
Large language models (LLMs) are great, but sometimes they need a little help finding the right answer. Enter retrieval-augmented generation (RAG) systems and knowledge graphs. Today, I’m sharing how I used LightRAG with Amazon Bedrock and Ollama to build a knowledge graph from congressional records.
The result? A tool that makes it easier to sift through the details of legislative discussions and extract key information (or... just a fun excuse to tie together some of my recent favorite tools).
Full source code can be found in the GitHub repo.
What’s Cool About This Setup?
-
Amazon Bedrock gives you quick, affordable access to several foundation models (like the cost efficient
amazon.nova-lite-v1:0) without the headache of managing GPUs or scaling issues. - Ollama helps generate embeddings locally—perfect for offline projects and keeping vendor-lock at bay (just remember, if you go fully offline, you’ll need a local LLM in place of Bedrock for prompt responses).
- LightRAG a performant, lightweight alternative to Microsoft's GraphRAG to get starting with local graphs quickly.
What’s LightRAG?
LightRAG enhances RAG systems by integrating graph structures into text indexing and retrieval processes. In simple terms, it better connects related pieces of information, giving more accurate and quick answers. By combining graph relationships with vector-based retrieval, LightRAG pulls in context from both low-level details and high-level insights. An incremental update algorithm ensures your data stays fresh, making it a great choice when data is continuously evolving.
The Project Data
I used one day of congressional record data—a full transcript of legislative discussions. Using a knowledge graph here lets you ask meaningful questions like:
- “What were the key legislative actions in this session?”
- “Which topics dominated house debates?”
Getting Started
Prerequisites
- An AWS account with Amazon Bedrock access
- Ollama installed (download it here)
- Python 3.10
1) Install Dependencies
Clone the repository from GitHub and run:
pip install -r requirements.txt
2) Configure AWS Credentials
Create a .env file with:
AWS_ACCESS_KEY_ID=<your-access-key-id>
AWS_SECRET_ACCESS_KEY=<your-secret-access-key>
AWS_SESSION_TOKEN=""
3) Grant Access to Amazon Models
Follow the steps in the Amazon Bedrock documentation to request access to Amazon Foundation Models.
4) Pull the Embedding Model
Run:
ollama pull nomic-embed-text
Using The LightRAG CLI Wrapper
bedrock_graph.py is my CLI wrapper that operates in two modes:
Populate Mode
Load data into your knowledge graph.
For a directory:
python bedrock_graph.py --mode populate --working_dir ./cr_data --path ./cr_data_graph --llm_model_name amazon.nova-lite-v1:0
CLI Mode
Query your knowledge graph interactively:
python bedrock_graph.py --mode cli --working_dir ./cr_data_graph --llm_model_name amazon.nova-lite-v1:0
Example Query:
>> What were the key legislative actions for republicans?
... <response was here> ...
#### References
1. [KG] H.R. 2113 (File: ./cr_data/CREC-2025-03-14-pt1-PgH1158-3.txt)
2. [KG] H.R. 2115 (File: ./cr_data/CREC-2025-03-14-pt1-PgH1163-4.txt)
3. [KG] H.R. 2093 (File: ./cr_data/CREC-2025-03-14-pt1-PgH1162-3.txt)
4. [KG] H.R. 2145 (File: ./cr_data/CREC-2025-03-14-pt1-PgH1163-34.txt)
5. [KG] H.R. 2121 (File: ./cr_data/CREC-2025-03-14-pt1-PgH1163-10.txt)
One of the best things about LightRAG is its source citing capability.
A Quick Note on Customizing Bedrock Calls
By default, LightRAG's bedrock class uses anthropic.claude-3-haiku-20240307-v1:0. This is great if you're only analyzing a small amount of data - but I'll quickly rack up my AWS bill trying to analyze an entire year's worth of congressional records (stay tuned for the results of that project).
