
Photo by Art Wall - Kittenprint on Unsplash
Introduction
We live in extraordinary times where technology is part of everything. One of the things that have made technology so powerful and valuable is data. A vast amount of data is generated every day on the internet. Consider the data generated on Instagram alone:
- 500 million Instagram stories are uploaded everyday
- 3.5 billion likes are recorded daily
- As of 2016, 95 million posts are made every day, and Instagram usage doubled between 2016 and 2018.
This massive amount of data (called big data because of the size) cannot be stored using traditional techniques or on one machine. Storing and retrieving big data requires multiple interconnected machines. This article focuses on the different techniques of storing big data and their pros, cons, and use cases.
Types of Data
Before diving into the different types of data storage, we must first look at the types of data.
Structured Data
Structured data is anything that you can easily store in an excel spreadsheet, such as user first name, last name, bank details, etc. Such data usually has a defined length and format. On the internet, structured data is generated by both humans and machines. Some sources of this data are listed below:
Human
- Filling your details or information on a form
- Behaviour while watching videos online. For example, the site tracks the timestamp/episode you left the video at last.
Machine
- Sensor data from your IoT devices or smartphones like your GPS location, battery life, and so on
- Application logs, which help engineers figure out what errors exist in their platform or how efficient their system works.
Structured data accounts for about 20% of all the data on the internet and is usually easy to analyze to derive meaningful insights.
Unstructured Data
Unstructured data does not have any predefined format or model. You will usually not find a lot of similarities between 2 objects of this type of data. Classic examples of unstructured data are videos, images, audio, etc. If you were given two audio files, the difference in the author’s voice alone leads to a considerable difference between the two files. Like structured data, unstructured data also has its human and machine sources. Some of these include:
Human
- Posting that morning sunshine image on Instagram
- Updating your WhatsApp status with a comic video
- Live streaming on social media platforms
- The last PDF you exported
Machine
- Images of the earth taken from a satellite
Analyzing unstructured data is more complex and usually involves creating machine learning models. This data comprises about 80% of the data on the internet and has become easier to store and maintain.

Semi-structured Data
I like to think of this type of data as a kind of hybrid of both the above-mentioned types. It usually contains a structured part and an unstructured part.
Some examples of semi-structured data are emails and word documents. Notice these contain text (structured data) and media files (unstructured data). Think now of the data stored in NoSQL DBs in which one item has a certain number of fields, but the next does not—that is a semi-structured dataset. Notice that an email has the to, from, cc, and bcc fields, which are structured data, but it may also contain images.
How to Store Data
Now that we have familiarised ourselves with the different types of data, we can look at the various methods of storing this data.
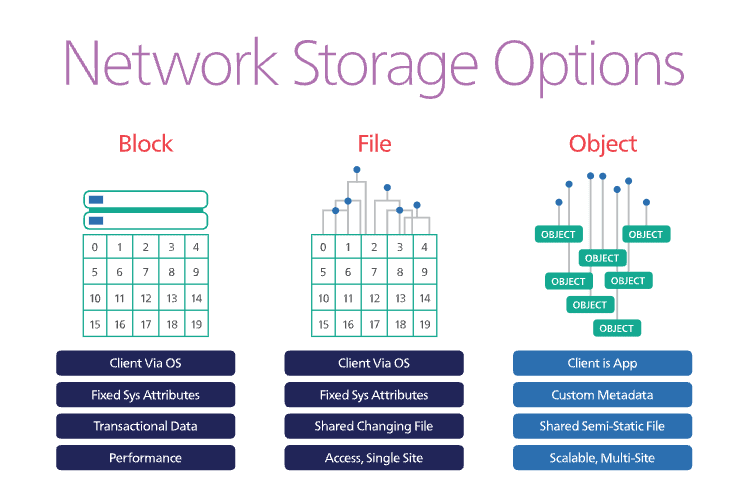
File Storage
In this type of storage, data is stored in data form on a disk. Anyone who wants to access it has to know the file path of the information on the disk. Some other characteristics of file storage include:
- Files can simultaneously be read and written.
- Only users on the same network can access them.
- It is not easy to replicate your data—you might lose data in case of machine failure.
Block Storage
In block storage, data is stored as a contiguous chunk (called a block). It allows us to spread our network easily across different networks, and you don’t need to know where it is stored on the disk to access it. Relational databases are examples of RDMS, making it the best type of storage for structured data.
Other characteristics include:
They are highly scalable: You can increase the size of your block storage by adding more nodes to your network, thus making it easy to scale.
Easy to replicate: Most block storage services are easy to backup/replicate. Thus, in case of machine failure, your data is still intact.
Reads and writes are fast, and you do not need to know where the data is on disk.
Block storage is generally expensive as the data increases. This makes it expensive for data that is large, for instance.
Object Storage
Object storage is the most suitable way of storing unstructured data. The data is usually stored as an “object”.
An object is made up of 3 main parts:
- The data: This is the image, picture, etc., that we want to store.
- Metadata: This can be a description of what this data stands for. Most object storage services allow us to search the content of this metadata.
- Unique Identifier: This can be used to retrieve the object easily at any point.
Anytime an object is created, most services replicate it three times. This makes it easy to retrieve the object and search for the data. Thus, object storage is ideal for storing unstructured data as it can easily be accessed using an ID.
Advantages of object storage include:
- Way cheaper than other types of storage
- Data replication comes in by default
- Rich metadata feature
- The storage is not coupled to a machine and thus is easy to scale
- Grouping of data can be done using a metadata value
Conclusion
In this article, we looked at the different types of data in big data and explored the main techniques of storing big data. I hope you learn something new from this article.

Top comments (0)