comparing SurrealDB with various configurations against various kinds of databases. We've done our best to configure each database in the most fair way possible and added code comments, such as in the code for MongoDB, to help explain some of our reasoning. If you think any of our configurations can be improved, we'd love to hear about it, as we want to be as fair as possible.
The need for robust internal tooling
Over this last year, we have been looking into all the various benchmarking possibilities out there and have run various tools and tests to help us improve our performance and make sure there are no performance regressions between versions.
We have a vision for what SurrealDB is and can be, but as a young project, we are also heavily influenced by what you want SurrealDB to be and, therefore, the contributions you make really matter. That is why we are now opening up all our benchmarking tooling and asking for your feedback in helping us test and optimise for the things that matter to you!
Our internal benchmarking tool
What we have found the most useful and therefore put the most effort into is developing our own benchmarking tool that is built in Rust and can be easily extended to cover everything that SurrealDB does and compare against any database or platform you use.
The crud-bench benchmarking tool is an open-source benchmarking tool for testing and comparing the performance of a number of different workloads on embedded, networked, and remote databases. It can be used to compare both SQL and NoSQL platforms, including key-value and embedded databases. Importantly, crud-bench focuses on testing additional features which are not present in other benchmarking tools, but which are available in SurrealDB.
The primary purpose of crud-bench is to continually test and monitor the performance of features and functionality built into SurrealDB, enabling developers working on features in SurrealDB to assess the impact of their changes on database queries and performance.
The crud-bench benchmarking tool is being actively developed with new features and functionality being added regularly. If you have ideas for how to improve our code or want to add a new database to compare against, we’re more than happy for your feedback and contributions!
How does it work?
When running simple, automated tests, the crud-bench benchmarking tool will automatically start a Docker container for
the datastore or database which is being benchmarked (when the datastore or database is networked). This configuration
can be modified so that an optimised, remote environment can be connected to, instead of running a Docker container
locally. This allows for running crud-bench against remote datastores, and distributed datastores on a local network
or remotely in the cloud.
In one table, the benchmark will operate 5 main tasks:
- Create: inserting N unique records, with the specified concurrency.
- Read: read N unique records, with the specified concurrency.
- Update: update N unique records, with the specified concurrency.
- Scans: perform a number of range and table scans, with the specified concurrency.
- Delete: delete N unique records, with the specified concurrency.
With crud-bench almost all aspects of the benchmark engine are configurable:
- The number of rows or records (samples).
- The number of concurrent clients or connections.
- The number of concurrent threads (concurrent messages per client).
- Whether rows or records are modified sequentially or randomly.
- The primary id or key type for the records.
- Total control on the record structure: Columnar, object (JSON-like).
- Fine grained control over record types: string, booleans, numbers, array.
- The scan specifications for range or table queries.
Which workloads can it run?
As crud-bench is in active development, some benchmarking workloads are already implemented, while others will be
implemented in future releases. The list below details which benchmarks are implemented for the supporting datastores
and lists those which are planned in the future.
CRUD
- [✔️] Creating single records in individual transactions
- [✔️] Reading single records in individual transactions
- [✔️] Updating single records in individual transactions
- [✔️] Deleting single records in individual transactions
- [ ] Batch creating multiple records in a transaction
- [ ] Batch reading multiple records in a transactions
- [ ] Batch updating multiple records in a transactions
- [ ] Batch deleting multiple records in a transactions
Scans
- [✔️] Full table scans, projecting all fields
- [✔️] Full table scans, projecting id field
- [✔️] Full table count queries
- [✔️] Scans with a limit, projecting all fields
- [✔️] Scans with a limit, projecting id field
- [✔️] Scans with a limit, counting results
- [✔️] Scans with a limit and offset, projecting all fields
- [✔️] Scans with a limit and offset, projecting id field
- [✔️] Scans with a limit and offset, counting results
One thing to note about the scans with a limit and offset, [S]can::limit_start_all (100), is that our implementation is not fully optimised yet and will therefore not be as fast as other databases.
Filters
- [ ] Full table query, using filter condition, projecting all fields
- [ ] Full table query, using filter condition, projecting id field
- [ ] Full table query, using filter condition, counting rows
Indexes
- [ ] Indexed table query, using filter condition, projecting all fields
- [ ] Indexed table query, using filter condition, projecting id field
- [ ] Indexed table query, using filter condition, counting rows
Relationships
- [ ] Fetching or traversing 1-level, one-to-one relationships or joins
- [ ] Fetching or traversing 1-level, one-to-many relationships or joins
- [ ] Fetching or traversing 1-level, many-to-many relationships or joins
- [ ] Fetching or traversing n-level, one-to-one relationships or joins
- [ ] Fetching or traversing n-level, one-to-many relationships or joins
- [ ] Fetching or traversing n-level, many-to-many relationships or joins
Workloads
- [ ] Workload support for creating, updating, and reading records concurrently
As you can see from the above list, there is still a lot to do and we are committed to provide a very comprehensive benchmarking environment.
