
Not surprising that even in 2019, there are still people in IT who think that a single server’s utilization should be a significant measurement, completely forgetting the importance of holistically looking at the system as a whole. This post explains the Systems Thinking way to think about IT, with a pinch of Theory of Constraints understanding of “buffers” added in.
The story begins with a recent question in our Operation Israel community:
Policy makers in government want to see proven benchmarks comparing open-source (LAMP, Kubernetes) server utilization vs. classic Microsoft Windows based servers (IIS, SQLServer).
Are there any documents, posts or studies to refer them to?
It is great that people in government want to define a policy to improve things. This policy is going to be used for making decisions at various IT branches of government and this policy definition process starts by asking a naive question: “is it better to have a server with IIS and SQLServer or a server with LAMP or maybe even Kubernetes?”
They are not asking what would enable faster, better, higher quality deliveries to citizens in terms of IT and how to enable it. This policy is focussed around the utilization of servers, and how to choose which technology stack to use to get a “better” result in terms of utilization.
But is high utilization of servers is “good” and low utilization is “bad”? Or maybe vice-versa?

Logical reasoning behind the thinking that higher utilization is better.
I would guess that “waste” in terms of unutilized servers is considered bad, and thus servers that have “higher utilization” are thus considered better.
It there a fallacy in this logic? Yes, but it depends on what kind of “servers” we are talking about here. Since the opposite of having less waste is not filling up the wasted capacity. But rather reducing waste means having a better fit between the applications (generators of utilization) and the servers.
How about using smaller fit-for-purpose servers to solve this?
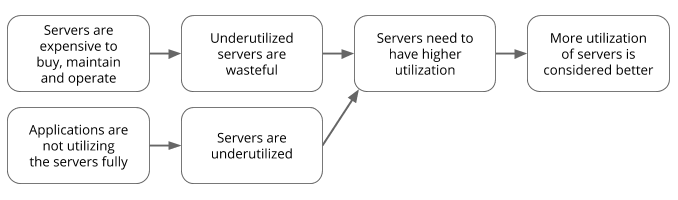
Maybe it is the fault of the applications and not the servers.
So the natural conclusion is that there must be a KPI (performance indicator) that measures the utilization of servers, and when the utilization is very high it also means that the waste is very low — thus an IT policy that defines high utilization as standard makes sense. Because servers are expensive and taxpayer money should not be wasted. Right?
Business/Government Outcomes
The government IT systems are serving the citizens in many ways, taxation, benefits, licenses and many more. When these systems are not available or don’t work, I consider that a bad thing. When everything works like it should, even during peak demand and all citizens are provided with quality service I consider it a good thing.
As more citizens are using these IT systems, the capacity demand of the applications is increased. Thus the servers where the applications are deployed must have ample spare capacity to accommodate the increase in demand. But wait a minute, this means that utilization must not be high!
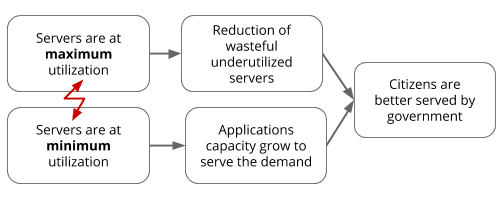
The “Conflict Cloud” of utilizing servers
So what should the policy say? Spend as much taxpayer money as possible to keep all systems running with ample spare capacity? Or spend as little taxpayer as possible to get unstable systems that are often broken and are not serving the citizens properly? How to choose a technology stack that enables the maximum utilization of servers or the minimum utilization of servers?
How to choose a technology stack that enables maximum utilization of servers?
Fortunately, we live in a world that this question has been answered already. Not so long ago (10–15 years ago) the demand on applications and servers was mostly non-existent for most companies, with the exception of few very successful ones such as Amazon or Google. Facebook didn’t even exist yet.
Even back in 2005 in these specific companies, the trouble of wasting a huge amount of unutilized server capacity incurred many millions of dollars of waste. This led Amazon and Google to search for a solution to the problem. And by the way, they were already using mostly Linux as a core component in their technology stack. In 2003 Google invented Borg, the precursor for Kubernetes, and in 2004 Amazon invented Elastic Compute Cloud (EC2) a major service providing compute in Amazon Web Services (AWS).
Utility Computing
What exactly was the problem in these companies, and how did they solve it using these new technologies? Jon Jenkins explains back in 2011 that during a normal month, Amazon.com could have 39% spare server capacity just standing idle because of demand fluctuation. Translate that into dollars, it is millions of dollars.
