
Note: The starting of this post contains a bit of background to help interested beginners understand about transformer based networks. If you want to just see the exciting results, skip ahead to the Results section
Machine learning has been used effectively in recent times to solve several challenges faced by humans. In particular, there is been notable success in problems like classification, clustering, etc. With the advent of neural networks, we have seen some exciting applications, like age detection, recognizing objects in an image etc.
However, neural networks have never been very successful when dealing with text. This is understandable though. Anyone working in the field of language knows how complex and nuanced it can be. It can be especially hard to teach machines subtle intents like sarcasm, irony, etc. in text.
One of the challenges that has seen the most improvement in the past decade has been the task of natural language generation. You can see this all the time, right from the chatbots which handle your airline booking, to your Alexa, which responds based on your question. It is evident to the user however, that he's talking from a bot. The question therefore is, can we make the machines write pieces of text that won't be distinguishable from human written text?
Background
For a long time, a special type of neural network called Long Short Term Memory (LSTM) were used for text generation. To get an intuitive understanding of why they work, look at the conversation below:
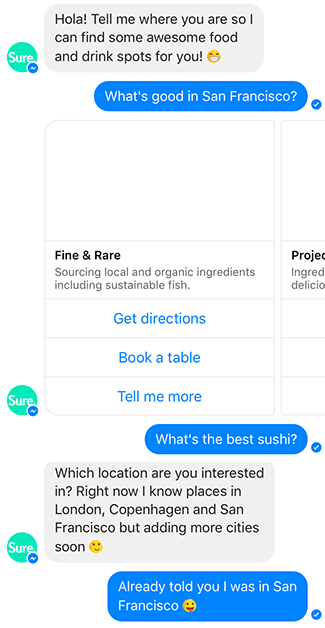
Basically, in language, we may often refer to something that we have said previously. As humans, it is automatic for us to understand what is being talked about (or "get the context"). If I ask my friend a simple question like "Did you catch the game last night?", I am making several assumptions on the fly, like my friend knows what game is being talked about, him being interested in the game, etc. This is much harder for a machine to understand. To achieve this, we try to store a bit of the context in the network, in terms of sequences (words or characters). During the generation of text, we try to predict the next sequence based on the previous n sequences. Here is an example of a simplistic LSTM:
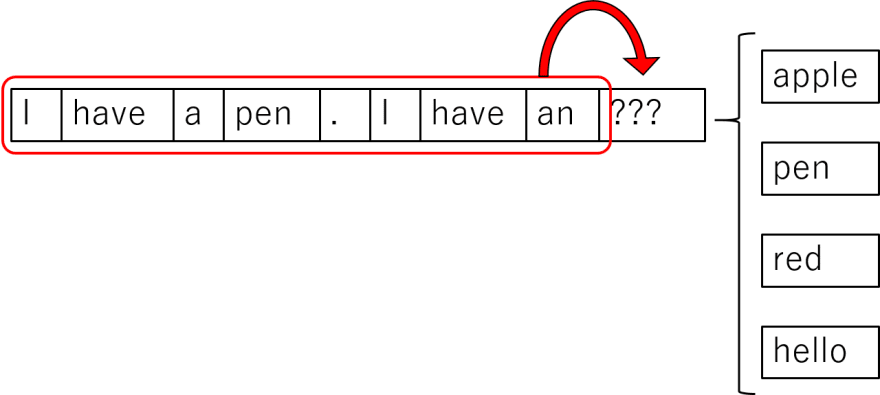
However, while we were able to get well structured, grammatically correct sentences using LSTMs, there was a clear lack of retaining context, which led to unsatisfactory results.
A Novel Approach
In 2017, Google introduced a new kind of neural networks called Transformer, which turns out to be excellent at dealing with text. To be very empirical, transformers differ from LSTMs in the way in which context is saved. Instead of saving sequence by sequence, the main understanding of the subject of the previous interactions are saved in the network. For the advanced readers who are comfortable with neural networks, I highly recommend reading the original paper, "Attention is all you need"
GPT-2
Using the transformer, OpenAI released a ground-breaking model this year, called GPT-2. This is a huge model, with 1.5 billion parameters, trained over 40GB of internet text. It has achieved a stellar performance, so much so, that OpenAI has not released the complete model yet, for fear of it being used in a negative manner. They have however, released two smaller models, with 117 million parameters, and 345 million parameters (The latter was released just last month!). The good news is that these smaller models, and with a bit of training on your data, you can get amazing results.
Results
The 117M model was used for the purpose of this experiment, and it was trained for about 1000 epochs on three different kinds of textual data:
- The books of A Song of Ice and Fire (popularly known as Game of Thrones)
- The essays of Paul Graham
- Short stories from the ROCStories dataset
Let's see now how the model performed on each of these datasets.
Short Stories
The ROCStories dataset contains of simple 5 sentence stories, written by students of University of Rochester. Here is an example from the dataset:
Jennifer has a big exam tomorrow. She got so stressed, she pulled an all-nighter. She went into class the next day, weary as can be. Her teacher stated that the test is postponed for next week. Jennifer felt bittersweet about it.
Now let's play a little game to answer our original question. Can you spot which of these was written by a human?

If you guessed that all three were generated by machines, then you are a very attentive reader! We tried this experiment at an expo, and out of the 18-20 people we asked, only 2 got the right answer. The first sentence was the prompt, and the rest is generated in each of these examples.
Now let's see the more exciting results. The text in gold is the prompt.
Game of Thrones

Essays of Paul Graham
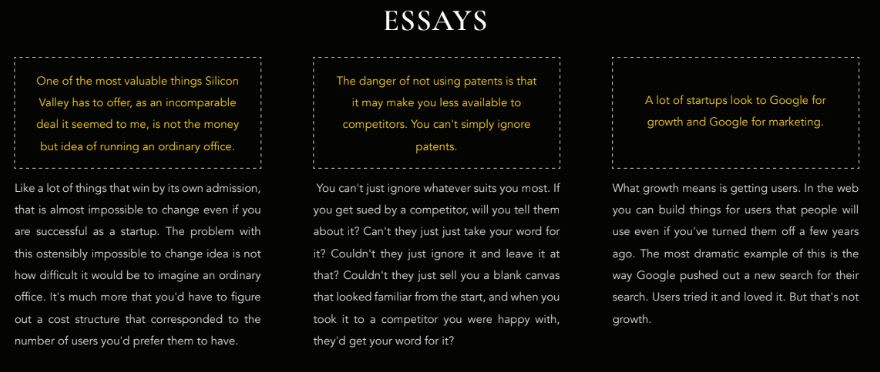
Key takeaways
- The format of the generated text by the model changes significantly according to the training data.
- The generated text vocabulary is in harmony with the training data. Note how in the Game of Thrones examples, it uses terms and phrases that are only canon in the books. In the essays example, the generated text is much more serious and talks about worldly issues.
Where's the code?
All of the code I used to get these results are at github. I have written a comprehensive README to explain my source files, but if anyone needs a tutorial on using this model, write in the comments, and I'll make one.
To read more about our specific methodology and evaluation criteria, you can read our complete report here.
Conclusion
GPT-2 has already seen some great performance, as covered by VentureBeat and many other articles. The purpose of this post was to show how you can achieve powerful results by tweaking the model slightly for any kind of textual data you want. Sure, even now, the difference between machine generated text and human written text may be apparent to some readers. But the difference is much narrower in comparison, and this was with just a smaller model. All the people who have experimented with the full model of GPT-2 have been extremely impressed with it.
Hope you enjoyed this long read! Follow me for more beginner friendly content on software development and machine learning

Top comments (0)