Hey. Hello there, friends.
So I've been learning Machine Learning lately, and I thought about starting a series of Machine Learning posts, but I later changed my mind and decided to stick on Amazon Sagemaker solely. Here, I'd want to give my thoughts about Amazon Sagemaker and how it's a fantastic tool for machine learning.
My objective with this essay is to inform you by addressing the "WHY," "HOW," and "WHAT" sequences of questions for selecting the proper platform for the vast majority of machine learning challenges that we tackle in organisations today. Then, as a feasible contender, I'd relate 'AWS Sagemaker' to the problem, highlighting the reasons given in 'Why do we need AWS Sagemaker?' There are certainly other sorts of difficulties and experiments in business for which this would not be the best approach; I'll try to suggest a few examples.
Why do we need a platform in the first place?
The most efficient method to deal with large machine learning problems is to aid a data scientist with the necessary software skills in a neat abstract yet effective way to provide an ML solution as a highly scalable web-service (API). The API may be linked into the proper software systems, and the ML service can be abstracted by the software development team as simply another service wrapped around an API.
As a result, we want a platform that provides a data scientist with the tools needed to autonomously execute a machine learning project from start to finish.
HOW CAN A PLATFORM HELP WITH THIS PROBLEM?
Given the project's three distinct stages, we need to devise a system that puts the data scientist in charge. We can overcome the challenges highlighted above if we have a platform that provides clean abstractions to boost the remaining skills in each of these phases while also being incredibly effective and adaptive for a data scientist to produce results.
As a result, we require a platform that allows the data scientist to leverage his existing skills to engineer and study data, train and tune ML models, and finally deploy the model as a web-service by dynamically provisioning the necessary hardware, orchestrating the entire flow and transition for execution with simple abstraction, and providing a robust solution that can scale and meet demands elastically.
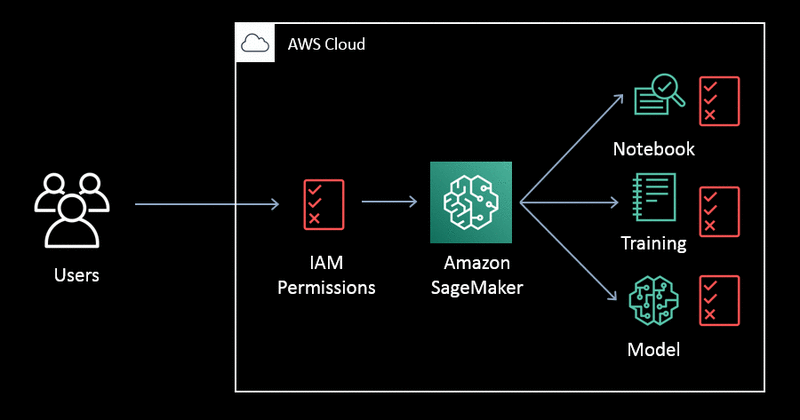
Why should I go with Amazon Sagemaker?
I feel AWS Sagemaker is the greatest match for us. It features Jupyter NoteBooks with R/Python kernels, as well as a compute instance that can be selected on demand based on our data engineering requirements. We can show, analyse, clean, and transform the data into the necessary formats using common methodologies (such as Pandas + Matplotlib or R + ggplot2 or other popular combinations). Following data engineering, we may train the models using a different compute instance based on the model's computation demands, such as memory optimised or GPU enabled.
Take use of intelligent default high-performance hyperparameter modifying options for a variety of models. Use performance-optimized algorithms from AWS' large library, or bring in our own utilising industry-standard containers. Deploy the trained model as an API as well, but this time use a different compute instance to fit business requirements and to grow elastically.
And the entire process of provisioning hardware instances, running high-capacity data jobs, orchestrating the entire flow with simple commands while abstracting the massive complexities, and finally enabling serverless elastic deployment can be accomplished with only a few lines of code while remaining cost-effective. Sagemaker is a revolutionary enterprise solution.
So, that's it for the sagemaker and his significance. My next essay will be on where you SHOULD NOT USE Sagemaker.

Top comments (2)
Good read!
Good read I await your next article on This