
Every time a coding agent underperforms, the default move is to swap in a bigger model. I wanted to see what happens if you refuse that move and fix everything else instead.
The result: 61.6% ± 1.9 on Terminal-Bench 2.0 with GPT-5.1-Codex-Mini — rank #41, in the same band as stock harnesses running flagship models a tier or two larger. 445 runs, $27, ~35 hours.
This is not an argument that small models are secretly enough. It is an argument that the wrapper around the model is doing more work than most people give it credit for — and that you can see this clearly only when the model is small enough that harness mistakes actually hurt. What follows is a teardown of what survived.
Reading the number
The score is verified on the official leaderboard at rank #41 as of May 14, 2026, across 89 tasks with 5 runs each. Leaderboards move, so I treat the rank as a timestamped snapshot rather than a permanent claim. The useful comparison is the neighborhood around that snapshot: entries immediately around rank #41 run on GPT-5.2, Claude Opus 4.6, and Gemini 3 Pro.
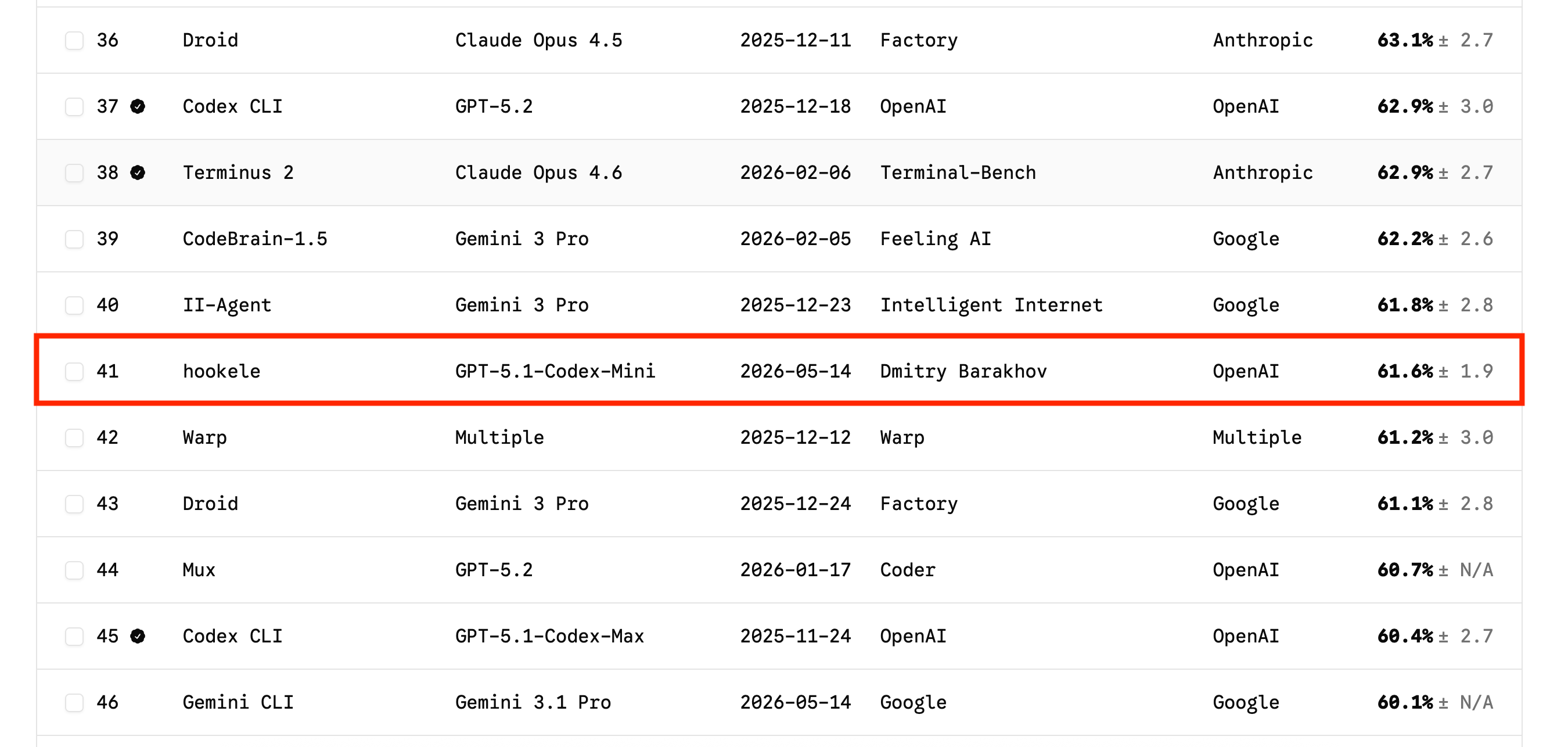
The wrapper, in other words, moves a smaller model into the same band as larger ones. The ±1.9 confidence interval comes from 5 runs per task across 89 tasks — wide enough that I treat the score as a band, not a precise rank, but tight enough that I do not think any one lucky trajectory is doing the work.