To adapt this for Amazons's cheaper foundation models, I needed to overwrite the bedrock_complete function as follows:
async def bedrock_complete(
prompt, system_prompt=None, history_messages=[], keyword_extraction=False, **kwargs
) -> str:
"""
Complete the prompt using Amazon Bedrock.
Replacement for lightrag.llm.bedrock.bedrock_complete to use any Bedrock model.
"""
keyword_extraction = kwargs.pop("keyword_extraction", None)
llm_model_name = kwargs["hashing_kv"].global_config["llm_model_name"]
kwargs.pop("stream", None) # Bedrock doesn't support 'stream' kwarg
result = await bedrock_complete_if_cache(
llm_model_name,
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
**kwargs,
)
if keyword_extraction:
return locate_json_string_body_from_string(result)
return result
This function is what I use when initializing LightRAG() instead of the built-in lightrag.llm.bedrock.bedrock_complete
Exploring the Graph
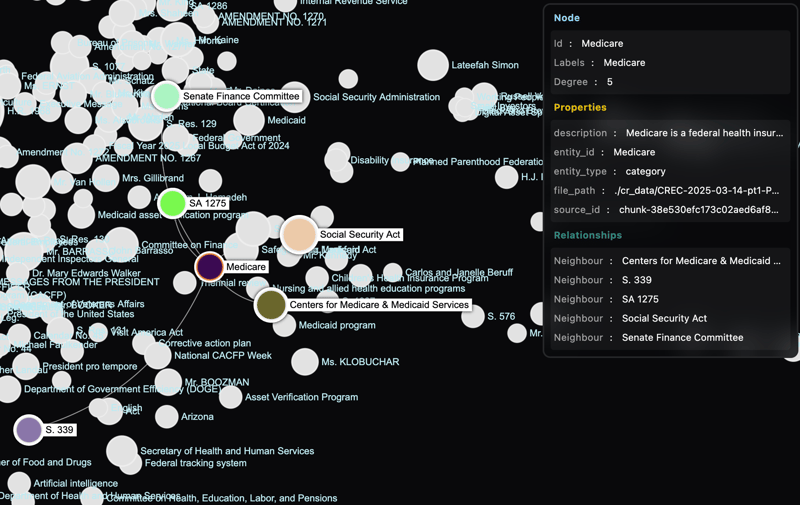
Once you have your knowledge graph populated, you can start exploring the data visually. This part is less useful but honestly much more fun to interact with for me. I generated some screenshots with the LightRAG API (find more info here) to show how data can be visualized.
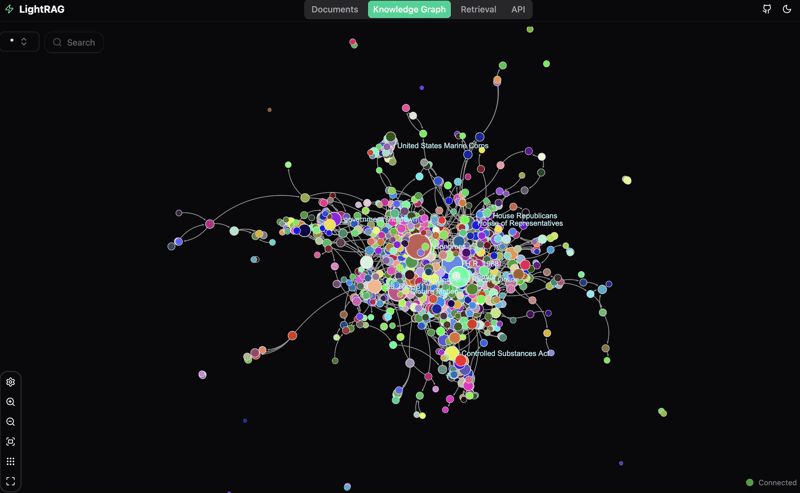
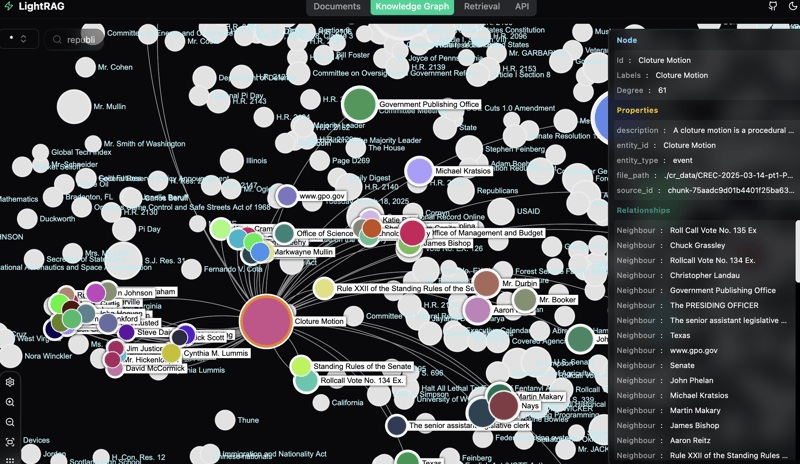
I could seriously explore the relationships in this graph for hours...
