
Today, we will understand the road map for a data engineer. What one need to learn to become a good data engineer.
Data Engineering Roadmap.
Software and technology requirements that you need.
1). Cloud account, Google GCP, AWS or Azure.
2). Python IDE and a text editor, preferably Anaconda.
3). SQL server, MYSQL Workbench, DBeaver AND DBVisualizer.
4). Git and version control system (preferably a GitHub account)
5). Create an account on https://www.atlassian.com and understand the following Atlassian product.
- Jira, Trello, Confkuence, Bitbucket, Confluence
1. Data Engineering
What is Data Engineering?
What do a data engineer do?
What is the difference between Data Engineers, ML Engineers and Data Scientists?
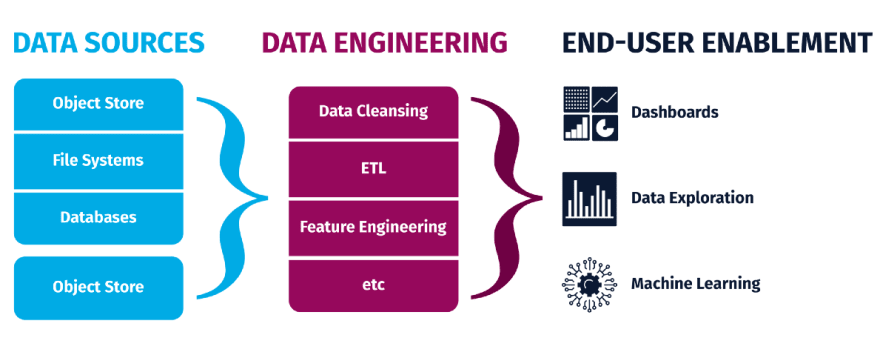
Data engineering is the task of designing, building for collecting, storing, processing and analyzing large amount of data at scale.
In data engineering we develop and maintain large scale data processing systems to prepare structured and unstructured data to perform analytical modelling and make data driver decisions.
The aim of data engineering is to make quality data available for analysis and efficient data-driven decision making.
The Data Engineering ecosystem consists of 4 things:
- Data — different data types, formats and sources of data.
- Data stores and repositories — Relational and non-relational databases, data warehouses, data marts, data lakes, and big data stores that store and process the data
- Data Pipelines — Collect/Gather data from multiple sources, clean, process and transform it into data which can used for analysis.
- Analytics and Data driven Decision Making — Make the well processed data available for further business analytics, visualization and data driven decision making.
Data Engineering lifecycle consists of building/architecting data platforms, designing and implementing data stores and repositories, data lakes and gathering, importing, cleaning, pre-processing, querying, analyzing data, performance monitoring, evaluation, optimization and fine tuning the processes and systems.
Data Engineer is responsible for making quality data available from various resources, maintain databases, build data pipelines, query data, data preprocessing using tools such as Apache Hadoop and Spark, develop data workflows using tools such as Airflow.
Machine Learning Engineers are responsible for building ML algorithms, building data and ML models and deploy them, have statistical and mathematical knowledge and measure, optimize and improve results.

2). Python for Data Engineering
Data engineering using Python only gets better:
- The role of a data engineer involves working with different types of data formats. For such cases, Python is best suited. Its standard library supports easy handling of .csv files, one of the most common data file formats.
- A data engineer is often required to use APIs to retrieve data from databases. The data in such cases is usually stored in JSON (JavaScript Object Notation) format, and Python has a library named JSON-JSON to handle such type of data.
- Data engineering tools use Directed Acyclic Graphs like Apache Airflow, Apache NiFi, etc. DAGs are nothing but Python codes used for specifying tasks. Thus, learning Python will help data engineers use these tools efficiently.
The responsibility of a data engineer is not only to obtain data from different sources but also to process it. One of the most popular data process engines is Apache Spark which works with Python DataFrames and even offers an API, PySpark, to build scalable big data projects.
Luigi! The Python module that is widely considered a fantastic tool for data engineering.
Python is easy to learn and is free to use for the masses. An active community of developers strongly supports it.
Basic Python
Maths Expressions
Strings
Variables
Loops
Fucntions.
List, Tuples, Dictionary and sets
Connecting With Databases.