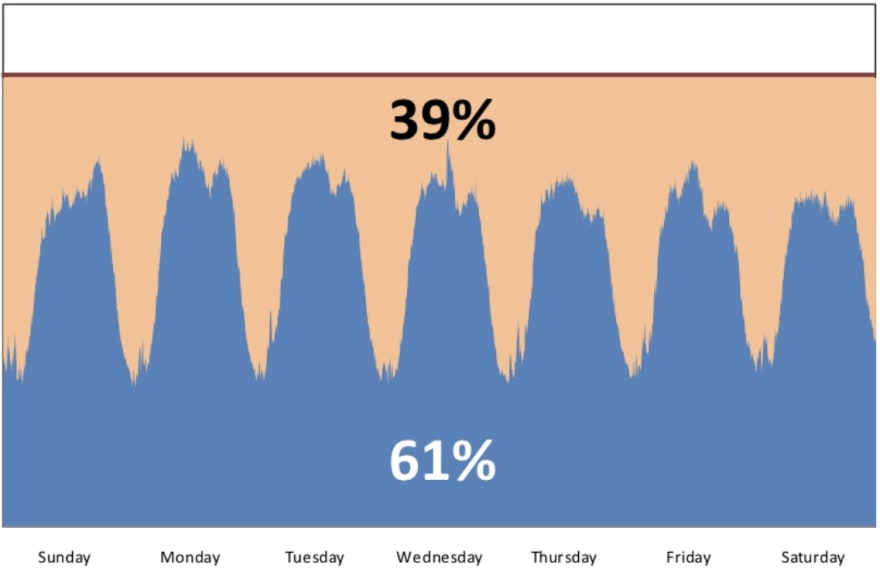
Typical Weekly Traffic to Amazon.com — Jon Jenkins 2011
Notice the red line? That is the amount of capacity “reserved”. The number of servers that Amazon.com had to buy and rack in their data-centers in order to have enough capacity to serve the peak demand +15% spare buffer. Arriving at this number is a familiar IT activity called “Capacity Planning”.
In effect, for Amazon.com it was much worse than this, during the holidays in the month of November. An annual spike in demand required much more spare capacity to be available in order to “protect” the business and allow buyers on Amazon.com buy gifts for their loved ones. There was an astonishing 76% spare server capacity sitting there idle and not utilized, just waiting for the spike in demand to arrive.
What did they do with all those servers during the rest of the year?

November Traffic for Amazon.com — Jon Jenkins 2011
Capacity planning is the practice of trying to figure out in advance how much capacity is required to allow the application to meet its expected demand. In a traditional IT shop that would determine the number of servers that need to be bought and racked, spending all the money in advance in addition to the waste caused by near-zero utilization for most of that servers’ lifetime.
There is a circulating rumor that AWS was started because Amazon.com had all this spare capacity sitting there doing nothing. The story goes that a couple of guys were sitting in the control room of a data-center that was powered off after the holidays, and they came up with this idea to sell all of the servers virtually which later became known as AWS EC2.
The true story is explained by Benjamin Black on his blog in which he writes that Chris Pinkham was constantly pushing them to find better ways to decouple the infrastructure as independent components. And one of the results was this document explaining how to reduce the fine-grained coupling between applications and hardware. A side note in the document mentioned that virtual servers could maybe even be sold to external users which Jeff Bezos approved of and later set Chris to go and create the EC2 team in 2004. According to Jon Jenkins, six years later Amazon.com turned off their last physical server and moved completely onto EC2 for all Amazon computing.
Decoupling
The solution to having much higher utilization is hidden in the explanations above. What Jon and Benjamin describe is how they compact and decouple components by making them small and independent. Thus creating the magic that enabled Amazon to move towards using computing as a utility. They called it “Utility Computing” back then, we usually call it “The Cloud” today.
Breaking down monolithic applications and infrastructure into small components has multiple benefits. It allows innovating and improving each such component independently of others. Improvements in the storage component do not affect improvements in the networking component or in application components.
Having small independent components also makes it much easier to reuse and create more copies. Which enables the possibility of “horizontal scaling”, having small independent components to scale individually as needed and take as much capacity as it requires out of a much bigger pool of computing capacity available for all.
I call this the “insurance company business model math”. Start with 1,000,000 people who pay $50 insurance each month — it is now possible to fund 1,000 people every year with up to $600,000 insurance claims each. On the other hand, should each person only save their $50 in a safe, it could allow each person to claim only $600/year.
The practice of “horizontal scaling” of independent components enables applications to use less compute capacity overall, each component is relatively small and can live in multi-tenancy with other components on the same physical hardware — the big pool of hardware becomes like the pool of money in an insurance company, much too big for everyone to use all at once. Each component usually is using just a portion, and during peak or high load not all of the components are scaled to their maximum — because usually it is not required. But those components that do scale, have the spare capacity to use.
Buffer Management
So now you learned that it is important to keep infrastructure cost low, and at the same time, it is important to keep uptime high. And the way to solve the conflict is using horizontal scaling with many small componentized services.
But how to actually do it? When to scale up and when to scale down?
Look at the Amazon.com graph from before, the usage pattern reflects the traffic of the website and is used as a proxy metric to determine how much capacity is required. How should they decide when to scale the capacity?