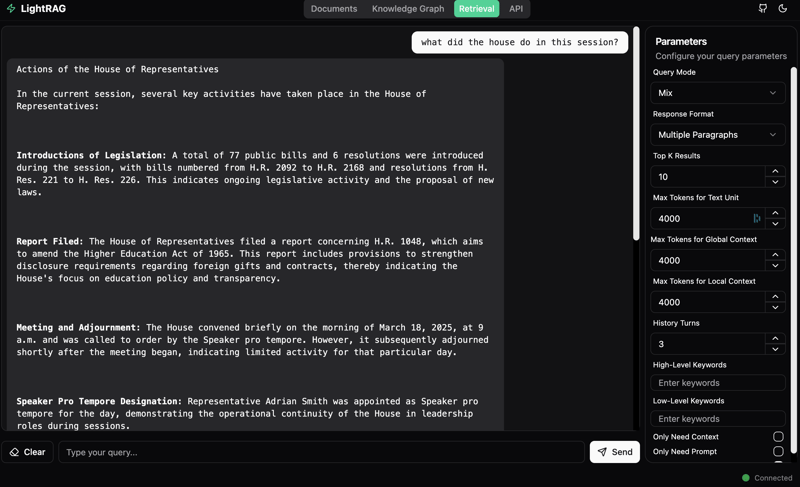
You can also ask questions directly in the UI provided by the LightRAG API.
GraphML Export
One of the benefits of this setup is that the knowledge graph is stored in GraphML format. This makes it super easy to export, integrate, and query the data in other programs or databases. Whether you’re looking to analyze the graph with advanced graph tools or simply want to load it into a relational database for further use, GraphML provides a standardized, widely-supported way to do so.
<node id="U.S. Department of Commerce">
<data key="de">U.S. Department of Commerce</data>
<data key="d1">organization</data>
<data key="d2">The U.S. Department of Commerce is a federal agency which</data>
<data key="d3">chunk-e8c54b412ebbce72580d58073ce0497d< SEP>chunk</data>
</node>
Example node output in GraphML that will be in your ‘working_dir’
Note on Current Development
Keep in mind, LightRAG is still in development. You might notice some hallucinations in entity and relationship outputs - Nodes such as "Tokyo" and "World Athletics Championship" persist - even with larger models, these are artifacts of the one-shot examples in the system prompts. I have faith this will improve as the project evolves (or do it yourself with DSPy).
Wrapping Up
It's entirely possible to build knowledge graphs using LightRAG and Amazon Bedrock foundation models. Doing so greatly increases the accessibility and richness of the data for LLMs. Plus, by utilizing smaller models like Nova Lite, we can save a significant amount on token costs while preserving integrity.
Whether you're diving into congressional records or another data set, this approach shows promise in making data retrieval smarter, faster, and cheaper.
If you found this guide useful or have any questions, drop a comment below. Happy coding!

Top comments (0)