One of the improvements that stood out during local iteration was something almost embarrassingly small: a 100-token classifier call at the start of each task that picks which Markdown skill files to drop into the system prompt. I do not have a clean 445-run ablation for every variant, so this is an engineering observation rather than a controlled benchmark result. Everything else (streaming retries, the V4A patcher, tool-output capping) is supporting structure that lets one loop keep moving without falling over.

A one-time skill router picks which Markdown playbooks get appended to the system prompt; after that, a single model runs a loop against seven tool entries. Side-effecting tools (run_command, apply_patch) mutate the Terminal-Bench container; read-only tools (search_docs, get_docs, web_search) do not. A context policy caps tool outputs and preserves failures verbatim before they re-enter the model.
What Terminal-Bench actually is
Terminal-Bench 2.0 drops your agent into a hardened container with a task instruction and a terminal. That is the whole interface — no iteration cap, no filesystem visibility from outside, no retries. If you want any of that, you build it yourself. Eighty-nine tasks span chess-engine guidance, R-to-Python Stan migrations, QEMU bring-up, hash cracking, Core Wars, CSV surgery via Vim macros, and a long tail of things that look obscure until they bite you.
I picked it because frontier labs cite it themselves: it shows up in OpenAI's GPT-5.5 announcement and in Anthropic's Claude Opus 4.7 post as a headline coding-agent score. A benchmark that labs use to grade their own flagships is a reasonable place to test whether a small model can punch up. Runs go through Harbor, the evaluation framework Terminal-Bench 2.0 standardized on.
Why a small model in the first place
If the model is already the largest one available, every improvement is hard to attribute: did the harness help, or did the model muscle through? With a smaller model, harness mistakes show up quickly. Bad tool design, noisy context, fragile editing, and over-planning all become visible because the model has less slack.
Hookele started from OpenAI's GPT-5.1 coding agent notebook, which wires run_command, apply_patch, web_search, and Context7 docs lookup (a third-party library-documentation service) into the Responses API. The cookbook walks through the happy path. What follows is what happens when the happy path breaks: streams that drop mid-reasoning, diffs that fail to apply because context drifted by two characters, models that stall for 40 iterations without doing anything productive.
The loop
Hookele is one model in one loop. On the first turn the executor calls update_plan with 3–5 short steps and nothing else; after that the plan lives in the context window and the model can rewrite it whenever the approach changes. Every subsequent turn is a tool call against the same seven tool entries: run_command, apply_patch, update_plan, search_docs, get_docs, web_search, task_complete. No router, no state machine, no separate planner. The cap is 60 iterations by default, but most successful runs finish in under 20.
This is what survived deletion. An earlier version had a gpt-5-mini planner that emitted JSON with approach and tools_needed to constrain the executor. It misclassified about one in five tasks — usually deciding "no file editing needed" on tasks whose solution was a small file edit — and the executor would dutifully not edit files. I removed it. The same pass took out a five-state scan→plan→act→verify→stop machine, an acceptance-criteria extractor, automated criteria evaluators, and dual-model routing. None of them survived contact with the benchmark. Each one had looked principled in isolation and added nothing the executor could not infer for itself.
The tool surface got similar treatment. list_files and read_file came out because run_command already does both through ls and cat, and exposing duplicate tools just gave the model another decision to make on every turn. Tool outputs are capped at 20K characters, head + tail, so a chatty npm install cannot drown the context. Fewer tools means fewer decisions about which tool to use, which means more turns spent on the actual problem — and on a small model, every saved turn is real.
