
With this new release we’re rolling out some cool new features that will help you boost your productivity working with your Kubernetes clusters.

Dynamic Tables
Tables on Kubernetic resources were previously with a fixed number of columns. Now tables columns are received from server-side making them dynamic and in par with kubectl tables. By default the same columns as shown with kubectl will appear on screen, but you can also enable extra information by opening the Display dropdown, there you can find all the extra columns that can be found when running kubectl -o wide.

This works well for all standard resources that support tables server-side (Pods, Deployments, ConfigMaps etc.) as well as for custom resources (CRDs) which can define their own table columns.
Some resources do not support table format or didn’t in older versions (e.g. Roles, RoleBindings etc.) on those cases the fallback to generic columns (Name, Age) is displayed.
Older Kubernetes versions (before v1.15.0) didn’t support Tables (v1) format, for those we fallback to v1beta1, but in order to gain ability to stream dynamic tables on real-time you’ll need v1.15.0 or newer.
Real Time updates
Talking about streaming, we re-designed the way streaming works with primary focus on productivity. This re-design was incrementally done during the last releases bringing it to completion with the v3 release and the result is stunning! Let me explain…
On previous versions Kubernetic when connecting to a specific namespace it opened a websocket watching for updates on specific list of resources, which were cached locally on client, a common pattern on the landscape of kubernetes clients. When user switches namespace the connection pool is closed and another is opened. The problem with this approach is that it doesn’t scale as well since it watches resources that are not needed yet, and while your client may mirror the entire kubernetes API store per-namespace, or globally, there is a leaner approach that watches resources as-needed.
Kubernetic is composed of two components a frontend which is React based and a backend which written in Go and acts on behalf of the frontend. The backend has a Table format go-client implementation that supports all edge cases described above to perform fetches and watches while also prefetches the discovery of custom resources with cache invalidation on miss so that it refreshes automatically, this makes it even faster that kubectl itself as a UX (which also uses discovery cache mechanism)! The fetch and watch are separated so that users with list privileges can still operate without the need of watch privilege on the requested resource. On frontend side we use react-query for local caching of the resources so that they are displayed while a new request in in-transit. Each component on React has the ability to request resources with deduplication of requests done nicely by the react-query itself. For streaming we used to use websockets, but with v3 we switched to Server Sent Events (SSE). Websockets are cool for bidirectional unstructured data streaming and we still use them for Terminal emulation, but we found that SSE are better suited for doing watching of resources as they provide a unidirectional event streaming flow avoiding the need to separate JSON objects on the data flow (React-query doesn’t support SSE out-of-the-box so we implemented the integration on-top).
So how fast is this? Let me demonstrate:

For comparison here is the kubectl response time at 395ms, after a few requests so that discovery cache is prefetched:
❯ time kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
example-1 5/5 5 5 12m
example-2 10/10 10 10 12m
example-3 10/10 10 10 12m
example-4 10/10 10 10 12m
example-5 10/10 10 10 12m
kubectl get deployments 0.10s user 0.04s system 35% cpu 0.395 total
And here is the web request to refetch same resources at 66ms:

Rich Column Formatting
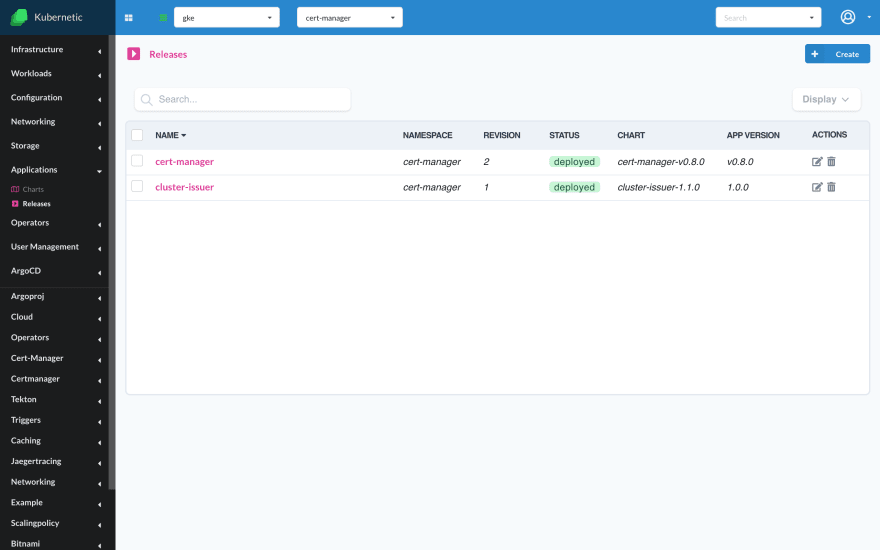
Each column can be formatted separately providing subtle visual hints of well-performing resources or not. Below you can see the helm releases and their status is visually hinted that the resources are deployed ok.
Better DX — an alternative to YAMLs
A lot of people have a love-hate relationship with YAMLs. Personally I like the YAML format, but when there are better alternatives instead of unstructured formats that help me get a better developer experience by guiding the way and avoiding missteps I will take advantage of them.
Below is an example how to build your kubernetes YAMLs without deep-diving in Kubernetes YAML formatting. We create a ConfigMap, a Secret and then a Deployment of nginx:alpine image that mounts them under the /usr/share/nginx/html/ directory, we scale the deployment up to 3 instances, see the logs of all three instances, exec in one of the deployment Pods to see the mounted directories, and port-forward to see the content of the ConfigMap and Secret through nginx, all under 60 secs:

What’s on the Roadmap
There are a lot of features that are on the roadmap, the most important ones where we’ll focus next are the following:
Dark Mode: Now that we migrated to use of TailwindCSS for the UX we can finally take on the most voted feature request, dark mode theming is coming!
- Resource counters on Menu: Previously we had counter of resources on the menu which we had to remove it as we do the streaming redesign, now we have a clear path how to re-introduce it in next releases.
- CPU/Memory usage consumption: This is another feature we had to remove temporally with the new table design, we’ll be re-introducing usage consumption on resources (Pods, Deployments, Nodes etc.) along with rich formatting for visual queues.
- Tekton integration: Support for designing and running Tekton Tasks and Pipelines is coming up soon.
- ArgoCD integration: Support for designing and managing ArgoCD applications is coming up soon.
If you like what you see you can download trial version for 30 days for free from the website and supercharge your Kubernetes foo powers.

Top comments (0)