Boto3
Psycopg2
mysql
Working with Data
JSON
JSONSCHEMA
datetime
Pandas
Numpy
Connecting to APIs
Requests
3. Scripting and Automation
You need to learn automation, so that you will automate the repetitive tasks and save on time.
Shell Scripting
CRON
ETL
4). Relational Databases and SQL
SQL is very critical in your data engineering path, learn also to perform advanced queries on your data.
RDBMS
Data Modeling
Basic SQL
Advanced SQL
Big Query
5). NoSQL Databases
As a data engineer you will work with variety of data, unstructured data will be commonly stored in NoSQL databases.
Unstructured Data
Advanced ETL
Map-Reduce
Data Warehouses
Data API
6). Data Analysis
Pandas
Numpy
Web Scraping
Data Visualization
7). Data Processing Techniques
Batch Processing : Apache Spark
Stream Processing — Spart Streaming
Build Data Pipelines
Target Databases
Machine learning Algorithms
8). Big Data
Big data basics
HDFS in detail
Hadoop Yarn
Hive
Pig
Hbase
Data engineering tools are specialized applications that make building data pipelines and designing algorithms easier and more efficient. These tools are responsible for making the day-to-day tasks of a data engineer easier in various ways.
Data ingestion systems such as Kafka, for example, offer a seamless and quick data ingestion process while also allowing data engineers to locate appropriate data sources, analyze them, and ingest data for further processing.
Data engineering tools support the process of transforming data. This is important since big data can be structured or unstructured or any other format. Therefore, data engineers need data transformation tools to transform and process big data into the desired format.
Database tools/frameworks like SQL, NoSQL, etc., allow data engineers to acquire, analyze, process, and manage huge volumes of data simply and efficiently.
Visualization tools like Tableau and Power BI allow data engineers to generate valuable insights and create interactive dashboards
Apache Spark is a fast cluster computing framework which is used for processing, querying and analyzing Big data. Being based on In-memory computation, it has an advantage over several other Big Data Frameworks.
Originally written in Scala Programming Language, the open source community has developed an amazing tool to support Python for Apache Spark. PySpark helps data scientists interface with RDDs in Apache Spark and Python through its library Py4j.
There are many features that make PySpark a better framework than others:
Speed: It is 100x faster than traditional large-scale data processing frameworks
Powerful Caching: Simple programming layer provides powerful caching and disk persistence capabilities
Deployment: Can be deployed through Mesos, Hadoop via Yarn, or Spark’s own cluster manager
Real Time: Real-time computation & low latency because of in-memory computation
Polyglot: Supports programming in Scala, Java, Python and R
Spark RDDs
When it comes to iterative distributed computing, i.e. processing data over multiple jobs in computations, we need to reuse or share data among multiple jobs. Earlier frameworks like Hadoop had problems while dealing with multiple operations/jobs like
Storing Data in Intermediate Storage such as HDFS
Multiple I/O jobs make the computations slow
Replications and serializations which in turn makes the process even slower
RDDs try to solve all the problems by enabling fault-tolerant distributed In-memory computations. RDD is short for Resilient Distributed Datasets. RDD is a distributed memory abstraction which lets programmers perform in-memory computations on large clusters in a fault-tolerant manner. They are the read-only collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost.
There are several operations performed on RDDs:
Transformations: Transformations create a new dataset from an existing one. Lazy Evaluation
Actions: Spark forces the calculations for execution only when actions are invoked on the RDDs
Reading a file and Displaying Top n elements:
rdd = sc.textFile("path/Sample")
rdd.take(n)
9). WorkFlows
Introduction to Airflow
Airflow hands on project
10). Infrastructure
Docker
Kubernetes
Business Intelligence
11). Cloud Computing
Such AWS, Microsoft Azure, Google Cloud Platform
1). Data Engineering Tools in AWS
Amazon Redshift, Amazon Athena
2). Data Engineering Tools in Azure
Azure Data Factory, Azure Databricks
This may seem a lot to learn and cover as you become a Data Engineer, however you need to master Python and Advanced SQL well since they are core in data engineering. Understand the big data tools that are available. Remember to build projects so that you understand what you are learning.
Tools differ from one organization to another, so you need to understand the tools that your organization uses and be good in them.

Top comments (0)