
In the digital age where data is the new oil, search engines have become the compass guiding us through an ocean of information. Google has always been zealous in its mission to “Organize the world’s information making it useful and accessible”. As the internet flooded the globe with data, individuals have progressively emphasized concentrating solely on particular subjects, while reducing diversions from others. From planning a holiday to a self-diagnosis of diseases, search is playing a pivotal role in the modern world for people to make everyday decisions.
With the advent of machine learning in this domain, searching has evolved a lot. Keyword searches have now become neural embeddings that give greater accuracy by finding the context rather than specific words. Search words and tricks are no longer used in search engines as people have moved to queries and conversations. Instead of going for “Travel destinations in Thailand”, users are now going for “Plan me a 3-day tour in Thailand”. Neural embeddings have ushered in innovative searching methods like audio and visual search which would otherwise be difficult. Now machines can easily connect an image with a word as they are embedded in analogous vector spaces.
Social Search
Social media has seen a major part of this search boom as people wanted to tap into the latest trends, topics and updates from their friends, influencers and brands. Facebook came up with advanced algorithms for users to get real-time updates and personalized feed. Instagram came up with hashtags for people to stay close to topics of interest which later went to all other platforms including Twitter. To strike gold in the business, it was imperative to serve users with tailored content in their searches. As social media expanded along with the internet, advances in AI became more and more important to build better recommendation and search engines.
Qdrant

Qdrant is an open-source vector database. This Rust-built platform seamlessly integrates powerful search, matching, and recommendation functionalities into your development workflow. Unlike other vector databases, Qdrant shines with its intuitive API, tailor-made for crafting sophisticated recommendation engines and blazing-fast searches. This developer-friendly approach is further amplified by pre-built client libraries for Python and beyond, seamlessly bridging the gap between your code and Qdrant’s capabilities. Scaling effortlessly with cloud compatibility, Qdrant empowers you to work with diverse data types, opening doors to a world of possibilities for your vector-powered applications.
Prerequisites
The tutorial is tested on these Python libraries. Make sure about the versions while working.
transformers: 4.36.1
qdrant-client: 1.7.0
sentence_transformers: 2.2.2
torch: 2.1.2
pandas
streamlit
Set Up Qdrant
Make sure you have docker installed and keep the docker engine running if you are using a local environment. Qdrant can be installed by downloading its docker image.
! docker pull qdrant/qdrant
Run the Qdrant docker container using the command.
! docker run -p 6333:6333 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
Alternatively, you can start the container from the docker desktop console.
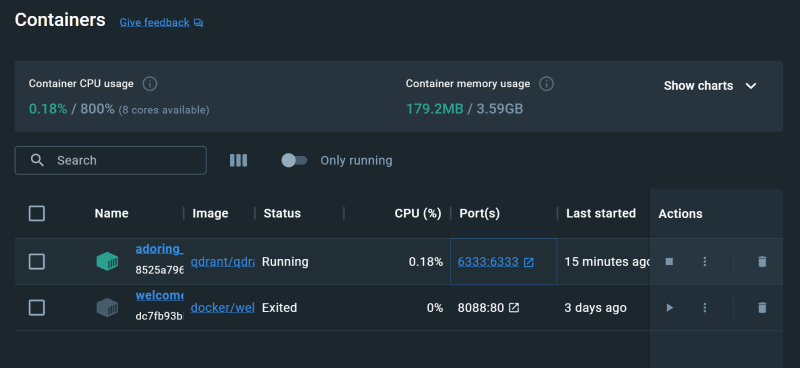
Then only you will be able to start the Qdrant client.
In this tutorial, we will be building a search engine designed to sift through tweets from the FIFA World Cup Qatar 2022.
Populating the Database
I will be fetching the tweets from a dataset in Kaggle. You can also use Twitter API to fetch the tweets in real time. Find the dataset here.
Import the dataset as a Pandas dataframe and isolate only the required columns.
import pandas as pd
import numpy as np
data=pd.read_csv("tweets1.csv")
data = data[["Tweet Id", "Tweet Content", "Username"]]
data

