
Photo by Henry Dick on Unsplash
Data warehousing was introduced in 1988 by IBM researchers Barry Devlin and Paul Murphy.
Since then the concept has evolved and taken on a life of its own. Increasing challenges and complexities of business have forced data warehousing to become a distinct discipline. Over the years this has led to best business practices, improved technologies, and hundreds of books being published on the topic.
But we don't want to focus on the past.
Instead, this article will discuss the future of data warehousing and how it has been impacted by the cloud. Over the past decade, we have seen multiple new cloud data warehousing technologies pop up and be responsible for the largest software IPOs in history.
All because of a data warehouse.
A technology and discipline that is rarely even discussed in most computer science or IT degrees in college. Yet almost every large and medium organization has some form of the data warehouse.
It's estimated by the year 2025 that the data warehouse market will near double from its current 18 billion USD market cap to 30 billion USD.
In this article, we will not only discuss why so many businesses are willing to invest in a data warehouse but we will also discuss how the cloud has improved data warehouses as well as leveled the playing field for businesses of all sizes.
So whether you want to learn more about data warehousing or you are a director, small business owner, or CEO this article will help you understand the vast world of data warehousing.
Why Invest In A Data Warehouse?
Before we talk about Cloud data warehousing. We need to understand why data warehousing is important.
Investing in a data warehouse is very expensive. Regardless of the size of your company.
At the end of the day, all a data warehouse is, is a copy of the same data from your internal databases and third-party tools.
So why not just pull the data from there?
There are several reasons.
Performance
Performance is one of the main reasons for creating a data warehouse. Just pulling data from an application database for analytical purposes can cause problems both for the analytics as well as for the application.
If analysts were to directly access application databases, they may slow down their performance because often analytical queries will analyze numbers of rows at one time.
Also, due to the sheer number of updates, and transactions occurring, it is much more likely that either a table will lock or a server will reach capacity which could impact users.
And those are only some of the more surface-level performance issues.
Some of the other performance factors you will deal with are caused by the fact that analytical processes are very different than transactional.
We can look at the image below and see a general difference.

Transactions generally involve a small number of rows and are either inserting, deleting, or updating.
Analytical clauses are usually pivoting, aggregating, and attempting to create some sort of metric. One SQL clause might be querying entire tables all at once.
An application database is developed to better handle the first case and not the second.
Application databases require lots of joins due to their level of normalization. This isn't just hard for analysts and users to deal with. It can also slow down general queries.
Also, Analytical queries will often benefit from a more columnar approach to how the data is stored(which is very common in modern data warehouses) and not a row based version.
Overall, the design of a data warehouse, infrastructure, and general usability requirements push for companies to develop data warehouses.
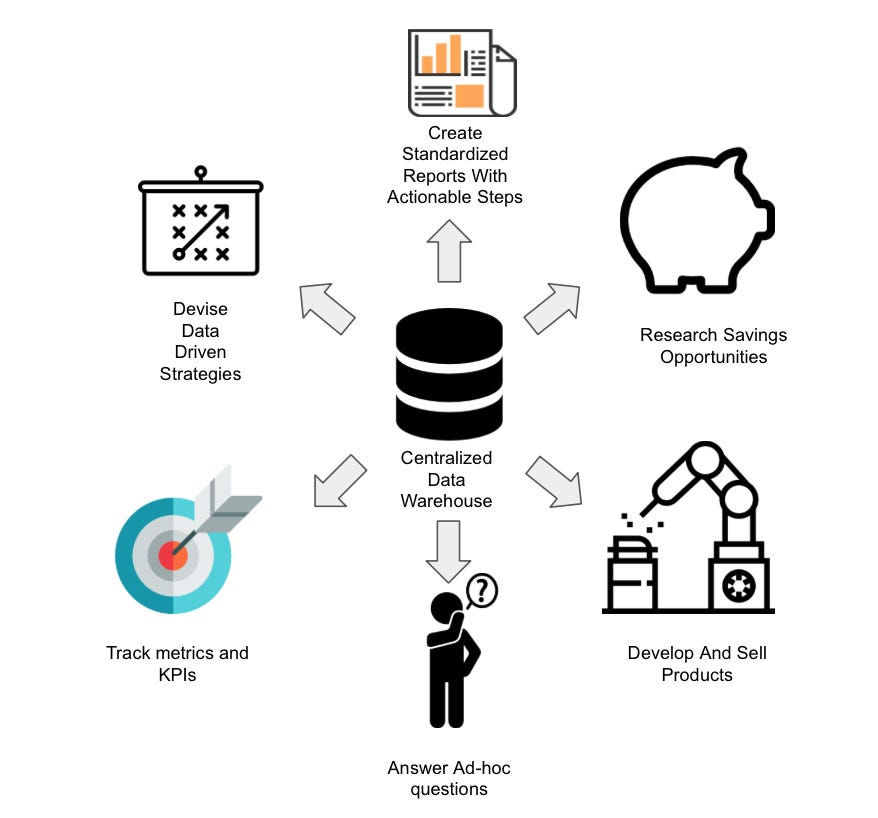
Centralized Data For Analytics
One of the other key factors about a data warehouse is that it centralizes all of your companies' various workflows in one place.