If you think there is something we are missing or something we can improve, let us know!
Crud-bench is open for contributions such that you can raise issues and submit PRs for things that matter most to you.
Details of this benchmarking run
Crud-bench is running with the following hardware specifications:
- Environment: single node Hetzner instance
- Instance size: CCX63
- Dedicated vCPU: 48
- Memory (GiB): 192
- Instance storage: 960 GB NVMe SSD
Crud-bench is running with the following configurations:
- Number of records: 5 000 000
- Number of clients: 128
- Number of threads: 64
- Primary key type: string26
- Cooldown between runs: 15 min (cooldown prevents CPU throttling)
- Record contents sample:
{
"integer": -649603394,
"nested": {
"array": [
"oICD6WTWrrPgHxDsSPSBoOSDF5fOw63orRmaieWlC59Mnbtx9S",
"3679FpWwclzTXEICDe8Qyqxf7XWwiDNhP9SFIDNszaLsQxg316",
"UrZt46kMNd60oCftGYtd0ZcEAMAReuBiwCdlcvIDqZgEkww9bg",
"CbwLLVw8OX0ymvgcBJ8AldhXMAlk3DmvIJvFQzAZLSOsubfhL4",
"pTiBvzTomwOyCkY3xv9CAfRU7klrmDAvbfQcASe66UNEGf89Wz"
],
"text": "cFw L3div76qg OIP3I mKMU3l vX395uDd 16jMHx 7zPM39 yG Cj L7Y8C8D nZZzc pUE8 qMz4 VPmkUH N7Yh2Xwg S00I 2hJLQC F5S2o IDadxYiaU wJ6s0I Dq KkOjxDC2 Zuj NZx28LU EG WJXG9v hKBWyX7 GiKpIL HtSwDANp3 y16Thb 08kYxhPWB u7bU TWaFZ t7nfoe4CU wKrq6HhB nFmR WIR9H Sb3BpPk rO Zk bWWLNHa IALWXX ajOCI NwO zl cN vMYZZ 4hkiWn Lh6A XR1 UkHZyiuw tiF o3JF1TNi v4f ICWpD 8JCWJ LP0h ywfLy do NPNt3q x6sfOn b9DDWfR Y4WqYJE S0T TC Iy uyr9W8i muj1 1N50bSQyL fnU 5QJaNSNOD 7Biav64 ez U5Wid1vk KsN CAyqJwG It as RJP KO 6q gJnE 6aljDtes DurAHei qIOFjC DS AbXvrmUX1 qz4 8Dq14i MqxAnt CHo u6kSff53t ng fSLgs PG 8UHhQA0A ei aX1ou 0V17xl 8Yc0T eUURFG0 oydm JYI VcJdFAd dI fm w7o mhDYTaY4A Y0xmtucTZ 7ZnM1M Z8h06h AGx6aI4 3Xi aFrb g65D0 ixSYe ZHA0 Ag KwTasnW C7A1pSzvg G3Hn3Gtw eGvxZfzQQ 4RMXFJgWM Ozj7oF llFwyn9R lvrYOJfv Y8 FrhfWUMIL pU5KdGZd taueohT LxFaieQ 4Bpebv J0t5bHtsz l3VVN aPH5 EGZ CsDT8 5J SKF 9k7FMR7X JzNtI qfF2vu T2MZx iLtv llmEl CxKnhhF6 N6bULGU fQxIOo5n M6Umh rjK 0y KIWLf 9CVj 9G36Vwji 7vSMt7GmH 1uk b23htGq stB CvWNZuFxG"
},
"text": "04Pn 8jBDDE ATemPG79l jkh1 u8zHq KP E6tZytaI dOT4 NDNT"
}
Below you'll find summary tables of the crud-bench results, grouped into the different data models.
For more detailed results, you can check out the crud-bench GitHub repository
We run all the various benchmarks daily on GitHub actions, so you can also keep track of our performance journey there.
Relational (SQL) database comparison
While SurrealDB is a multi-model database, at its core, SurrealDB stores data in documents on transactional key-value stores. SurrealDB also uses record links and graph connections to establish relationships instead of joins.
This means that the most established relational benchmarks, such as TPC-C for transactional databases, cannot currently be run without modifications that the TPC-C benchmark would explicitly prohibit. This also applies to TPC-DS for analytical databases. Therefore, while we’ve looked into this quite a bit to determine the feasibility, we’ve decided not to implement these benchmarks yet. If you are interested in seeing this benchmark for SurrealDB, let us know. We would also be happy for contributions if you are familiar with implementing this benchmark.