Import the required libraries to create the database. We will begin by creating a collection. In the context of a vector database, a collection is the designated storage area for vector embeddings, documents, and any associated metadata. It’s analogous to a table in a traditional relational database. These collections are specifically engineered to manage data where each entry is depicted as a vector in a multi-dimensional space.
from qdrant_client import QdrantClient
from qdrant_client.http import models
qdrant_client = QdrantClient(host="localhost", port=6333)
collection_name = "FIFA-22"
qdrant_client.recreate_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE)
)
We determine the dimensions of the vectors within this collection. In this case, each vector has 768 dimensions, mirroring the 768-dimensional output of the model we’re employing.
Create Embeddings
Before storing our data in a vector database, we must convert them into embeddings. Embeddings are numerical or vector representations of data which enables them to be represented in a multidimensional space, thus conserving the context and meaning of the data.
The embedding model we will be using here is the all-mpnet-base-v2. It is a high-performance embedding model that maps text to a 768-dimensional vector space. This model is especially beneficial for text data, as it can perform functions such as semantic search, clustering, and assessing sentence similarity, thus offering superior quality embeddings for text data.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-mpnet-base-v2')
Add to Database
Qdrant stores the vectors as points, which have the following structure.
- id: The ID of the document object.
- vector: The embedding vector of the document object.
- payload: The original content of the document object. Iterate through the dataset and convert to embeddings.
points_list = []
i=0
for index, row in data.iterrows():
embedding = model.encode(row['Tweet Content'])
point_dict = {
"id": i,
"vector": embedding,
"payload": {"tweet": row['Tweet Content'], "user": row['Username']},
}
points_list.append(point_dict)
i+=1
Be sure to check the datatypes of id, vector and embeddings before pushing them into the database. If not right, it may show an invalid JSON response error. Store the extracted points to the vector database.
qdrant_client.upsert(collection_name=collection_name, points=points_list)
Search Engine
Now, as the database is created, let’s build the search engine. Import the required libraries for the search engine and the UI.
import streamlit as st
import qdrant_client
from sentence_transformers import SentenceTransformer
Define the collection we will be searching for in the database. Use the collection we just created above.
# Connect to Qdrant
qdrant_client = qdrant_client.QdrantClient(host="localhost", port=6333)
collection_name = "FIFA-22"
Define the embedding model for converting the queries.
model = SentenceTransformer('all-mpnet-base-v2')
The query in the search bar will be converted to embeddings using the same model we used to embed the data.
query_vector = model.encode(search_query, convert_to_tensor=False)
Qdrant offers a wide range of high-speed and efficient APIs for performing search and retrieval operations. Use the search function from Qdrant to search through the embeddings. This function compares each embedding to the query embedding using cosine similarity approach. This feature from Qdrant is very efficient in computing similarities between vectors and fetching similar contents.
results = qdrant_client.search(
collection_name=collection_name,
query_vector=query_vector.tolist(),
limit=3
)
The parameter limit is set to 3 — to show only the top 3 matching results. The query embedding is converted to a Python list before using it in the search function.
Combine the search engine into a simple UI using the Streamlit library in Python. Feel free to use your own approaches to display the search bar, results, and other elements in the UI.
qdrant_client = qdrant_client.QdrantClient(host="localhost", port=6333)
collection_name = "FIFA-22"
model = SentenceTransformer('all-mpnet-base-v2')
st.title("Qdrant Search Engine")
st.subheader("Search through the voices from FIFA World Cup 2022 in Twitter ⚽🏆✨")
search_query = st.text_input("Enter your search query:")
if search_query:
try:
query_vector = model.encode(search_query, convert_to_tensor=False)
results = qdrant_client.search(
collection_name=collection_name,
query_vector=query_vector.tolist(),
limit=3
)
# Display results
st.write("Search Results:")
for result in results:
st.write(f"- Tweet ID: {result.id}")
st.write(f"- Tweet Content: {result.payload['tweet']}")
except Exception as e:
st.error(f"Error occurred during search: {e}")
Run the file using the command.
! streamlit run filename.py
Here are some results.
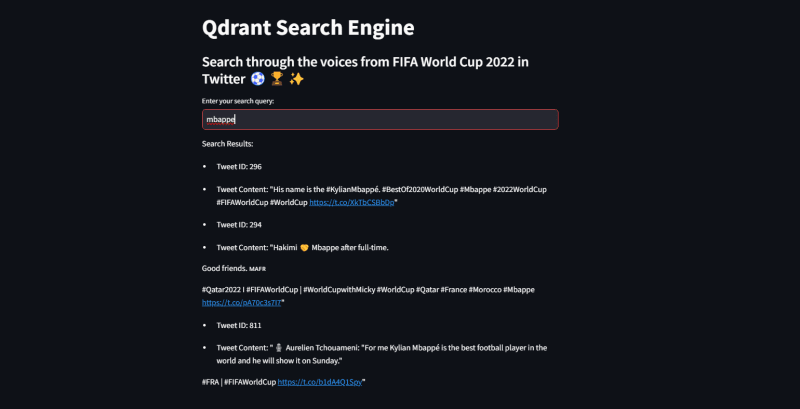
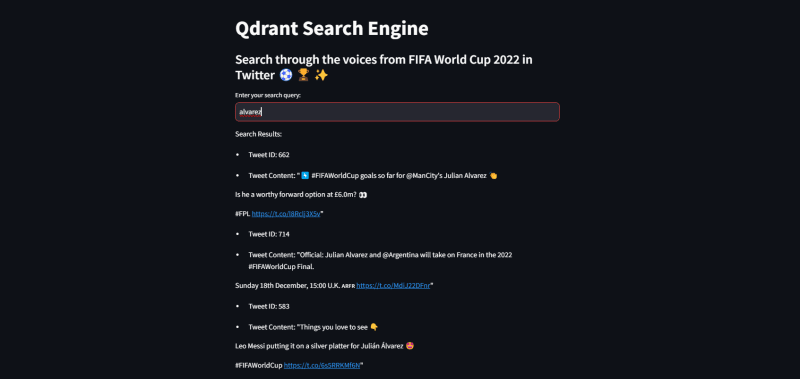
Wrapping Up
You have learned how to build a simple search engine using the Qdrant vector database. The powerful APIs allow for efficient and effective searching through large amounts of data. I encourage you to try out other functions and algorithms offered by the Qdrant discovery API for optimizing the search results. Hope you found it useful! Feel free to share your thoughts and feedback.😊
👉 LinkedIn
✏️ Checkout my blog on Medium
References
Qdrant Documentation
Sentence Transformers
Steamlit Documentation

Top comments (0)