For example, if your teams were to just use the application databases and third party reporting. They would need to extract, download, and then mesh all the data together in their Excel and Tableau dashboards and documents.
Besides being very error-prone, this is also very time-consuming. We aren't even referring to all the cleaning of data required.
But just the process of pulling it all together.
Instead, having a centralized data warehouse avoids this problem by creating a single layer of data where analysts can interact with the data.
The data itself is already processed and cleaned, and often there is the addition of relational keys between different data sets.
This makes it much easier for analysts to start meshing data from finance, sales, HR, and all the other business departments without pulling the data out manually.
Ease Of Use For Analysts

If you have followed some of our previous articles where we discussed how to design a data warehouse, then you know that data warehouses tend to follow a star or snowflake schema.
These schemas are not just often faster in terms of performance due to their reduction of joins and slightly denormalized design.
They are also conceptually easy for analysts to understand.
The focus on a central business workflow as a fact table with all the descriptive information surrounding it in dimension tables is not difficult to understand.
This is much friendlier than the overly normalized application database that will take time for analysts to understand and will often cause problems as analysts incorrectly join across tables.
Thus, the design of a data warehouse in itself is much more friendly and can save a lot of time and future headaches.
Despite all these benefits, data warehouses were still running into a lot of issues with performance, cost and general administration.
Benefits Of Cloud And Modern Data Warehouses
The original data warehouses were built on servers on-premise. Often, if you wanted to scale the size of the data warehouse or increase the speed you would need to increase memory or ram by getting more powerful servers.
This was expensive as well as time-consuming.
Also, managing data warehouses required specialized database managers who had to deal with endless data access requests and downed servers.
Then, came the Cloud.
Now besides being a vague abstraction of a massive ecosystem of complex services and products. The cloud did challenge the status quo of data warehouses.
It allowed a company of any size to manage their large data without risking the purchase of a large server.
Also, companies like Amazon, Microsoft, and Snowflake all started to develop data warehouse technology that was data warehouse first. Before this, many(not all) data warehouses were just built on standard database technology.
This was fine when we had smaller data sets and limited users.
However, with more and more companies becoming data-driven, the need for data warehouses that could handle hundreds to thousands of users and petabytes of data became a must.
Most modern data warehouses were developed to distribute compute easily, be scalable as well as elastic, and be easy to manage.
Coupled with the push for more data scientists and analysts in every company, data warehouse usage exploded.
Distributed File Processing/Massively Parallel Processing(MPP)
Distributed processing is not a 21st-century concept. But it has become a necessity in the 21st century for processing the terabytes/petabytes of data companies have stockpiled.
Different data systems might reference it differently. For example, Map Reduce is used in the underlying technology of HDFS and HBase. This was developed to take advantage of cheap hardware and horizontal scaling to reduce the amount of time it took to manage data.
Technologies like Redshift, Azure SQL Data Warehouse, and Snowflake all use what is known as Massively Parallel Processing or MPP. In general, this runs on more expensive technology but still has a conceptually similar process.
In an oversimplified way, many of these concepts work similarly(sort of). There are a lot of nuanced differences and sadly both terms do get used interchangeably.
This is because, on a very high-level, developers simplify both processes as Taking a lot of data and processing it over lots of different nodes.
Now there is some truth here as both systems can coordinate data processing across multiple machines.
In the end, both concepts not only improves the speed of the data being processed but can increase the number of users able to query the data effectively by increasing the number of machines involved.
This is far from the day where all the queries had to run on one machine.
It's not to say a company couldn't develop its own distributed data warehouses. However, it would require that companies hire more developers to not only design but manage these complex systems.
In the end, this would likely be more expensive.
Elasticity
Many modern cloud data warehouses can be set up to be elastic. This means the data warehouse dynamically allocates computing resources depending on what is required. By only using the number of computing resources required teams can reduce their cost while still benefiting from high performing data warehouses.
This wasn't the case with on-premise servers where you were often stuck with the limited memory resources your company had. Also, companies would often have to buy more computing resources than required leading to a lot of wasted compute.
Scalability
The concept of scalable can sometimes be confused for elastic and vice versa. However, unlike elastic, scalability refers to the infrastructure itself.
To put this in perspective. In the past, if a company needed to increase the size of its data warehouse it would often need to migrate it to a different and larger server. This wasn't always a straightforward process and sometimes a new server would need to be acquired.
In the cloud, scaling up your system can sometimes be as quick as dropping down a selector box and picking the new size. This ability to scale without the need of waiting for a new server as well as a decent amount of employee time makes Cloud a very viable option.
