
Challenges for public sector
Government, education, and nonprofit organizations face several challenges in implementing ML programs to accomplish their mission objectives. This section outlines some of the challenges in seven critical areas of an ML implementation. These are outlined as follows:
- Data Ingestion and Preparation: Identifying, collecting, and transforming data is the foundation for ML. Once the data is extracted, it needs to be organized so that it is available for consumption with the necessary approvals in compliance with public sector guidelines.
- Model Training and Tuning: One of the major challenges facing public sector organizations is the ability to create a common platform that provides ML algorithms and optimize model training performance with minimal resources without compromising on the quality of ML models.
- ML Operations (MLOps): Integrating ML into business operations requires significant planning and preparation. Also, effectively monitor the model in production to ensure that ML models do not lose their effectiveness
- Management & Governance: Public sector organizations face increased scrutiny to ensure that public funds are being properly utilized to serve mission needs. In addition, any underlying infrastructure, software, and licenses need to be maintained and managed.
- Security & Compliance: The sensitive nature of the work done by public sector organizations results in increased security requirements at all levels of an ML platform.
- Cost Optimization: The challenge facing public sector agencies is the need to account for the resources used, and to monitor the usage against specified cost centers and task orders.
- Bias & Explainability: Public sector organizations need to invest significant time with appropriate tools, techniques to demonstrate explainability and lack of bias in their ML models.
Best Practices
AWS Cloud provides several fully managed services that supply developers and data scientists with the ability to prepare, build, train, and deploy ML models.
Data Ingestion and Preparation
The AWS Cloud provides services that enable public sector customers to overcome challenges in data ingestion, data preparation, and data quality. These are further described as follows:
Data Ingestion
Streaming Data: For streaming data, Amazon Kinesis and Amazon Managed Streaming for Apache Kafka (Amazon MSK) enable the collection, processing, and analysis of data in real time.
- Amazon Kinesis Data Streams (KDS) is a service that enables ingestion of streaming data.
- Ingestion of streaming videos can be done using Amazon Kinesis Video Streams.
- Amazon Kinesis Data Firehose is a service that can be used to deliver real-time streaming data to a chosen destination.
- you can use Amazon MSK to build and run applications that use Apache Kafka to process streaming data without needing Apache Kafka infrastructure management expertise.
Batch Data: There are a number of mechanisms available for data ingestion in batch format.
- With AWS Database Migration Services (AWS DMS), you can replicate and ingest existing databases while the source databases remain fully operational.
- AWS DataSync is a data transfer service that simplifies, automates, and accelerates moving and replicating data between on-premises storage and AWS storage services such as Amazon Elastic File System (EFS) and Amazon S3.
Data Preparation
AWS Cloud provides three services that provide prepare and organize the data.
- AWS Glue is a fully managed ETL service that makes it simple and cost-effective to categorize, clean, enrich, and migrate data from a source system to a data store for ML.
- AWS Glue Studio provides a graphical interface that enables visual composition of data transformation workflows on AWS Glue’s engine.
- AWS Glue DataBrew, a visual data preparation tool, can be used to simplify the process of cleaning and normalizing the data.
- Amazon SageMaker is a comprehensive service that provides purpose-built tools for every step of ML development and implementation.
- Amazon SageMaker Data Wrangler is a service that enables the aggregation and preparation of data for ML and is directly integrated into Amazon SageMaker Studio.
- Amazon EMR: Many organizations use Spark for data processing and other purposes such as for a data warehouse. Amazon EMR, a managed service for Hadoop-ecosystem clusters, can be used to process data.
Data quality
Public sector organizations need to ensure that data ingested and prepared for ML is of the highest quality by establishing a well-defined data quality framework. See How to Architect Data Quality on the AWS Cloud.
Model Training and Tuning
One of the major challenges facing the public sector is the ability for team members to apply a consistent pattern or framework for working with multitudes of options that exist in this space.
The AWS Cloud enables public sector customers to overcome challenges in model selection, training, and tuning as described in the following.