For now, you can see the below crud-bench summary results comparing SurrealDB with the RocksDB and SurrealKV configurations vs PostgreSQL and MySQL.
Total time
Wall time - Lower is better - Time from start to finish as measured by a clock
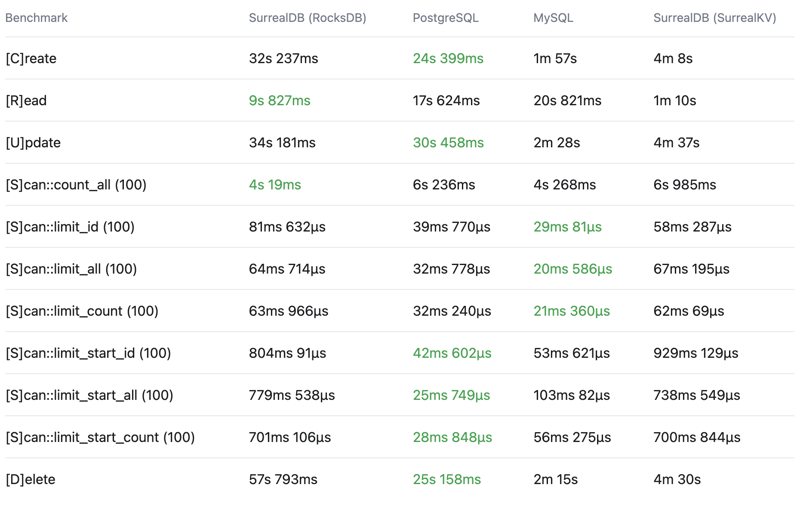
Throughput
Operations per second (OPS) - Higher is better
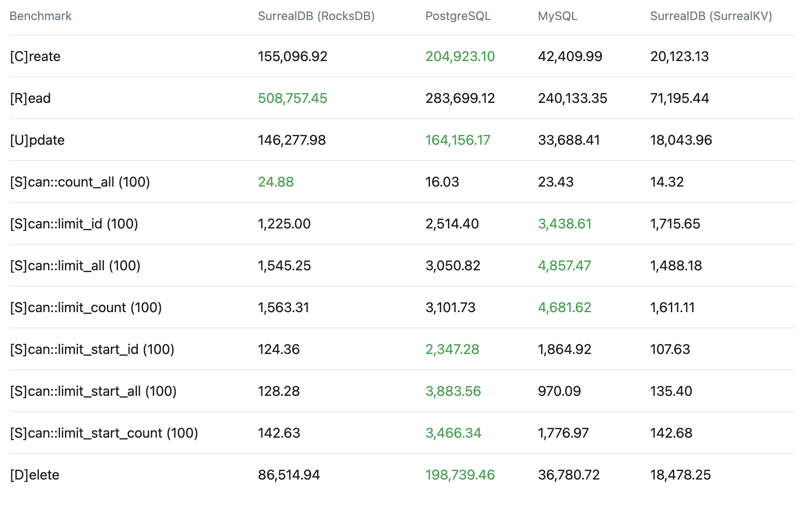
Latency
99th percentile - Lower is better - Top 1% slowest operations, 99% of operations are faster than this
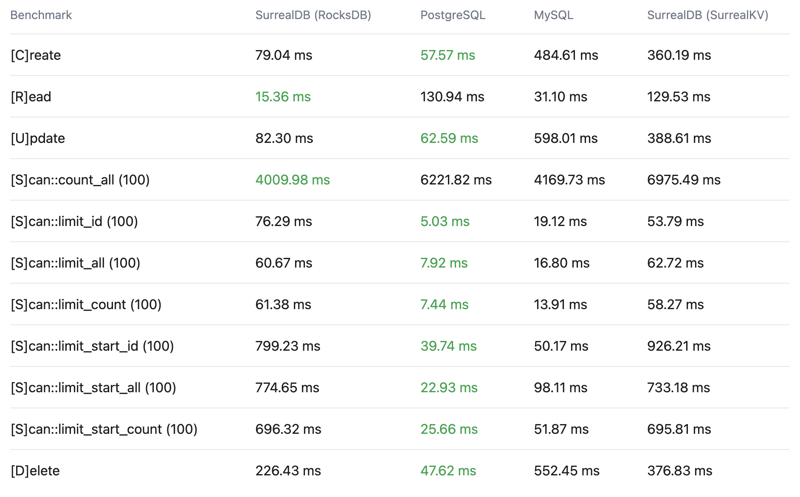
Click here to see the full results
Relational embedded database comparison
See the below crud-bench summary results comparing SurrealDB with the RocksDB, SurrealKV and in-memory configurations vs SQLite.
