As systems/software engineers, learning a new tool or framework sometimes is not the hardest part of our “technological life”. We likely need to get used to some new concepts, and terms regarding this tool/framework, and, of course, learn how to use it. We usually get this part done quite fast. But, after that, we start wondering… ok, now that I know how to use it, it comes to… How organize my projects with this new tool? Should I use this or that structure? Are there some practice/patterns out there already?
To sum up, in our context, in our reality, how to make the best use of this tool so that it helps more than it causes problems?
So, there’s no other way, more work to do… start the research, checking the community experiences, practices (the good ones, as well as the bad ones), suggestions, outcomes, everything! Collecting data and processing to adapt to our needs (context) we start to build our own way to work with this “new” tool/framework.
That’s my objective with this two-part article series: build a blueprint model to show a way how to model, organize and structure our Infrastructure-as-Code Projects using the AWS-CDK framework. So, let’s begin with the first part.
Quick brief about AWS Cloud Development Kit (AWS CDK)
It's a set of libraries, considered a framework, for defining infrastructure in code and provisioning it through AWS CloudFormation. One of the most attractive advantages of AWS CDK is that you can use (your) "real" language, making use of loops, functions, conditionals, parameters, classes, inheritance, composition… everything that we usually use to build software, we can use to build our infrastructure. Besides, you can choose the programming language that most suits you, the AWS CDK is available in: TypeScript, JavaScript, Python, Java, C#/.Net, and Go (behind this is the jsii) - it brings AWS CDK the ability that with the same source code delivers a polyglot library). Here, we will use Python.
We can design reusable components known as Constructs, and then define our infrastructure composing them together into Stacks and Apps. The objective here is to build our AWS CDK Blueprint model, so, very quickly and brief, a few of the concepts involving AWS CDK:
- Constructs: The basic building block of AWS CDK Application, it represents a "cloud component" with the resources/services to be created by AWS CloudFormation. AWS CDK includes a collection of them, for every AWS Service (known as AWS Construct Library). Also, check the Construct Hub, which is a good place to help you discover additional constructs from AWS, third parties, and the open-source CDK community.
- Stacks: they are deployment units, all resources in a Stack are provisioned as a single unit.
- App: it represents an entire CDK application (also considered a Construct), usually the root construct of the application.
- Stage: a representation of an abstract application modeling, that will consist of Stacks that should be deployed together. We then create instances of this Stage multiple times, each by the distinct environment we need to deploy our application.
Ok, I agree only reading this is a little boring, those concepts will be more cleared after we go through our blueprint sample projects, the hands-on part.
The Solution, Modeling, And Organizing
The solution is called AWS Skills Mapping, it shows the experience level of a professional in each one of the AWS Services:

We have two projects here, one is a simple AngularJS Project (the Application - previous image), and the other is an AWS CDK Python Project (the Infrastructure as Code - IaC). The AWS CDK Project will be in charge of building the environment for this AngularJS Application to be deployed and run. Besides the creation of the resources and services needed in AWS Cloud, the AWS CDK Project will also create a CI/CD Pipeline (CodePipeline, Codebuild) for the application deployment.
AWS CDK Project Modeling
This is the design model of our IaC AWS CDK Project. We have defined three Logical Units that compose our application in separated Cloud Components (Constructs): API, Database, and WebSite. Then, we create a Stage (an abstract App) which we split into two separate Stacks: Stateful and Stateless. This way we can separate components that we may be concerned about data, the Stateful (e.g. s3, database), from the other one, the components that are probably easier to reproduce (e.g. api, mq, sns, lambda).