Model Selection
- Amazon SageMaker provides the flexibility to select from a wide number of options using a consistent underlying platform.
- Programming Language: Amazon SageMaker notebook kernels provide the ability to use both Python, as well as R, natively. To use coding languages such as Stan or Julia, create a Docker image and bring it into SageMaker for model training and inference. To use programming languages like C++ or Java, custom images on Amazon ECS/EKS can be used to perform model training.
- Built-in algorithms: Amazon SageMaker Built-in Algorithms provides several built-in algorithms covering different types of ML problems. These algorithms are already optimized for speed, scale, and accuracy.
- Script Mode: For experienced ML programmers who are comfortable with using their own algorithms, Amazon SageMaker provides the option to write your custom code (script) in a text file with a .py extension (see Figure 1).
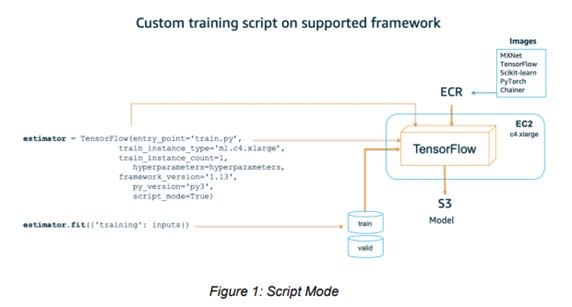
-
Use a custom Docker image: ML programmers may use algorithms that aren't supported by SageMaker, a custom Docker image can be used in these cases to train the algorithm and provide the model (see Figure 2 below).

Model Training
Amazon SageMaker provides a number of built-in options for optimizing model training performance, input data formats, and distributed training.
- Data parallel: SageMaker’s distributed data parallel library can be considered for running training jobs in parallel in case it is common to have multiple training iterations per epoch.
- Pipe mode: Pipe mode accelerates the ML training process: instead of downloading data to the local Amazon EBS volume prior to starting the model training, Pipe mode streams data directly from S3 to the training algorithm while it is running.
- Incremental training: Amazon SageMaker supports incremental training to train a new model from an existing model artifact, to save both training time and resources.
- Model Parallel training: Amazon SageMaker’s distributed model parallel library can be used to split a model automatically and efficiently across multiple GPUs and instances and coordinate model training.
Model Tuning
Amazon SageMaker provides automatic hyperparameter tuning to find the best version of a model in an efficient manner. The following best practices ensure a better tuning result:
- Limit the number of hyperparameters: limiting the search to a much smaller number is likely to give better results, as this can reduce the computational complexity of a hyperparameter tuning job and provides better understanding of how a specific hyperparameter would affect the model performance.
- Choose hyperparameter ranges appropriately: better results are obtained by limiting the search to a small range of values.
- Pay attention to scales for hyperparameters: During hyperparameter tuning, SageMaker attempts to figure out if hyperparameters are log-scaled or linear-scaled.
- Set the best number of concurrent training jobs: a tuning job improves only through successive rounds of experiments. Typically, running one training job at a time achieves the best results with the least amount of compute time.
- Report the wanted objective metric for tuning when the training job runs on multiple instances: distributed training jobs should be designed such that the objective metric reported is the one that is needed.
- Enable early stopping for hypermeter tuning job: Early stopping helps reduce compute time and helps avoid overfitting the model.
- Run a warm start using previous tuning jobs: Use a warm start for fine-tuning previous hyperparameter tuning jobs.
MLOps
MLOps is the discipline of integrating ML workloads into release management, Continuous Integration / Continuous Delivery (CI/CD), and operations.
Using ML models in software development makes it difficult to achieve own different parts of the process; data engineers might be building pipelines to make ML engineers or developers have to work on integrating the models and releasing them.
AWS Cloud provides a number of different options that solve these challenges, either by building an MLOps pipeline from scratch or by using managed services.