Total time
Wall time - Lower is better - Time from start to finish as measured by a clock
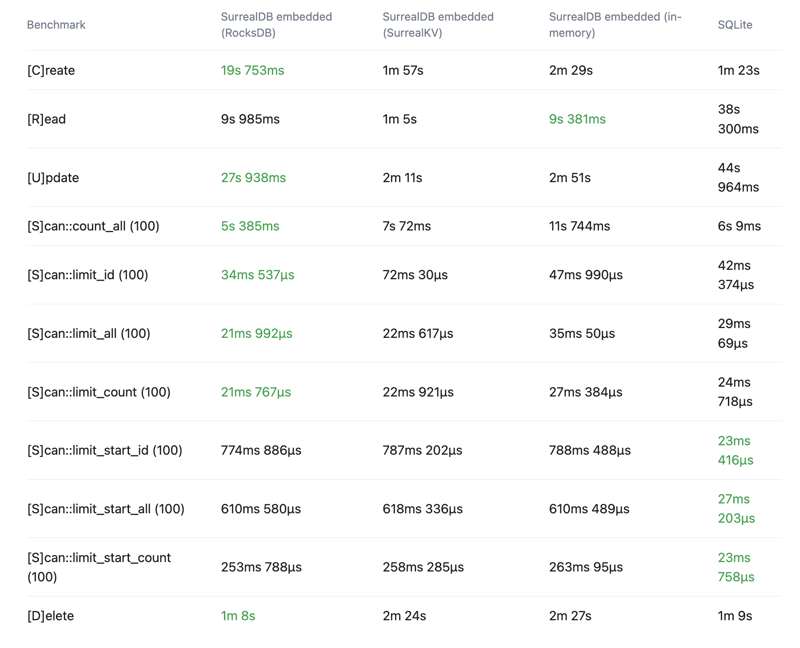
Throughput
Operations per second (OPS) - Higher is better
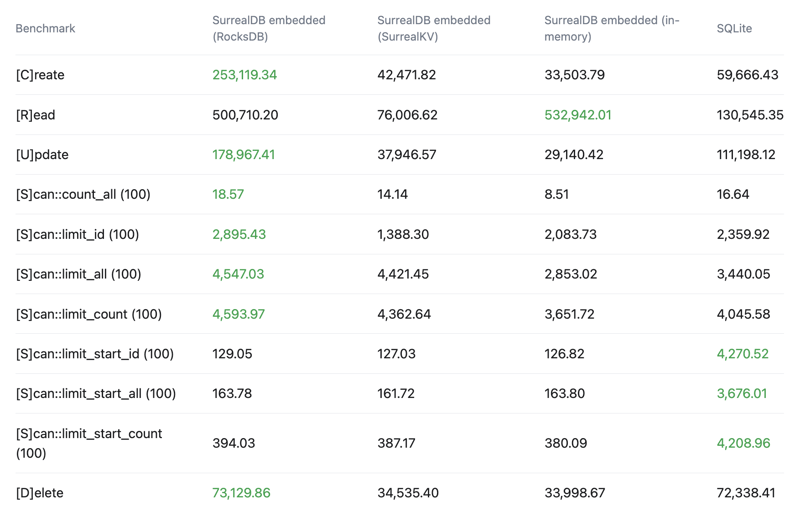
Latency
99th percentile - Lower is better - Top 1% slowest operations, 99% of operations are faster than this
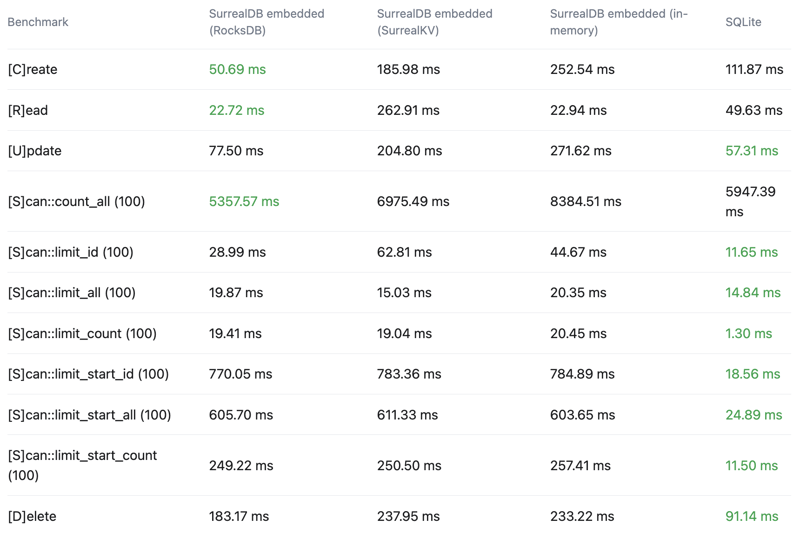
Click here to see the full results
Document database comparison
The closest thing the NoSQL community has to a standard benchmark is the Yahoo! Cloud Serving Benchmark (YCSB), which has 6 workloads simulating various database use cases.