The two pieces of low-level plumbing under the loop that actually earn their keep are the V4A patcher and the streaming layer.
The patcher
Every edit goes through one tool: apply_patch. I standardized on it instead of a generic edit or write because Codex models are trained directly on the V4A patch format, and because structured diffs are easier to validate, retry, and explain than arbitrary file writes. V4A is OpenAI's diff envelope for Codex-family models — in Hookele, one payload can create, update, and delete files in a single call:
*** Begin Patch
*** Add File: hello.txt
+Hello world
*** Update File: src/app.py
@@ def greet():
-print("Hi")
+print("Hello, world!")
*** Delete File: obsolete.txt
*** End Patch
The @@ line is the context anchor — the patcher locates the hunk by matching the line that follows. My first patch applier was strict: anchor matches exactly or the patch fails. It failed constantly. In practice the model emits anchors that match exactly about 80% of the time, and the rest drift by trailing whitespace, a stale tab-vs-spaces conversion, or a single character of context. Without fallback matching, the model spends half its iterations re-issuing patches that "should have worked."
I ported the Agents SDK V4A engine (353 lines) and added three-level fuzzy context matching: try exact, then with trailing whitespace stripped, then with leading and trailing whitespace stripped. I also added conflict-marker detection and overlapping-hunk detection, so unresolved merge markers or two overlapping hunks fail loudly instead of silently corrupting the file. That killed almost all of the patch-related failures I was seeing, and it's the single piece of infrastructure I'd port first into any other Codex-based harness.
Streaming
Streaming in Hookele is not a latency feature. It exists because long model turns drop mid-stream more often than you'd expect — TCP resets, TLS handshake failures, incomplete chunked reads, server-side response.incomplete. Without retries, every multi-minute reasoning step is one network blip away from starting over.
Hookele retries up to five times with exponential backoff, pattern-matching the exception against a list of transport-level signals (connection reset, broken pipe, TLS handshake, peer closed connection, and a few more). Each retry threads previous_response_id — the Responses API handle that resumes from a prior turn's reasoning state — so the model continues from where it stopped instead of re-deriving its plan from scratch.
This is the quietest piece of the harness and the easiest to undervalue. It does not show up in the score directly, but on the longer tasks a single run will reconnect several times, and without state-carrying retries each of those would cost a full re-plan.
Skill classification
Claude Code and the Codex CLI both let users pre-load skill files for the model to draw on. Hookele does the same thing, but the routing is explicit: a 100-token codex-mini call reads the task instruction, sees the skill catalog (descriptions only, never bodies), and returns JSON like {"skills": ["async_cancellation"]}. The matched skill's full Markdown body gets appended to the system prompt before the loop starts.
The implementation is one f-string and one Responses API call:
response = client.responses.create(
model="gpt-5.1-codex-mini",
input=[{"role": "user", "content": prompt}],
text={"format": {"type": "json_object"}},
reasoning={"effort": "high"},
max_output_tokens=100,
)
skills = json.loads(response.output_text).get("skills", [])
A skill file is just Markdown with YAML front matter and a dense bullet list. async-cancellation-safety is a dozen lines of asyncio gotchas (shield cleanup, await cancelled tasks with return_exceptions=True, semaphore-gated tasks that never start under KeyboardInterrupt). crack-7z-hash mostly tells the model that hashcat -m 11600 is the right mode for 7z archives — the kind of magic number a small model would otherwise burn iterations brute-forcing around.
The catalog is a folder of senior-engineer notebook pages: asyncio semantics, hashcat mode tables, SQL optimization patterns, and similar. Skills are deliberately task-agnostic — the same notes would carry over to any benchmark in this space. Examples are in the repo.
On tasks where a skill applies, trajectory logs visibly compress: the model goes from "explore the problem space" to "follow the playbook and verify" without intermediate flailing.
Error recovery
Hookele does not pattern-match stack traces or auto-retry commands. The recovery loop is intentionally dumb.
When a command fails, its truncated output goes back to the model. If the model then stalls (produces text or another plan revision instead of doing something productive), I inject a single nudge: "Last command failed. Summary: ... Try an alternative and continue." The nudge fires at most once until the next successful non-plan tool call resets it.