Amazon SageMaker Projects
By using a SageMaker project, teams of data scientists and developers can work together on ML business problems. SageMaker projects use MLOps templates that automate the model building and deployment pipelines using CI/CD.
Amazon SageMaker Pipelines
SageMaker Pipelines is a purpose-built, CI/CD service for ML.
- It brings CI/CD practices to ML, such as maintaining parity between development and production environments, version control, on-demand testing, and end-to-end automation, helping scale ML throughout the organization.
- With the SageMaker Pipelines model registry, model versions can be stored in a central repository for easy browsing, discovery, and selection of the right model for deployment based on business requirements.
- Pipelines provide the ability to log each step within the ML workflow for a complete audit trail of model components.
AWS CodePipeline and AWS Lambda
For AWS programmers, CodePipeline exists to utilize the same workflows for ML. Figure 3 below represents a reference pipeline for deployment on AWS.

AWS StepFunctions Data Science Software Development Kit (SDK)
The AWS Step Functions Data Science SDK is an open-source Python library that allows data scientists to create workflows that process and publish ML models using SageMaker and Step Functions.
AWS MLOps Framework
Figure 4 below illustrates an AWS solution that provides an extendable framework with a standard interface for managing ML pipelines. The solution provides a ready-made template to upload trained models (also referred to as a bring your own model), configure the orchestration of the pipeline, and monitor the pipeline's operations.

Deploy Custom Deep Learning Models
AWS also provides the option to deploy custom code on virtual machines using the followings:
- Amazon EC2, and containers using self-managed Kubernetes on Amazon EC2.
- Amazon Elastic Container Service (Amazon ECS) and Amazon Elastic Kubernetes Service (Amazon EKS).
- AWS Deep Learning AMIs can be used to accelerate deep learning by quickly launching Amazon EC2 instances
- AWS Deep Learning Containers are Docker images pre-installed with deep learning frameworks to deploy optimized ML environments.
Deploy ML at the edge
In some cases, such as with edge devices, inferencing needs to occur even when there is limited or no connectivity to the cloud. Mining fields are an example of this type of use case.
AWS IoT Greengrass enables ML inference locally using models that are created, trained, and optimized in the cloud using Amazon SageMaker, AWS Deep Learning AMI, or AWS Deep Learning Containers, and deployed on the edge devices.
Management and Governance
ML workloads need to provide increased visibility for monitoring and auditing. This section highlights several AWS services and associated best practices to address these management and governance challenges.
Enable governance and control
AWS Cloud provides several services that enable governance and control. These include:
- AWS Control Tower: creates a landing zone that consists of a predefined structure of accounts using AWS Organizations, the ability to create accounts using AWS Service Catalog, enforcement of compliance rules called guardrails using Service Control Policies, and detection of policy violations using AWS Config.
- AWS License Manager: AWS License Manager can be used to track this software obtained from the AWS Marketplace and keep a consolidated view of all licenses and enables sharing of licenses with other accounts in the organization.
- Resource Tagging: Automated tools such as AWS Resource Groups and the Resource Groups Tagging API enable programmatic control of tags, making it easier to automatically manage, search, and filter tags and resources.
Provision ML resources that meet policies
- AWS CloudFormation: provides a mechanism to model a collection of related AWS and third-party resources, provision them quickly and consistently, and manage them throughout their lifecycles, by treating infrastructure as code.
- AWS Cloud Development Kit (CDK): The AWS CDK allows teams to define cloud infrastructure in code directly in supported programming languages (i.e., TypeScript, JavaScript, Python, Java, and C#).
- AWS Service Catalog: provides a solution for public sector by enabling the central management of commonly deployed IT services and achieves consistent governance and meets compliance requirements.

Operate environment with governance
- Amazon CloudWatch is a monitoring and observability service used to monitor resources and applications run on AWS in real time.
- Amazon EventBridge is a serverless event bus service that can monitor status change events in Amazon SageMaker.
- SageMaker Model Monitor can be used to continuously monitor the quality of ML models in production. Model Monitor can notify team members when there are deviations in the model quality. see the Introduction to Amazon SageMaker Model Monitor.