In our benchmarking repository, you’ll find an implementation of this benchmark in the Go programming language. This implementation was ported to Go from Java by PingCAP.
You’ll also find a fork of NoSQLBench which is developed by DataStax. The SurrealDB changes to this benchmarking tool have not yet been released, but its something we are actively looking into.
We are working on running the YCSB benchmark in a multi-node configuration, which will come after this single node crud-bench benchmark.
For now, you can see the below crud-bench summary results comparing SurrealDB with the RocksDB and SurrealKV configurations vs MongoDB and ArangoDB.
Total time
Wall time - Lower is better - Time from start to finish as measured by a clock
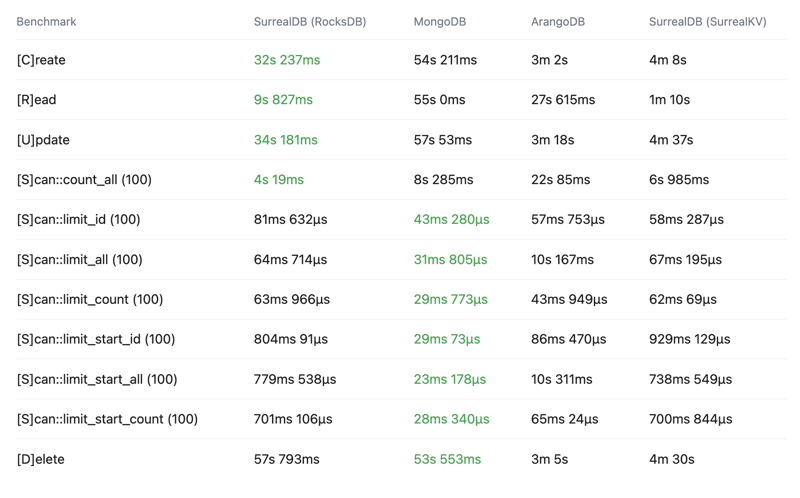
Throughput
Operations per second (OPS) - Higher is better
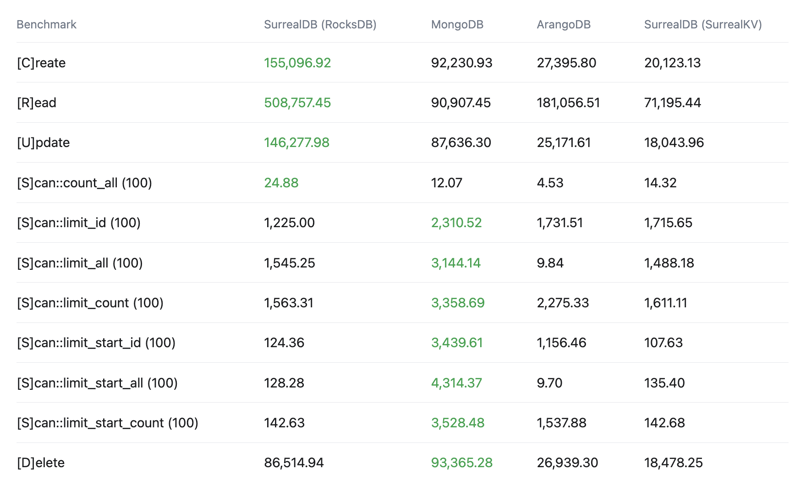
Latency
99th percentile - Lower is better - Top 1% slowest operations, 99% of operations are faster than this
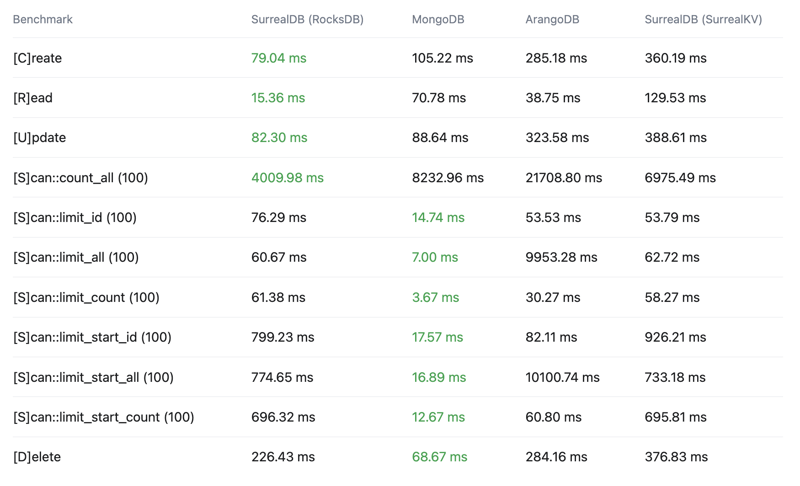
Click here to see the full results
Graph database comparison
As we continue to make improvements to our graph features, we are looking into implementing the benchmarks from the Linked Data Benchmark Council (LDBC). If this is something you are interested in, please reach out to us!
