
DaHack - Hackathons Dataset!
GitHub Link: https://github.com/revanth-reddy/tamudatathon
Hackathon's Dataset in Hackathon
![]()
This Dataset is built as a part of TAMU Datathon 2021. It contains the details of hackathons which include Title, Location, Start Date, End Date, Prize Money, Number of Participants, Host of Hackathon, Themes in the Hackathon
As a part of Tamu Datathon 2021 challenges, we chose TD Data Synthesis Challenge. We approached the problem of synthesis of Hackathons Dataset throughout the world.
Construction of Dataset
The data for this dataset is obtained by Web Scraping using Python and Selenium.
Size
- We are able to generate a dataset of 6,236 hackathons due to time constraints. However this size can be tremendously increased.
Uniqueness
- This is the first Hackathon's Dataset with 8 unique features that are the major datapoints of a Hackathon
Usefulness
- To Observe the trends:
- Number of Hackathons per year.
- Hackathons Prize Money Trend over years.
- Rise of Themes through the years.
- Participation in the Hackathon across years/themes.
- And many more ...
- To Build ML models in order :
- to predict Prize Money based on other features like participation, themes, location.
- to estimate user participation based on location, prize money, themes, etc.
- to analyze relationship between the above features.
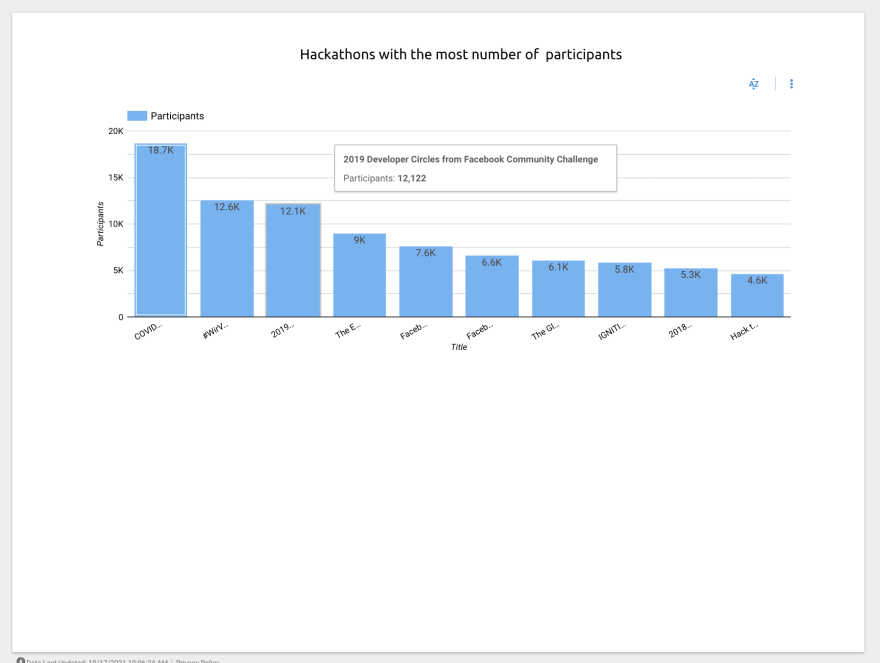
Visualization
Interactive Visualization: https://datastudio.google.com/reporting/269afbc3-e982-4fef-aee5-08010b427070 (Open to interactive with visualization playground)
User Interactive graphs and charts to analyze the hackathon's dataset



Team's Approach
- To build a dataset, we need to find a potential and authentic source, for which we used devpost as the source.
- To get the data from Website, we used Web Scraping tools which helps in getting the raw data
- We have used Selenium to scrape the website.
- We used a Chrome Web Driver to create the automation of scrolling and scraping the data.
- After Scraping, we got the raw data which is processed further and cleaned.
- The clean data is stored as a dataset in a CSV file.
- Unique datapoints like Number of participants, Start Date, End Date, Location(Online/Offline location), Prize Money, Themes
- After obtaining a decent dataset, we used Google Studio to provide insights of the dataset and relations between the variables in the dataset.
Reflection
- ### Problems
- While scraping the website, the content inside website is not rendered as static content.
- As the content is dynamic one, it is hard to scrape.
- The website has a pagination effect based on page scrolling. So, initially
xitems are loaded in the website and on scrolling anotherxitems are loaded and so on. - Unless we scroll we can't scrape the entire dataset.
- ### Future Scope
- The Dataset can be used to build a Machine Learning Model (to help in picking a theme/prize money/participant estimation and also in analyzing the trends of Hackathons)
- Automation of Scraping using Job Schedulers(CI/CD) to scrape data periodically
- Large data can be scraped from various sources
- Scraping process can be further optimized by using mutlithreading. ## Team DaHack

Top comments (0)