
As programmers, we need to be able to choose the correct tools to solve the problems that we face every day. One of those tools is which programming language should we use. Sometimes a scripting language like Python, PHP or JS will be best. At others, we will need the robustness of a compiled language like Java, C++ or Rust. In this post, I will talk about my adventure in changing the stack to help me solve a problem.
I work as a software engineer at EBANX. Here, most of our backend is written in PHP. Even though there is a lot of criticism about it out there, PHP is a great language that is scaling pretty well to attend our needs. But, the lack of good multithreading can be a negative point when you want to do some very data or CPU intensive tasks.
So, here at EBANX, we have a very critical operation that happens every day and it needs to be finished by noon. Since it is very important for our business, we are constantly trying to make it faster without sacrificing the business rules. One of the steps of this process was taking over 30 minutes, so I decided to play with it to see if I could get it to be faster.
Now, this step is very data-intensive. Imagine that we have a payment(transaction) with its unique identifier, a date, a customer identifier and an amount. We need to check that if we sum the amount from all payments with the same customer identifier in the same month (month/year) it does not surpass a specific threshold. To make matters worse, every day we may have more than a million transactions from a variety of customers and dates that need to be validated against the entire history of the company.
In the past, we tried to solve this by using our relational database. But as the company grew, it started to be too slow. So, we changed to a different approach. We started to write a file every day with all payments that entered during that day operation with a month-year identifier, the payment amount and a customer identifier. So, now we open all files from the company history, we create a compound key using the month-year and customer identifier. Then we add up all amounts from payments that match the keys from our current process and alert it goes over our limit. All of this is done using PHP.
So, my first decision was that I would not change this method. Even though we could think of ways of pre-caching some of those calculations, I wanted to keep the same approach in a way that I could simply swap the existent code with mine. Also, I decided to try writing it using Rust since it is a compiled language focused on performance and safety.
To have a baseline, I started by running the current code on my computer to see how much time it was taking on my machine. I ran it 5 times and it took on average 9.3 minutes. Now, It was way faster than in our production environment and I think it is due to my SSD being faster than whatever storage device is being used in production.
My next step was to rewrite all the current code from PHP to Rust. I wrote it as a standalone program that could be called by our current PHP code and just wait for the result reading the standard output.
I used some cool crates like flate2 that allows you to stream over a GZ compressed file. Also, I wrote integration tests using assert_cmd to call my program and assert that it outputs the expected payments.
Once it was finished, I did the same thing that I did with the original PHP code. I ran it 5 times and got the average execution time. And it was... 9.1 minutes. Only 2.1% faster. Quite a disappointment right? It makes sense since it does not perform a lot of heavy computations, the PHP interpreter was not being a big bottleneck. But I did not give up. My next step was to use some multithreading.
If you never used Rust, it tries to be a fast language like C or C++, but with a lot of guarantees that help you as a programmer to not mess up. It does not make multithreading easy, but it makes it safer.
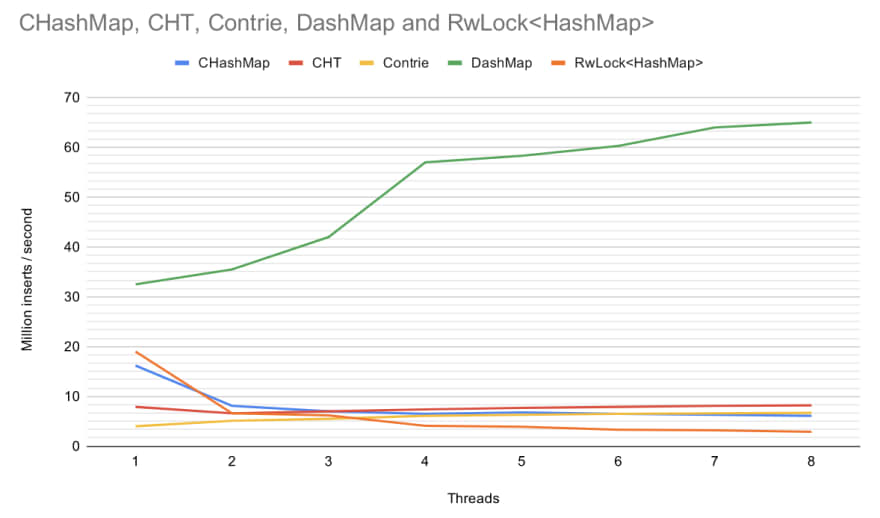
I was using a HashMap to accumulate my values where the key was a tuple with the first element being the month-year of the payment and the second element the customer identifier. For each key, I was accumulating the total amount. To do the multithreading I could go in two ways, the first would be to create a separate HashMap to each thread and then unify them at the end. This would avoid concurrency problems and having one thread have to wait for another one to stop modifying the data. Another approach would be to use the same hashmap across all threads and handle the clashes. I decided to go with the second option using a DashMap. A Dashmap is a Rust crate that offers a concurrent hashmap implementation that tries to minimize the number of locks. It has some pretty good benchmarks as you can see in the following image taken from the official crate documentation. One factor that made me prefer this approach is that in my use case it should not happen very often that two threads are processing payments from the same customer opened in the same month so clashes should be rare.
Another thing that I needed to think about is since the company has grown a lot, the newer files are way bigger than the old ones. So, a thread might get all small files so it ends fast while another gets stuck with all the big ones and take a lot of time. To try to minimize this, I shuffle all files before dividing them into the threads. I can do this safely since the order of the files does not affect the result.
After it was done it was the time to test it. Going from 2 threads up to 8(The number of virtual cores on my machine), I ran it 5 times and took the average. Bellow is the result of all tests. Now, the average execution time for 8 threads was 2.6 minutes. 72% faster. Yay, real improvement :). I did not test it yet on one of our production machines to see how it will perform there.
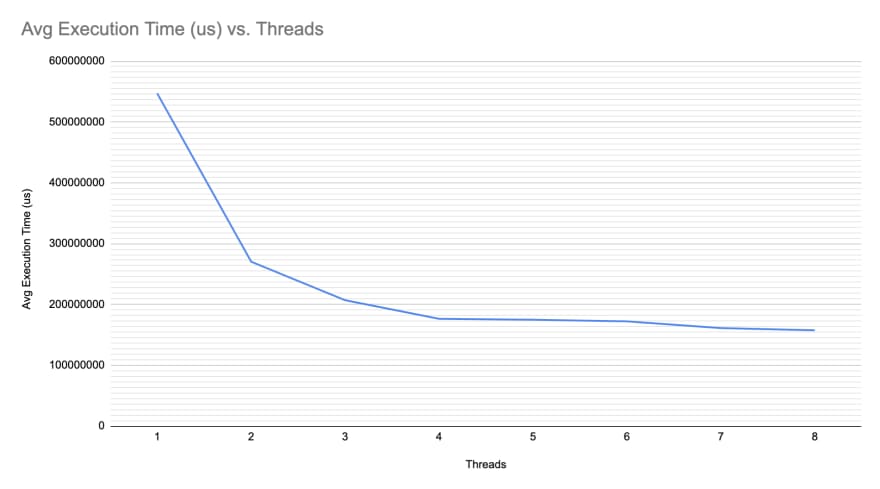
My next step will be to rewrite everything to use async I/O. See if this will make it even faster or not. After it, I will try changing the approach and do some caching to try getting it from minutes to seconds.

Top comments (0)