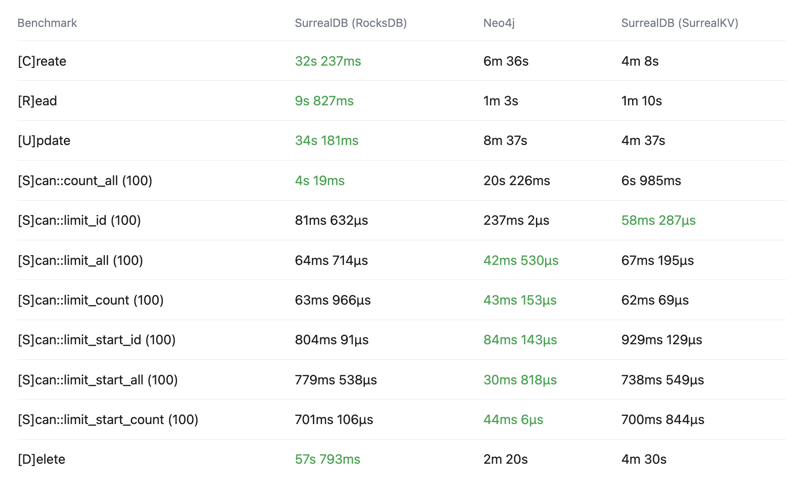
For now, you can see the below crud-bench summary results comparing SurrealDB with the RocksDB and SurrealKV configurations vs Neo4j.
One thing to note is that this is not comparing graph relationships, only crud operations, as we have not yet implemented relationships in crud-bench.
Total time
Wall time - Lower is better - Time from start to finish as measured by a clock
Throughput
Operations per second (OPS) - Higher is better
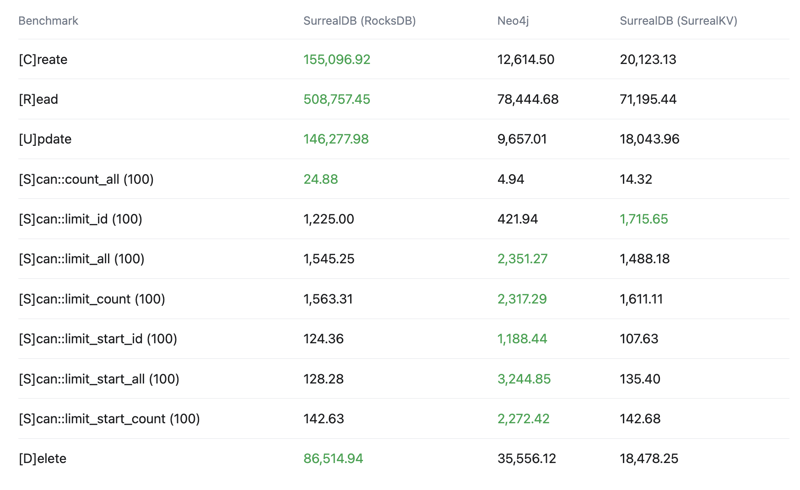
Latency
99th percentile - Lower is better - Top 1% slowest operations, 99% of operations are faster than this
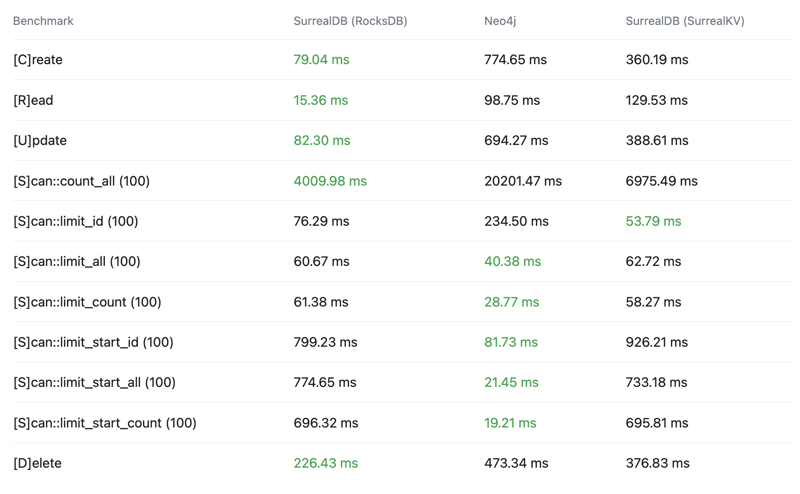
Click here to see the full results
In-memory database comparison
See the below crud-bench summary results comparing SurrealDB with the in-memory configuration vs Redis, Dragonfly and KeyDB.
