
As I'm sure you've been told repeatedly, programming is usually a team effort. Enter Git.
Version Control Systems and Distributed Version Control Systems
To allow programmers to work as a team, some sort of version control system, or VCS is typically used. A VCS tracks any changes made to a project and it allows users to recover any version of a project that they wish to view. Additionally, you can also typically see any changes that were made, who made them, when they were made, and hopefully why they were made. Git is not only a VCS, its a distributed version control system, or DVCS. This means that Git users have complete access to every branch, file, and iteration of any project they're working on, as well as a total history of all changes made to that project. In addition to this, DVCSs don't require constant connection to a central repository, meaning developers are free to work on projects wherever they have access to a computer! In addition to the regular benefits of a DVCS, Git has the added bonus of being extremely lightweight, allowing for easy creation and changes to branches. These traits combine to make Git incredibly ubiquitous, so much so that over 70% of developers use Git!
Git Basics
Git essentially creates whats known as a repository and tracks it. A repository is a collection of all files and folders associated with a project. From there, the file history is tracked as a linked-list through commits, with each development line known as a branch. Since Git is a DVCS, anybody with a copy of the repo is able to access not only the entire codebase, but also its history. There are three basic commands for updating your repository: add, commit, and push. Before performing an add, you can also use the status command to see any changes to your work. Checking the status on an unmodified repo should look something like this:

Note that all Git commands must be preceded by the phrase "git". After a change has been saved, it needs to be staged. The add command is used to stage changes:

You can add a single file like in my example, multiple files separated by a space, folders, the entire repo, or any combination in between! After staging a change using add, the commit command is used to actually save that snapshot to the project's history. Upon performing a commit, you will also typically be prompted to include a message along with your commit to describe your reason for performing the commit:

Finally, the push command is used to update a remote repository with any commits that you have made locally!
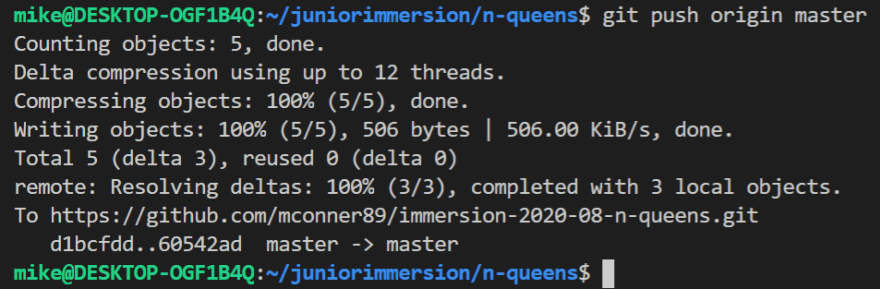
With those four commands you can begin editing a Git file!
When trouble rears its Head....
Sometimes, things get off track. One of the first problems I encountered while using Git was the ominous "detached HEAD" state. This happens when using the checkout command. Checkout can be used to view a branch or a specific commit. Its the latter use-case that causes the detached HEAD warning.
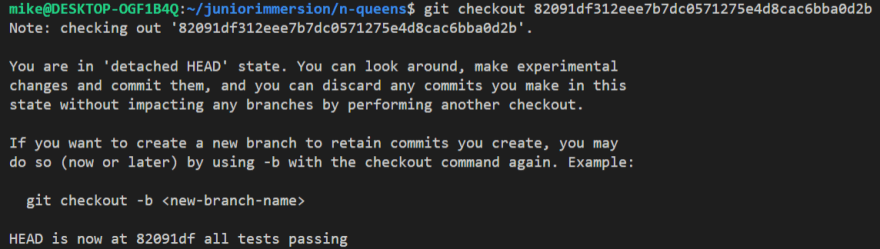
In Git, HEAD typically points to the revision that you're currently working on, and moves automatically with each new commit. However, this process is disrupted when checking out a commit hash. This happens because when you change to a commit, you are no longer pointing to a branch. This is the essence of a detached head: HEAD pointing directly to a commit instead of a branch. Because of this, changes that you make won't belong to any particular branch. This is a problem because you won't have an easy way to access any changes you make in this current environment.

From here, there are two scenarios: you've arrived here by choice and you want to keep any changes you make, or you've stumbled here by accident and want to get back to your main branch. If you're here by accident, its relatively simple to get back on track (assuming you just want to get back to the master). Simply checkout the master:
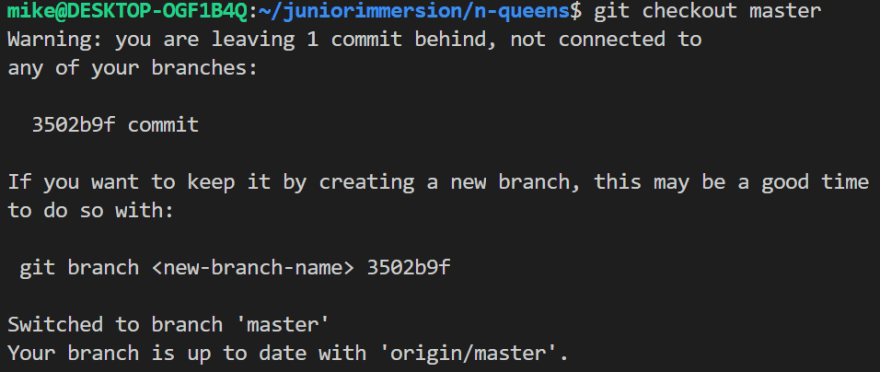
From there, you should be free to continue your work. If you want to keep working on this new line and make it a new branch, thats also pretty straightforward. simply create a branch and run checkout on that new branch:

I hope this article can help you out the next time you encounter a detached head!

Top comments (0)