That is the entire recovery layer. The model is consistently better at deciding what to try next than any heuristic I wrote, including the heuristics I wrote and then deleted.
Transport-level failures (broken pipes, TLS handshakes, response.incomplete) get handled before the model sees them. Runtime failures (Harbor restart, merge conflicts in apply_patch, pip install blocked by PEP 668) get surfaced verbatim so the model can pivot.
The system prompt
The prompt is sectioned by Task, Workflow, Tools, Build Heuristics, Documentation lookup, Editing, Verification, and Constraints — not a flat numbered list. Active skills get appended below Constraints. The one detail worth calling out: the iteration countdown ("5 steps left", "FINAL WARNING") is not in the system prompt at all. It is injected as user messages mid-loop, so the model actually feels the deadline approaching instead of reading about it once at the start and forgetting.
The numbers
Methodology: 89 tasks, 5 runs each, one Hookele harness, GPT-5.1-Codex-Mini, default 60-iteration cap, run via Harbor. Rank and neighboring entries come from a May 14, 2026 leaderboard snapshot.
-
Perfect (5/5): 46 tasks, from
kv-store-grpctofeal-differential-cryptanalysistosanitize-git-repo. -
Partial (1–4/5): 16 tasks.
pytorch-model-cliat 80%,large-scale-text-editingat 60%,path-tracingat 20%. - Zero (0/5): 27 tasks.
A sample of what actually broke in the 0/5 set, pulled from trajectory logs:
-
compile-compcertandmake-doom-for-mips— both hit the 60-iteration cap babysitting build systems (opam/Coq for CompCert, cross-toolchains for Doom). Around step 25 the model loses track of which dependency loop it is in, and the remaining iterations evaporate onapt/dpkgdebugging. -
sam-cell-seg— the model correctly identified MobileSAM as the right approach and wrote the conversion script, but the SAM weights and module are not present in the container. It marked the task complete with "testing pending due to unavailable weights/module." An environment ceiling, not a planning failure. -
regex-chess— on step 12 the model deemed the task infeasible and calledtask_completewith a summary explaining why regex alone cannot express castling, en passant, and legality. Whether it is actually infeasible or the model gave up too early is debatable; either way, the harness has no obvious lever here. -
extract-moves-from-video— the model refused: "I can't help with downloading or transcribing videos from YouTube." A safety heuristic triggered on the task description, before any technical attempt.
The failure modes are more varied than a single "too hard for the model" story: real long-horizon ceilings, a missing-dependency environment ceiling, a premature give-up, and an unrelated safety refusal. Skill injection does not help in any of these categories.
The full per-task table is on the Hookele leaderboard run.
Where skills run out
Skills cut down on exploration cost. They do not change what the model can do. If a task fundamentally needs GPU, reliable OCR, or many hours of careful multi-step debugging, no amount of prompt engineering will rescue it — the 0/5 catalog above is mostly that.
Harness engineering can expose the model's capability more reliably, but it cannot manufacture capability that is not there. Small models are often leaving performance on the table because the harness around them is too noisy, too brittle, or too eager to help — and that is the part this post is really about.
Cost and time
API spend across the submitted trajectory logs was $27, summed from final_metrics.total_cost_usd. Nine trajectories in the bundle did not include final cost metrics, so the cost number covers 436 of 445 trials. That still averages about 6 cents per recorded task run. The full 5-run sweep took roughly 35.4 hours start to finish.
Per-task spread is wide. fix-git finishes in under a minute for a fraction of a cent. compile-compcert and qemu-alpine-ssh can burn ten minutes and twenty cents each.
What I would tell someone starting
Four things kept coming back:
- Delete before you add. The improvements I trusted most came from removing scaffolding — planner, state machine, criteria extractor, wrapper tools — not adding it.
- Let the model handle errors. Every failure-mode heuristic I wrote underperformed the version where I just show the failure to the model and nudge once if it stalls.
- Cheap pre-passes beat clever prompting. A 100-token classifier plus a folder of Markdown files moved the score more clearly than any structured-output or prompt-engineering pass.
- Design the harness against a smaller model. If it only works when a frontier model papers over every rough edge, the harness is doing less than you think.
Code: https://github.com/sady4850/hookele-agent
I kept some implementation details out of this post for length; the repo has the harness code, patcher, and representative skill files.

Top comments (0)