If you would like to see more comparisons or have ideas of how we can improve these benchmarks, let us know.
Total time
Wall time - Lower is better - Time from start to finish as measured by a clock
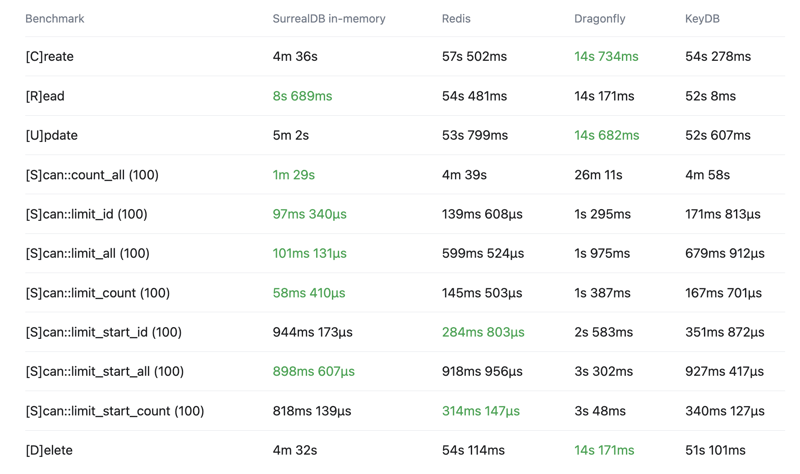
Throughput
Operations per second (OPS) - Higher is better
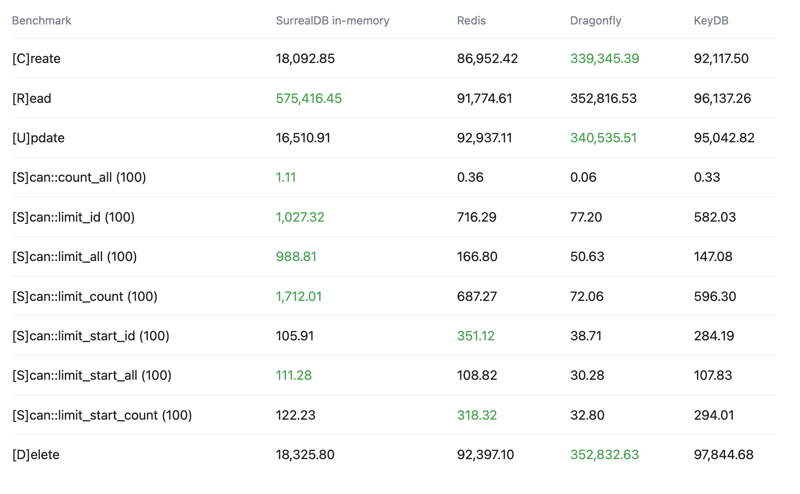
Latency
99th percentile - Lower is better - Top 1% slowest operations, 99% of operations are faster than this
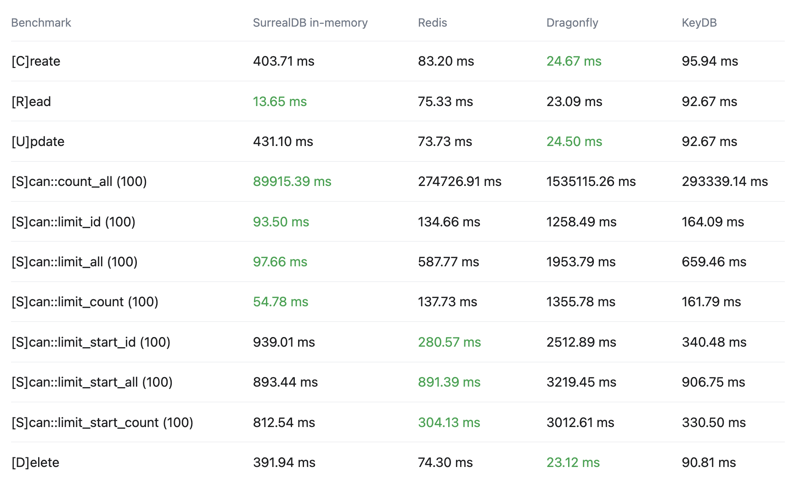
Click here to see the full results
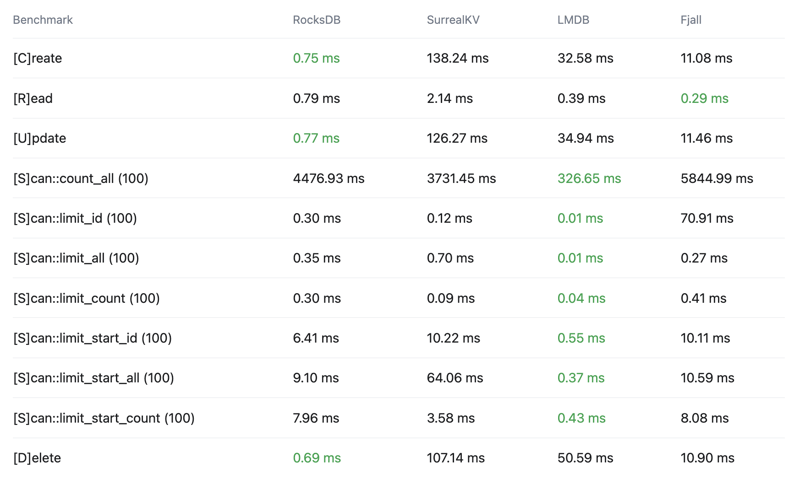
Key-Value store comparison
See the below crud-bench summary results comparing SurrealKV key-value storage engine vs RocksDB, LMDB and Fjall.