- AWS CloudTrail: provides a record of actions taken by a user, role, or an AWS service in SageMaker. CloudTrail captures all API calls for SageMaker.
Security and compliance
Public sector organizations have a number of security challenges and concerns.
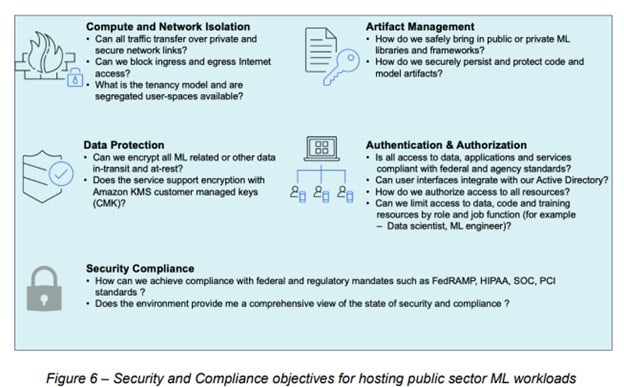
This section provides best practices and guidelines to address some of these security and compliance challenges.
Compute and network isolation
In public sector ML projects, it’s required to keep the environments, data and workloads secure and isolated from internet access. These can be achieved using the following methods:
- Provision ML components in an isolated VPC with no internet access.
- Use VPC endpoint and end-point policies to further limit access.
- Allow access from only within the VPC: An IAM policy can be created to prevent users outside the VPC from accessing SageMaker Studio or SageMaker notebooks over the internet.
- Intrusion detection and prevention: AWS Gateway Load Balancer (GWLB) can be used to deploy, scale, and manage the availability of third-party virtual appliances.
- Additional security to allow access to resources outside your VPC.
Data Protection
- Protect data at rest: AWS Key Management service (KMS) can be used to encrypt ML data, studio notebooks and SageMaker notebook instances.
- Protect data in transit: AWS makes extensive use of HTTPS communication for its APIs.
- Secure shared notebook instances.
Authentication and Authorization
AWS IAM enables control of access to AWS resources. IAM administrators control who can be authenticated (signed in) and authorized (have permissions) to use SageMaker resources. Two common ways to implement least privilege access to the SageMaker environments are identity-based policies and resource-based policies:
- Identity-based policies are attached to an IAM user, group, or role. These policies specify what that identity can do.
- Resource-based policies are attached to a resource. These policies specify who has access to the resource, and what actions can be performed on it. Please refer to Configuring Amazon SageMaker Studio for teams and groups with complete resource isolation.
Artifact and model management
The recommended best practice is to use version control to track code or other model artifacts. If model artifacts are modified or deleted, either accidentally or deliberately, version control allows you to roll back to a previous stable release.
Security compliance
For a list of AWS services in scope of specific compliance programs, see AWS Services in Scope by Compliance Program. AWS provides the following resources to help with compliance:
- Security and Compliance Quick Start Guides.
- Architecting for HIPAA Security and Compliance Whitepaper.
- AWS Compliance Resources.
- AWS Config.
- AWS Security Hub.
Cost optimization
Cost management is a primary concern for public sector organizations projects to ensure the best use of public funds while enabling agency missions.
Prepare
Cost control in this phase can be accomplished using the following techniques:
- Data Storage: it is essential to establish a cost control strategy at the storage level.
- Data Labeling: Data labeling is a key process of identifying raw data (such as images, text files, and videos) and adding one or more meaningful and informative labels to provide context so that an ML model can learn from it.
- Data Wrangling: Amazon SageMaker Data Wrangler can be used to reduce this time spent, lowering the costs of the project. With Data Wrangler, data can be imported from various data sources, and transformed without requiring coding.
Build
Cost control in this phase can be accomplished using the following techniques:
- Notebook Utilization: It helps prepare and process data, write code to train models, deploy models to SageMaker hosting, and test or validate models.
