
A dive into the optimizations done to an API to reduce the payload from ~50mb to ~15kb, improving response time from seconds to <20ms.
A couple of years ago, back when I was working at Expedia, I came across a very peculiar project. It had large requests, tiny responses, and response times were meant to be very fast.
You may have indirectly used this service if you ever been to one of Expedia’s sites looking for a Flight and Hotel bundle. This service is responsible for choosing a flight from all the available options for the selected route, based on some secret sauce related to the customers.
 The flight once selected, is bundled with all available hotels at the destination. Each bundle is priced using another secret sauce, and then advertised as the cost of the flight cost is included in the price.
The flight once selected, is bundled with all available hotels at the destination. Each bundle is priced using another secret sauce, and then advertised as the cost of the flight cost is included in the price.
Each request to this service must provide some information about the customer plus a list of flights, that varies from hundreds to a few thousand of possibilities. This service also needed to be fast to keep an engaging user experience. Response times should ideally be under 300 milliseconds.
The initial data representation was very verbose, and the size ranged from a few hundred Kilobytes up to 50Megabytes. On a 1Gbps network, a 50Megabytes file would take approximately 400 milliseconds, making the targeted response time impossible to achieve.
The network latency was also a complicated factor in our decisions. This service was meant to be hosted on the cloud, while its consumer was running in a data center located in Phoenix-US. The latency between the cloud provider and the data center was alone around 150 milliseconds.
We optimized the request payload to reduce the amount of data sent to the service to the bare minimum. Also, additional content normalization techniques were applied, reducing the redundancy. Finally, we replaced the original XML with JSON, and GZIP compression was enforced to reduce the amount of transferred data.
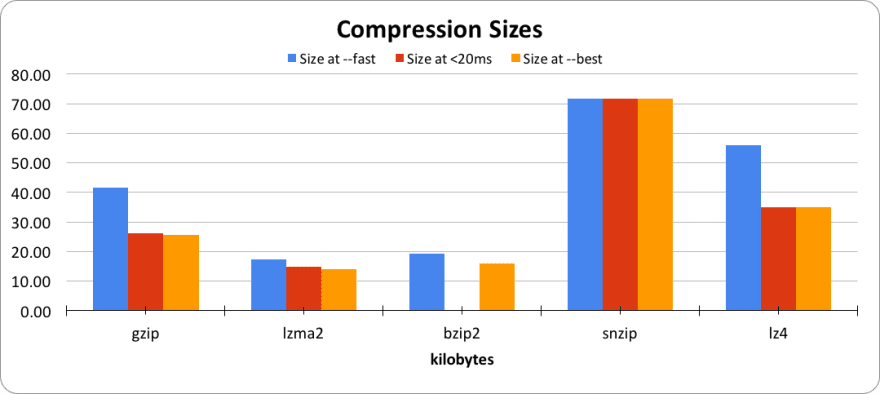
While implementing the GZIP compression, we asked ourselves if other formats could offer better performance. We took an example of an average request in JSON, with one thousand flights, and compressed it using different algorithms.
We decided that an ideal compression should not take longer than 20 milliseconds, i.e., a little over 5% of our targeted time.
Then we executed each compression algorithm three times, each with a different configuration. The first execution aimed to use the fastest compression available, the second to take fewer than 20 milliseconds; and finally, the last one targeted for the best compression. The graph below pictures the results of this experiment.
It was then time to look at the compression speed. The next graph illustrates the compression speed per compression rate.

Comparing both graphs, we observed that the sweet spot would be LZMA2 using compression level 3. It compressed better than Gzip, and it was under the acceptable tolerance of 20 milliseconds of compression time.
Since we were challenging the original XML format, we decided to look at other formats, evaluating at least three aspects: speed; size; and small CPU footprint. Unfortunately, we did not have the required time for a throughout investigation, so our conclusions came from prototyping and local tests.
- XML+FastInfoset: bigger payloads than other formats. Faster deserialization on low latency network
- MessagePack: slower than other binary formats, but faster than raw JSON
- Google Protobuf: fast, small, and offered stable performance
- Kryo: very fast, small, stable. However, it is a Java serialization protocol, meaning that it would only work with Java
Google Protobuf seemed to be the format that we are looking for this experiment, as it offered the right balance between speed, size, and CPU usage. We decided to compare Protobuf against JSON.
| Format | Size |
|---|---|
| JSON | 329KB |
| JSON+Gzip | 22KB |
| JSON+LZMA2 | 15KB |
| Protobuf | 154KB |
| Protobuf+Gzip | 18KB |
| Protobuf+LZMA2 | 13KB |
Our performance test ran for six hours on each of those scenarios, with constant 80 transactions per second. Our goal was to compare the average, and TP95 latencies from both data center to cloud provider. Here are the numbers:
Data Center to Cloud latencies
| Format | TP50 | TP95 | Fastest group |
|---|---|---|---|
| JSON+Gzip | 107.11ms | 536.94ms | 50ms and 100ms: 14% |
| JSON+LZMA2 | 104.20ms | 411.87ms | 50ms and 100ms: 40% |
| Protobuf+LZMA2 | 61.17ms | 293.15ms | 50ms and 100ms: 65% |
Cloud to Cloud latencies
| Format | TP50 | TP95 | Fastest group |
|---|---|---|---|
| JSON+LZMA2 | 16.36ms | 17.94ms | 15ms and 20ms: 98% |
| Protobuf+LZMA2 | 15.05ms | 16.55ms | 10ms and 15ms: 45% |
As you can see, Protobuf offered slightly better performance over JSON when looking at the TP50 and TP95. However, on a low latency network, this caused a significant impact on performance.
As you may notice, we did not complete the tests with Gzip version. I regret this decision, as it would have been valuable to compare with the other results. Our rationale at the time was to focus on LZMA2 since JSON + LZMA2 had better performance than JSON + Gzip.
With those numbers, we were confident to enable the service using Protobuf + LZMA2 in production with a subset of real traffic. However, this wasn’t the end of this experiment. The service was performing well, but we couldn’t see the same throughput as we saw in our tests. For some reason, the client CPU was operating on a higher load than we had expected.
During our capacity tests, we used pre-built requests. The same set of files already compressed and ready to be sent to flight selection service. When the whole orchestration was in place, we learned that the implementation of the LZMA2 algorithm that we were using had performance issues, compared to the native Gzip in that platform. We ran an experiment comparing the real traffic performance when using Gzip versus LZMA2 algorithms, and the winner was Gzip!
The implementation of this service was an excellent experience. The results that we gathered were observed again in similar scenarios. There are many other binary formats and compression algorithms that we haven’t explore. I invite the reader to experiment and to compare with our results.
We wrote the flight selection service in mid-2015. As far as I know, it is still running and serving dozens of variations of Expedia’s websites, and deciding the best flight for customers.

Top comments (3)
Can you add a TLDR pls? :)
I've just added a quick description at the top.
Thank you for sharing !