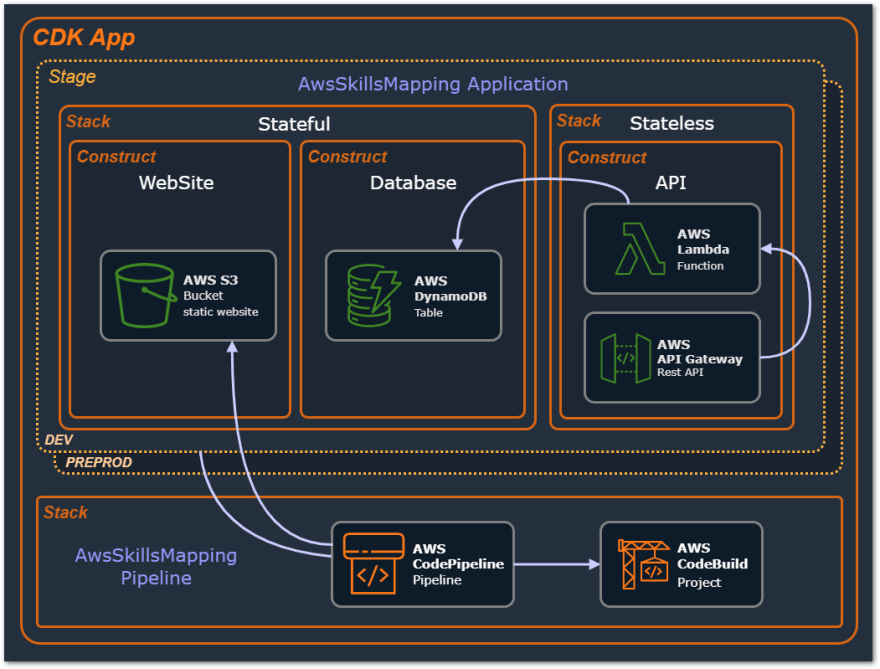
The Stage (Python class that inherits aws_cdk.Stage with two aws_cdk.Stacks: Stateful and Stateless) will be instantiated and loaded with different configurations/environment information for each distinct Stage: Dev and Preprod.
AWS CDK Project Structure
Let's take a look at the structure and organization of our AWS CDK Project, it will follow the defined design model that we have seen.

The most relevant parts of the structure are divided in the image above into three sections. At the first section (1), we have the code that actually builds the cloud components, resources, and services we need for each Logical Unit of the Application. For example, in the API folder (API Logical Unit), we have our aws_cdk.Construct (a Python class named ApiAwsSkillsMapping) that creates an API Gateway and Lambda Function already interconnected, this way we create a higher-level Construct composed of two others. Also, at the runtime subfolder, we keep the necessary asset for this LU, the Lambda Function code.
In the second section (2), we have every information configuration externalized in YAML files, split by Stages, and an extra one for the Pipeline. Here is a sample of their contents:
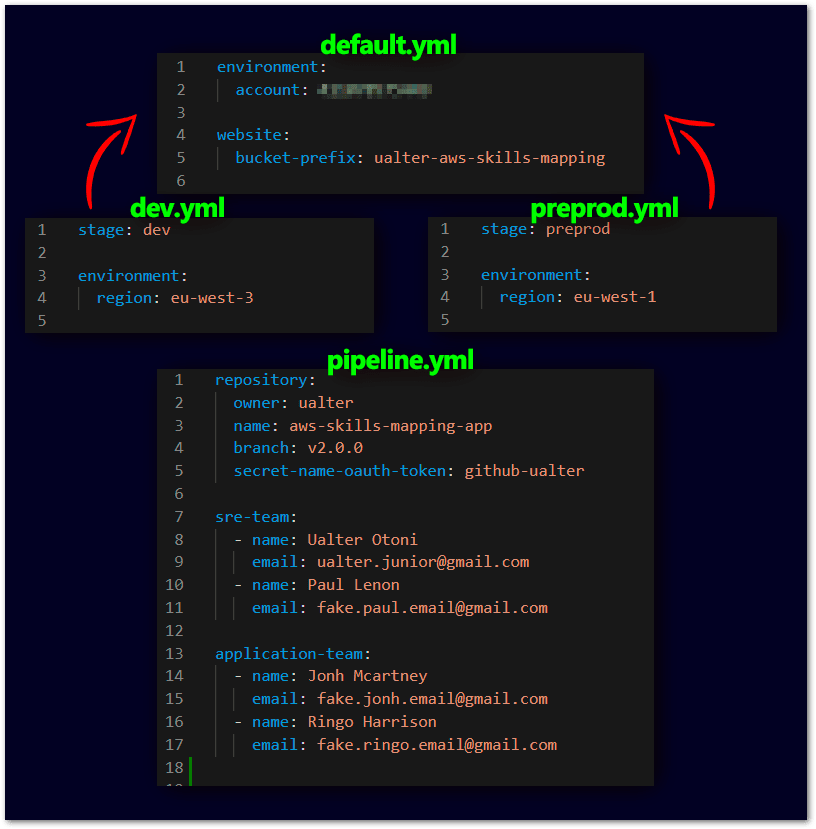
At the default.yml file we keep all the common values (like bucket-prefix), and the specific for Stage in its respective file (like bucket-suffix-name). Later on, in our hands-on, we are going to deploy to the same AWS Account the Stages Dev and Preprod, but at distinct AWS Regions (Dev/eu-west-3/Paris and Preprod/eu-west-1/Ireland). When creating the Pipeline for the AngularJS Application CI/CD, let's create an Approval step, right after the deployment in Dev, but before the deployment in Preprod. The teams and emails that need to approve the Preprod's deployment are informed in the pipeline.yml file.
Lastly, in the third section (3) of our project structure, we have a short description of some of the most relevant Python classes that are part of all the code that actually makes up our AWS CDK Project.
AWS Cross-Region Dependencies
For dependencies between Stacks at the same AWS Account/Region, the CDK identifies their existence and is able to handle them by itself. For instance, looking at the design model of our AWS CDK Project, we can see that DynamoDB and Lambda are in different Stacks (DynamoDB at Stateful, and Lambda at Stateless), and we need that the Lambda Function to be granted the authorization to read the DynamoDB Table.