- Test code locally: Before a training job is submitted, running the fit function in local mode enables early feedback prior to running in SageMaker’s managed training or hosting environments.
- Use Pipe mode (where applicable) to reduce training time.
- Find the right balance: Performance vs. accuracy.
- Jumpstart: SageMaker JumpStart accelerates time-to-deploy over 150 open-source models and provides pre-built solutions, preconfigured with all necessary AWS services required to launch the solution into production, including CloudFormation templates and reference architecture.
- AWS Marketplace: AWS Marketplace is a digital catalog with listings from independent software vendors to find, test, buy, and deploy software that runs on AWS.
Train and Tune
Cost control in this phase can be accomplished using the following techniques:
- Use Spot Instances: Training jobs can be configured to use Spot Instances and a stopping condition can be used to specify how long Amazon SageMaker waits for a job to run using EC2 Spot Instances.
- Hyperparameter optimization (HPO): it’s automatically adjusting hundreds of different combinations of parameters to quickly arrive at the best solution for your ML problem.
- CPU vs GPU: CPUs are best at handling single, more complex calculations sequentially, whereas GPUs are better at handling multiple but simple calculations in parallel.
- Distributed Training: the training process can be sped up by distributing training on multiple machines or processes in a cluster as described earlier
- Monitor the performance of your training jobs to identify waste.
Deploy and Manage
This step of the ML lifecycle involves deployment of the model to get predictions, and managing the model to ensure it meets functional and non-functional requirements of the application.
- Endpoint deployment: Amazon SageMaker enables testing of new models using A/B testing. Endpoints need to be deleted when testing is completed to reduce costs.
- Multi-model endpoints: reduce hosting costs by improving endpoint utilization and provide a scalable and cost-effective solution to deploying many models.
- Auto Scaling: optimizes the cost of model endpoints.
- Amazon Elastic Inference for deep learning.
- Analyzing costs with Cost Explorer: Cost Explorer is a tool that enables viewing and analyzing AWS service-related costs and usage including SageMaker.
- AWS Budgets: help you manage Amazon SageMaker costs, including development, training, and hosting, by setting alerts and notifications when cost or usage exceeds (or is forecasted to exceed) the budgeted amount.
Bias and Explainability
Demonstrating explainability is a significant challenge because complex ML models are hard to understand and even harder to interpret and debug.
AWS Cloud provides the following capabilities and services to assist public sector organizations in resolving these challenges.
Amazon SageMaker Debugger
Amazon SageMaker Debugger provides visibility into the model training process for real-time and offline analysis. In the existing training code for TensorFlow, Keras, Apache MXNet, PyTorch, and XGBoost.
It provides three built-in tensor collections called feature importance, average_shap, and full_shap, to visualize and analyze captured tensors specifically for model explanation.
Amazon SageMaker Clarify
Amazon SageMaker Clarify is a service that is integrated into SageMaker Studio and detects potential bias during data preparation, model training, and in deployed models, by examining specified attributes.
Bias in attributes related to age can be examined in the initial dataset, in the trained as well as the deployed model, and quantified in a detailed report.
SageMaker Clarify also enables explainability by including feature importance graphs using SHAP to help explain model predictions.
Conclusion
Public sector organizations have complex mission objectives and are increasingly adopting ML services to help with their initiatives. ML can transform the way government agencies operate, and enable them to provide improved citizen services. However, several barriers remain for these organizations to implement ML. This whitepaper outlined some of the challenges and provided best practices that can help address these challenges using AWS Cloud.
Next Steps
Adopting the AWS Cloud can provide you with sustainable advantages for telehealth systems. Your AWS account team can work together with your team and/or your chosen member of the AWS Partner Network (APN) to implement your enterprise cloud computing initiatives. You can reach out to an AWS partner through the AWS Partner Network. Get started on AI and ML by visiting AWS ML, AWS ML Embark Program, or the ML Solutions Lab.

Top comments (1)
Great Work as usual
best of luck