A few things to note regarding SurrealKV:
- It's still in beta and under active development.
- It's primary purpose is not to replace RocksDB, but to enable new use cases such as versioning/versioned queries.
- RocksDB is still our primary key-value storage engine
If you would like to see more comparisons or have ideas of how we can improve these benchmarks, let us know.
Total time
Wall time - Lower is better - Time from start to finish as measured by a clock
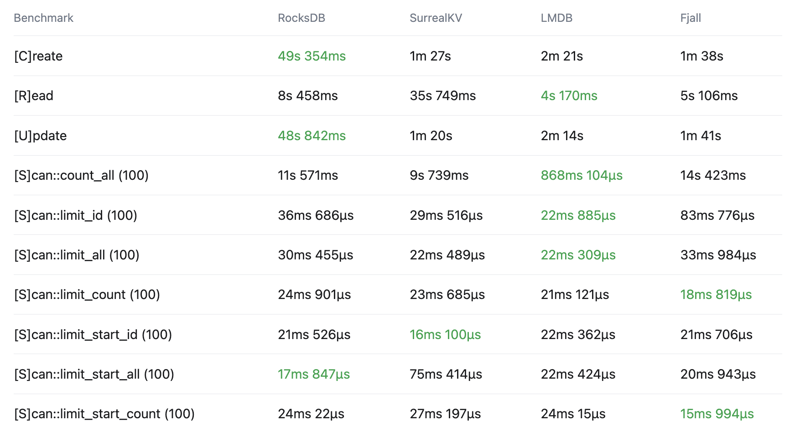
Throughput
Operations per second (OPS) - Higher is better
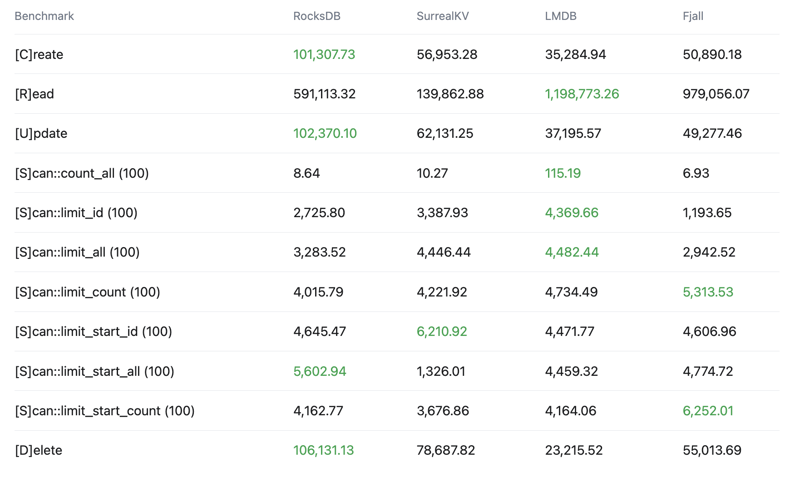
Latency
99th percentile - Lower is better - Top 1% slowest operations, 99% of operations are faster than this
Click here to see the full results
Vector search benchmarks
To help us improve our vector search performance, we started by forking the ANN benchmarks developed by Erik Bernhardsson, which are one of the most popular vector search benchmarks at the moment. We have since expanded on that with tests for all flavours of vector search (MTREE, Brute-Force, HNSW) in SurrealDB. There is still more work to be done, but feel free to look at what we have done so far.
How you can use our benchmarking tooling
We have made our benchmarking repository on GitHub public and you can find all the code and detailed instructions on how to run and contribute to each benchmark there.
https://github.com/surrealdb/benchmarking
SurrealDB can do a lot and this is only the start of our performance optimisation journey!
There is still a lot to do and we are committed to provide a very comprehensive benchmarking environment, and as always, we really appreciate any feedback and contributions. SurrealDB wouldn’t be what it is today without you!

Top comments (0)