Authored by Sebastian Zangaro
"A fast-moving technology field where new tools, technologies and platforms are introduced very frequently and where it is very hard to keep up with new trends." I could be describing either the VR space or Data Engineering, but in fact this post is about the intersection of both.
Virtual Reality – The Next Frontier in Media
I work as a Data Engineer at a leading company in the VR space, with a mission to capture and transmit reality in perfect fidelity. Our content varies from on-demand experiences to live events like NBA games, comedy shows and music concerts. The content is distributed through both our app, for most of the VR headsets in the market, and also via Oculus Venues.

From a content streaming perspective, our use case is not very different from any other streaming platform. We deliver video content through the Internet; users can open our app and browse through different channels and select which content they want to watch. But that is where the similarities end; from the moment users put their headsets on, we get their full attention. In a traditional streaming application, the content can be streaming in the device but there is no way to know if the user is actually paying attention or even looking at the device. In VR, we know exactly when a user is actively consuming content.
Streams of VR Event Data
One integral part of our immersive experience offering is live events. The main difference with traditional video-on-demand content is that these experiences are streamed live only for the duration of the event. For example, we stream live NBA games to most VR headsets in the market. Live events bring a different set of challenges in both the technical aspects (cameras, video compression, encoding) and the data they generate from user behavior.