In this case, we can, either reference them directly in the code or make use of the aws_cdk.CfnOutput("NAME") to export in one Stack, and then cdk.Fn.import_value("NAME") to import at the another Stack. Recall that for each AWS account, export names must be unique within a region.
Now, in another trickier situation, we need to adopt a different strategy. In our sample, the problem is this... at the Pipeline Stack, while creating the Codebuild Project, we will need the generated API Gateway URL (https://{restapi_id}...) for each one of the Stages (Dev and Preprod), in order to build the AngularJS Application properly (see side note below).
Notice! We are using an S3 Static Website to host our AngularJS sample project, we do not have the option of "inject" Environment Variables to be used during Runtime, because S3 is a static object store, not a dynamic content server, so there's no such a thing like "Server Runtime" (in this case). This is the reason, why we have to have a Build Stage for each environment, to set up different variable values by each environment, we have to configure them at "Build time". Besides, remember, that AngularJS is purely client-side code (it runs in the browser).
In the case of the Preprod, the Stack which has the API Gateway is located at eu-west-1 (Ireland), and the Stack which has the Pipeline is located at eu-west-3 (Paris) AWS Region. So, how can we share this information between two Stacks in different AWS Regions? For that situation, we use the service Parameter Store from AWS Systems Managers, (see next image). First (1), at the first Stack (the one with the source of the dependency) we save that information at Parameter Store in its own AWS Region, then (2), at the other Stack (the one that depends on it) we read it at the Parameter Store in the AWS Region where it is stored.

Notice, in this situation, obviously, we need to take care of the sequence we deploy our Stacks, handling them in the proper order, first the one that creates the parameter and later the one that reads it.
Conclusion (Part 1)
Ok, for now, let's stop here, recalling that, up to this point we have met the sample Application, seen the design model of our AWS CDK Project, and known the structure, organization, and external configuration implemented in this AWS CDK Project. Also, we have seen in some detail how we handle dependencies among AWS CDK Stacks located in different AWS Regions.
In the next (and last) part of this article, the fun part comes, we will get into the hands-on, deploying all the resources and see the AngularJS application up and running in both stages, Dev and Preprod. See you soon.
And, of course, the source code will be already available there too.


Top comments (1)
Great explanation! Can't wait to read part 2. Kudos!