
One of the (many) hard things about doing a startup is figuring out what that MVP should be. You are trading off between presenting something that is “good” enough that it gets people excited to use (or invest in) you and getting something done fast. In this article, we explore how we wrestled with this trade-off. Specifically, we explore our decisions around how to use Singer to bootstrap our MVP. It is something we get tons of questions about, and it was hard for us to figure out ourselves!
When we set out to create an MVP for our data integration project, we began with this prompt:
- Create an OSS data integration project that includes all of Singer’s major features. In addition, it should have a UI that can be used by non-technical users and has production-grade job scheduling and tracking.
- Do it in a month.
- Use Singer to bootstrap it.
We knew from the start that in the long run, we did not want Singer to be core to the working of our platform. In the short term, however, we wanted to be able to bootstrap our integration ecosystem off of Singer’s existing taps and targets. So should we make Singer part of our core platform in the beginning to bootstrap? And if so, at what cost?
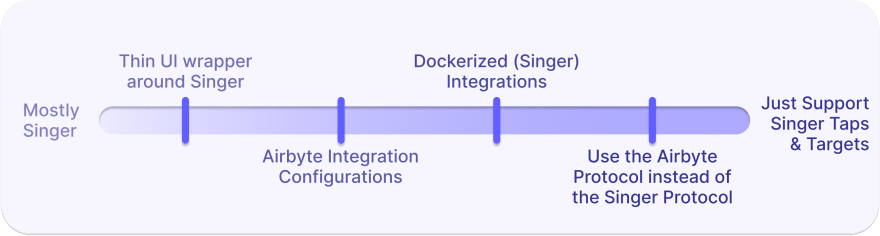
This picture shows the spectrum of options we considered, from wrapping a UI around Singer and relying entirely on it as our backend to shooting for our original goal of Singer as a peripheral.
1. Thin UI wrapper around Singer
This felt like the “startup-y” option. We could throw Singer, a database, and a UI in a Docker container and have “something” up and running in, perhaps, days. We never tried to go with this approach because we were able to see some really big trade-offs.
Pros
- Just a few days in terms of amount of work needed
- No new code for each integration, just use Singer’s.
Cons
- Pretty much all throw-away code after the initial release.
- Because Singer taps / targets don’t declare their configurations (more on this later), there would be no way in the UI to tell the user what values they needed to provide in order to configure a source. We would only be able to accept a big json blob.

While we were going for an MVP, we did not think we would be able to get anyone interested in the first iteration. We also knew that subsequent iterations would be painful, since we would be effectively starting from scratch because the initial iteration was not a sturdy building block. We skipped this approach.
2. Airbyte integration configurations
Given that we wanted to provide a UI experience that was accessible to non-data engineers, our next step was to figure out how we could make it easy to configure integrations in the UI. This meant we had to build our own configuration abstraction for integrations, because this is something that Singer does not provide (we go into more depth on this feature in the first article in this series).
This abstraction was basically a way for each integration to declare what information it needed in order to be configured. For example, a Postgres source might need a hostname, port, etc. This layer made it possible for the UI to display user-friendly forms for setting up integrations. With this approach, we could still rely on Singer as the “backend” for the platform, but we could provide a better configuration experience for the user.

In order to implement this layer, we created a standardized way to declare information about an integration and how to configure it in a JsonSchema object. When someone selects an integration in the UI, it will render a form based on that JsonSchema. The user would then provide the needed information and pass it directly to the backend.
This is ultimately where we started out. And everything was good for about a week…
3. Dockerize Singer integrations
Up until this point, the only thing we had to do per integration was write a JsonSchema object that declared the configuration inputs for an integration. But what if we want the form in the UI to display different fields than those that Singer taps / targets consume?
The first case we ran into was in the Postgres Singer tap. That tap takes in a field called a “filter_dbs” field. This attribute restricts which databases the tap scans when being run in “discover” mode. The tap also takes in a field called ”database,” which is the name of the database from which data will be replicated. In our use case, we wanted “filter_dbs” to be populated with only a single entry, the value that the user had provided for “database.”
In order to hide filter_dbs from the UI, but still populate it behind the scenes, we were going to need to write some special code that executed only when the Postgres Tap ran. But where was that code going to run? The abstraction we had was that our core platform just assumed that all integration-specific code was bundled in the Singer Tap. So we were either going to need to insert this integration-specific code into our core platform or restructure our abstraction so that we could run custom integration code that was not packaged as part of Singer.
Again, we already had a rough idea of what we wanted this to look like in the long term. We imagined each integration running entirely in its own Docker container. Airbyte would handle passing messages from the container running the source to the container running the destination. We had hoped we could get to MVP without it, but ultimately, when we hit this issue, it tipped us over the edge. So we traded some time to figure out how to package Singer taps and targets into Docker containers that made it easy for us to mediate all of the interactions between the core platform and the integration running in the container.
4. Use the Airbyte protocol instead of the Singer protocol
Now fast forward another couple weeks: we are on the night before we plan to do our first public launch, and nothing is working. We have 3 sources and 3 destinations, and not one of them can work with all of the others.
The issue was two-fold:
- We ran into inconsistencies in the Singer protocol that made it hard to treat all Singer Taps and Targets the same way programmatically.
- In falling back on Singer to handle our “backend,” there were implementation details in the way Singer worked that were incompatible with the product we wanted to build.
We won’t spend a ton of time discussing these issues, because we’ve already written about them here. So let’s just say we hit a point where we realized that we either needed to become the world’s foremost experts on the Singer protocol or focus on defining our own protocol. Since the latter already aligned with our long-term vision, we went in that direction.
Ultimately, we tore out our hair and got through that night, and then for our next release we introduced our own protocol. Even at our early stage, this was an expensive endeavour. It took one-ish engineers over a week to migrate us from the Singer protocol to our own (this felt like eons to us!).
Did we do it right?
Obviously, this question is impossible to answer. After reading this article, you might have come to the conclusion that we should have built the first version of our product with Singer at the periphery of our system. And had we done that, we could have skipped the iteration of moving Singer from within our core system to the outskirts. I wouldn’t begrudge you that conclusion!
Had we taken that approach, however, we would have delayed our initial release by an additional month (double time to MVP!). Getting something out early was valuable, because it gave us early feedback that what we were building was interesting to people. We made trade- offs to move fast, but still work from a base that we could iterate on quickly--pretty much the classic trade-off you think about when trying to launch an MVP. And, ultimately, we can’t draw any hard and fast rules other than to use your own judgment!
The unexpected insight that we came away with, however, was that this approach allows us to learn a lot from Singer. Even having Singer be part of the core system for just a few weeks, we got a really good understanding of why they had solved certain issues the way they did.
For example, when we first encountered the Singer Catalog, the use of a breadcrumb system to map metadata onto a schema felt unintuitive and needlessly complicated. The metadata and the schema were in the same parent object, so why did we need this complex system of having the metadata fields index into the schema? Couldn’t they be combined? After using it closely for a few weeks, we understood the complexities that come with configuring special behavior at a field level for deeply nested schemas. Had we gone our own way from the start, we would have learned this lesson much later (and the later we learned it, the harder it would have been to remedy).
Building on top of Singer in the beginning forced us into a Chesterton’s Fence situation. Each time we wanted to do something a certain way, because we thought Singer’s approach didn’t make sense, we were forced to fully understand why Singer had done things the way it did. By doing so, we avoided mistakes we would otherwise have made. We also were able to make decisions different from Singer’s while still benefiting from its experience. All in all, we feel we made the right choice. What do you think?

Top comments (0)