It is important to understand how analyzers in ElasticSearch work to have an appropriate indexing strategy for your use-case. If you don’t choose a suitable indexing strategy, it would become complex to write queries for your use-case and the queries could end up being slow.
What is an analyzer?
We can think of it as a pipeline. When a document is indexed in ElasticSearch, the string data of the document is given input to the pipeline and an output of terms is generated. These terms are then reverse indexed (as discussed in the previous blog).

What is this pipeline made of?
This algorithmic pipeline contains 3 components.
- Character filter
- Tokenizer
- Token filter
Each component does some specific operation on the string data and outputs it to the next component. Let’s discuss in brief what these components individually do:
Character filter
This component can add, remove or modify the characters present in the string.
Let’s understand this through an example below.
HTML strip character filter:
Think of a use-case where you are storing html file contents as string data in ElasticSearch. This filter can remove all the HTML tags like <b>, <h1>, <p> from the input string data.
Example:
<p>Ironman is flying<p> would be modified to Ironman is flying

The modified string is then passed as input to the tokenizer.
Tokenizer
A tokenizer takes a string and breaks it into multiple tokens. The logic based on which the string is broken down into tokens depends on the type of tokenizer you are using.
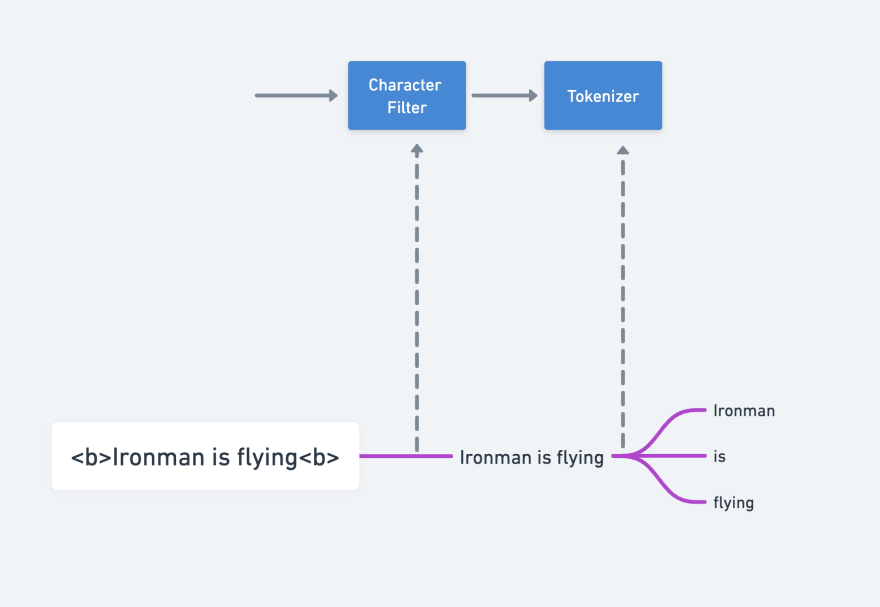
For example, a Whitespace Tokenizer would split the string whenever it encounters a whitespace in the string. Ironman is flying would result in tokens: [Ironman, is, flying]
The output list of tokens are then passed to the token filter.
Token filter
This component adds, modifies or filters out the individual tokens generated in the previous step.
Let’s consider Edge-ngram token filter. This token filter takes each token and produces all the possible prefix substrings of the token.

[Ironman, is, flying] would generate following tokens:
[ I, Ir, Iro, Iron, Ironm, Ironma, Ironman, i, is, f, fl, fly, flyi, flyin, flying]
Note: The example presented here is very specific. There are many types of Tokenizers, Token filters and Character filters to use. You can construct a custom analyzer specific to your use-case.

Top comments (0)