When capacity planning is done by humans, as a once-a-year activity just before the budget planning period. Then the planned capacity has to be a fixed number, we require 100 additional servers this year. The IT manager goes with this number to the CFO and explains that without those 100 servers the business is going to get the unfortunate downtime now and again. Everyone understands that the existing 1,000 servers already have so much wasted spare capacity … it is not even funny how pathetic this is. And when the existing servers don’t have spare capacity, then downtime of services is rampant and fire fighting is the norm already. The “Conflict Cloud” is represented and reflected directly on business performance and financials.
It is also very hard to make the capacity plan anything but a fixed number because racking servers in a data-center takes a lot of time and effort. The servers must be purchased, delivered, racked, provisioned and only then used by applications. Each such step takes weeks or months in traditional IT.
Even companies that adopt the “Public Cloud” are usually not much better. It just becomes much easier to create additional waste because it takes less time to “buy and provision” a server, usually by a developer who clicks a button. These developers who are now doing all the spending are not controlled by the CFO or budgets at all, causing redundant spend and waste to be rampant.
When a single application is using a single “big” server, as described in the insurance math example, the pool of capacity for that one application is limited to that server — it cannot horizontally scale. Most of the time this single-server pool of capacity is not being used in full, utilization is low, while uptime is okay. Maybe it is vice-versa, utilization is high and downtime is common, either scenario is not such a great thing to have.
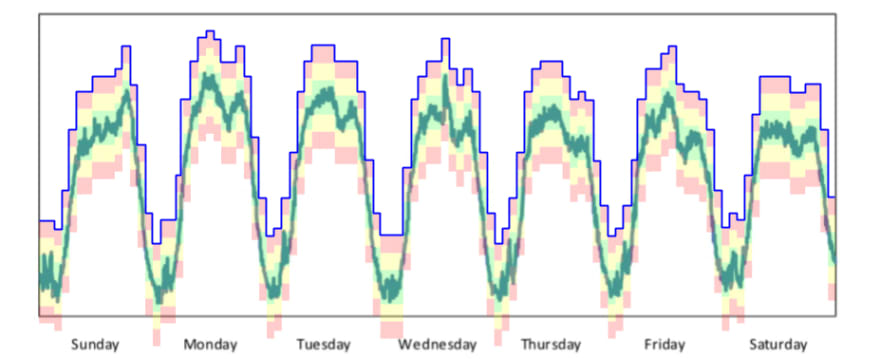
How much spare capacity is required to keep uptime high and cost low? — Whitespace on top is “not waste”
Managing a big pool of capacity requires using a method to determine how much each application needs to use at any given moment. In the world of “The Cloud” they call it “Automatic Scaling”. Using the capability to horizontally scale each component in the application to only use the amount of capacity it requires at that moment with the +15% for protection.
A good way to automate this automated decision management is to use Eli Goldratt’s buffer management techniques. In the example above, the blue line specifies how many servers that component has to take away from the pool at any given time. And the red/yellow/green areas are an indicator to specify when to scale into more horizontal instances, and when to scale down into fewer component instances to free up capacity in the pool.
When the amount of capacity is in the green area, everything is great. When it gets into the top yellow, add more capacity, in the bottom yellow reduce reserved capacity back into the pool for others to use. The red area is the danger zone, either the service is going to be out of capacity, or the utilization is much higher (wasteful) than it needs to be on the bottom red.
Conclusion
This article started with the question “Is it better to have Windows Servers with IIS, or Linux servers with Kubernetes in terms of server utilization”. The answer is highly dependant on the application. There are no right or wrong answers. If the technological stack of an application has many independent small components that can scale horizontally — utilization can be improved.
I would argue that using the public cloud, or using a container orchestrator such as Kubernetes is one way to force breaking down the monoliths into smaller components. These technologies simply require it to be so.
Adopting Kubernetes or Linux for a mostly Windows shop will be a very hard struggle at first, and the investment might not even be worth the benefits. But what it will do, is force the organization to break down their monoliths and get closer to the multi-tenant independent small components, thus enable all the described benefits. The benefits are definitely there to be had, especially when huge waste and inflexibility is the standard way of operating in so many IT shops today still.
Hopefully, this article has provided you with some ideas to implement in your own operations, maybe you even learned a thing or two about buffers and capacity planning.
Let us know in the comments what you think!
Reference
- Jon Jenkins on Velocity Culture
- Jon Jenkins on How Amazon Migrated to AWS (2, 3)
- Benjamin Black on EC2 Origins
- Jeff Bezos interview at D6 2008 Part 3 (1, 2, 4, Transcript)
- Eli Goldratt on Buffer Management — Full episode is for pay, talks about how the world’s Steel Industry has a wasteful amount of excess inventory.
- DevOps and the Theory of Constraints

Top comments (0)