Every user interaction in our app generates a user event that is sent to our servers: app opening, scrolling through the content, selecting a specific content to check the description and title, opening content and starting to watch, stopping content, fast-forwarding, exiting the app. Even while watching content, the app generates a "beacon" event every few seconds. This raw data from the devices needs to be enriched with content metadata and geolocation information before it can be processed and analyzed.
VR is an immersive platform so users cannot just look away when a specific piece of content is not interesting to them; they can either keep watching, switch to different content or—in the worst-case scenario—even remove their headsets. Knowing what content generates the most engaging behavior from the users is critical for content generation and marketing purposes. For example, when a user enters our application, we want to know what drives their attention. Are they interested in a specific type of content, or just browsing the different experiences? Once they decide what they want to watch, do they stay in the content for the entire duration or do they just watch a few seconds? After watching a specific type of content (sports or comedy), do they keep watching the same kind of content? Are users from a specific geographic location more interested in a specific type of content? What about the market penetration of the different VR platforms?
From a data engineering perspective, this is a classic scenario of clickstream data, with a VR headset instead of a mouse. Large amounts of data from user behavior are generated from the VR device, serialized in JSON format and routed to our backend systems where data is enriched, pre-processed and analyzed in both real time and batch. We want to know what is going on in our platform at this very moment and we also want to know the different trends and statistics from this week, last month or the current year for example.
The Need for Operational Analytics
The clickstream data scenario has some well-defined patterns with proven options for data ingestion: streaming and messaging systems like Kafka and Pulsar, data routing and transformation with Apache NiFi, data processing with Spark, Flink or Kafka Streams. For the data analysis part, things are quite different.
There are several different options for storing and analyzing data, but our use case has very specific requirements: real-time, low-latency analytics with fast queries on data without a fixed schema, using SQL as the query language. Our traditional data warehouse solution gives us good results for our reporting analytics, but does not scale very well for real-time analytics. We need to get information and make decisions in real time: what is the content our users find more engaging, from what parts of the world are they watching, how long do they stay in a specific piece of content, how do they react to advertisements, A/B testing and more. All this information can help us drive an even more engaging platform for VR users.
A better explanation of our use case is given by Dhruba Borthakur in his six propositions of Operational Analytics:
- Complex queries
- Low data latency
- Low query latency
- High query volume
- Live sync with data sources
- Mixed types
Our queries for live dashboards and real time analytics are very complex, involving joins, subqueries and aggregations. Since we need the information in real time, low data latency and low query latency are critical. We refer to this as operational analytics, and such a system must support all these requirements.
Design for Human Efficiency
An additional challenge that probably most other small companies face is the way data engineering and data analysis teams spend their time and resources. There are a lot of awesome open-source projects in the data management market - especially databases and analytics engines - but as data engineers we want to work with data, not spend our time doing DevOps, installing clusters, setting up Zookeeper and monitoring tens of VMs and Kubernetes clusters. The right balance between in-house development and managed services helps companies focus on revenue-generating tasks instead of maintaining infrastructure.
For small data engineering teams, there are several considerations when choosing the right platform for operational analytics:
- SQL support is a key factor for rapid development and democratization of the data. We don't have time to spend learning new APIs and building tools to extract data, and by exposing our data through SQL we enable our Data Analysts to build and run queries on live data.
- Most analytics engines require the data to be formatted and structured in a specific schema. Our data is unstructured and sometimes incomplete and messy. Introducing another layer of data cleansing, structuring and ingestion will also add more complexity to our pipelines.
Our Ideal Architecture for Operational Analytics on VR Event Data
Data and Query Latency
How are our users reacting to specific content? Is this advertisement too invasive that users stop watching the content? Are users from a specific geography consuming more content today? What platforms are leading the content consumption now? All these questions can be answered by operational analytics. Good operational analytics would allow us to analyze the current trends in our platform and act accordingly, as in the following instances:
Is this content getting less traction in specific geographies? We can add a promotional banner on our app targeted to that specific geography.
Is this advertisement so invasive that is causing users to stop watching our content? We can limit the appearance rate or change the size of the advertisement on the fly.
Is there a significant number of old devices accessing our platform for a specific content? We can add content with lower definition to give those users a better experience.
These use cases have something in common: the need for a low-latency operational analytics engine. All those questions must be answered in a range from milliseconds to a few seconds.
Concurrency
In addition to this, our use model requires multiple concurrent queries. Different strategic and operational areas need different answers. Marketing departments would be more interested in numbers of users per platform or region; engineering would want to know how a specific encoding affects the video quality for live events. Executives would want to see how many users are in our platform at a specific point in time during a live event, and content partners would be interested in the share of users consuming their content through our platform. All these queries must run concurrently, querying the data in different formats, creating different aggregations and supporting multiple different real-time dashboards. Each role-based dashboard will present a different perspective on the same set of data: operational, strategic, marketing.
Real-Time Decision-Making and Live Dashboards
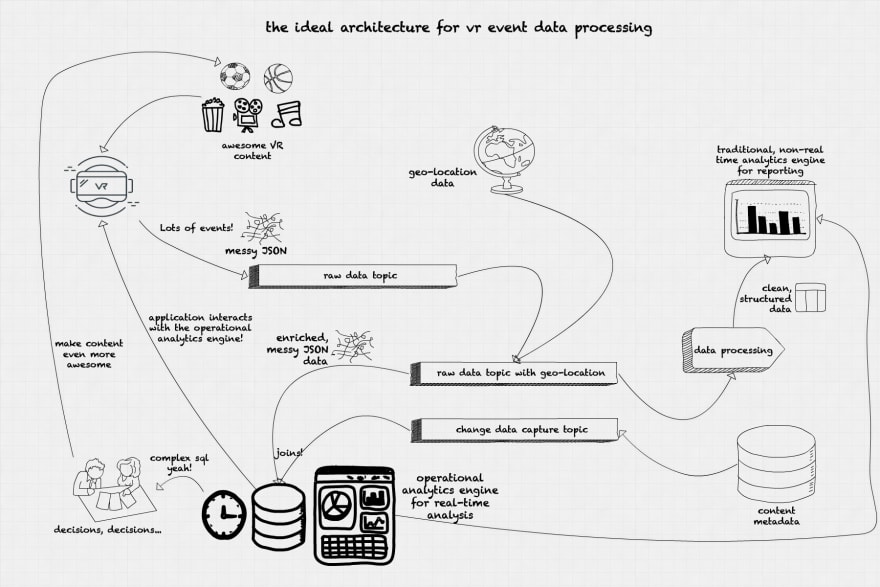
In order to get the data to the operational analytics system quickly, our ideal architecture would spend as little time as possible munging and cleaning data. The data come from the devices in JSON format, with a few IDs identifying the device brand and model, the content being watched, the event timestamp, the event type (beacon event, scroll, clicks, app exit), and the originating IP. All data is anonymous and only identifies devices, not the person using it. The event stream is ingested into our system in a publish/subscribe system (Kafka, Pulsar) in a specific topic for raw incoming data. The data comes with an IP address but with no location data. We run a quick data enrichment process that attaches geolocation data to our event and publishes to another topic for enriched data. The fast enrichment-only stage does not clean any data since we want this data to be ingested fast into the operational analytics engine. This enrichment can be performed using specialized tools like Apache NiFi or even stream processing frameworks like Spark, Flink or Kafka Streams. In this stage it is also possible to sessionize the event data using windowing with timeouts, establishing whether a specific user is still in the platform based on the frequency (or absence) of the beacon events.
A second ingestion path comes from the content metadata database. The event data must be joined with the content metadata to convert IDs into meaningful information: content type, title, and duration. The decision to join the metadata in the operational analytics engine instead of during the data enrichment process comes from two factors: the need to process the events as fast as possible, and to offload the metadata database from the constant point queries needed for getting the metadata for a specific content. By using the change data capture from the original content metadata database and replicating the data in the operational analytics engine we achieve two goals: maintain a separation between the operational and analytical operations in our system, and also use the operational analytics engine as a query endpoint for our APIs.
Once the data is loaded in the operational analytics engine, we use visualization tools like Tableau, Superset or Redash to create interactive, real-time dashboards. These dashboards are updated by querying the operational analytics engine using SQL and refreshed every few seconds to help visualize the changes and trends from our live event stream data.
The insights obtained from the real-time analytics help make decisions on how to make the viewing experience better for our users. We can decide what content to promote at a specific point in time, directed to specific users in specific regions using a specific headset model. We can determine what content is more engaging by inspecting the average session time for that content. We can include different visualizations in our app, perform A/B testing and get results in real time.
Conclusion
Operational analytics allows business to make decisions in real time, based on a current stream of events. This kind of continuous analytics is key to understanding user behavior in platforms like VR content streaming at a global scale, where decisions can be made in real time on information like user geolocation, headset maker and model, connection speed, and content engagement. An operational analytics engine offering low-latency writes and queries on raw JSON data, with a SQL interface and the ability to interact with our end-user API, presents an infinite number of possibilities for helping make our VR content even more awesome!

Top comments (0)