Reduced Database Management
Having on-premise servers means you need to have server administrators and database administrators on top of your entire BI and data science teams.
When servers go down or need to be upgraded, this can cause a lot of downtimes. Also, it requires your server admins, and database administrators to spend time focused on upgrading systems vs. doing other work.
Much of these expenses are put on the cloud providers when you start using services such as AWS and GCP. This isn't to say you reduce 100% of the administration.
However, you do make administrating more machines easier from the various management consoles compared to on-premise.
Disaster Recovery
Servers are not impenetrable and there are many ways they can fail. Whether it be due to a natural disaster like hurricanes or general wear and tear. Servers are constantly failing and needing to be backed up.
The cloud makes this easy. Your team doesn't need to do anything other than deciding how you will keep backups of your data warehouse. You can take snapshots of your data warehouses, make duplicates, or store backups in the various systems provided by the cloud providers.
Also, the cloud provider might even allow you to create duplicates of your data warehouse in other server farms across their network.
Competitive Advantage For Small And Medium Companies
Large corporations can often afford to spend millions of dollars on servers, database managers, and server administrators. Small 7-8 figure companies often only have 1-2 IT people who do everything from managing servers to developing their Apps.
Cloud data warehousing allows small and medium-sized companies to have access to the same level of technical expertise and technology as large corporations for a fraction of the cost.
Examples Of Cloud Data Warehouses
When it comes to selecting a modern cloud data warehouse, there are tens of options. Companies from Amazon to Oracle have all developed their own cloud data warehouse.
Redshift
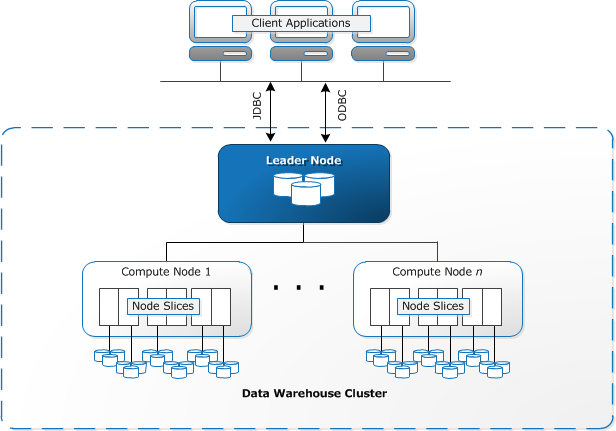
Image Source: Amazon
Redshift is a column-oriented cloud-based data warehouse system built by Amazon. Some say it was so they could stop relying on Oracle after the CEO of Oracle boasted about Amazon needing Oracle to stay in business. Jokes aside, Redshift was one of the many cloud services Amazon used to cut their reliance off on Oracle.
Redshift cluster comprises multiple machines which store a fraction of the data.
These machines work in parallel, saving data so we can work upon it efficiently. Here, Redshift has some compute nodes that are managed by leader nodes to manage data distribution and query execution among the computing nodes. There are also other design benefits like Massive Parallel Processing (MPP).
By using the compute nodes to calculate the intermediate results and then having them pass back those results to be aggregated by the leader node, Redshift is able to improve performance for many calculations.
In addition, your team can help improve performance by adding in distribution keys that can help Redshift develop a better execution plan, leading to better performance.
It is important to note that Redshift has a lot of nuances compared to your standard RDBMS like Oracle and SQL server. So how your team designs your data might shift in order to take advantage of all of the performance improvements Redshift can offer.
BigQuery
Image Source: Google Cloud
BigQuery is a Serverless enterprise-level data warehouse built to help manage a companies data in BigQuery itself as well as in other data sources like BigTable.
This application can execute complex queries in a matter of seconds on what used to be unmanageable amounts of data. You don't need to provision resources before using BigQuery, unlike many RDBMS systems. BigQuery allocates storage and query resources dynamically based on your usage patterns.
Similar to Redshift BigQuery is a columnar storage database that also allows for MPP. What is interesting here is we have actually read several articles disputing the fact that BigQuery actually allows for MPP as it is based on Hadoop and thus can't be MPP.
However, it seems like Colossus(or the file infrastructure underneath Bigquery that is based on Google FS) merely stores the data. Then Borg (Google's large-scale cluster management) allocates resources to Dremel jobs (which are typically executed over Google's Web UI or REST.) In this way, we would say this is why Google claims MPP in their own articles and content.
To add to that BigQuery also separates compute from storage. This added bit of design choice provides GCP its ability to manage so many queries concurrently.
In addition, BigQuery supports SQL format and offers accessibility via command-line tools as well as a web user interface. It is a scalable service which allows user to focus on analysis instead of handling the infrastructure. BigQuery is by design append-only preferred.
Personally, I really enjoy the online web UI that BigQuery has. No need to set up any connectors or download any third-party tools to interact with the data. You can easily access a very user-friendly interface within seconds.
If you want, feel free to test it out. GCP even has several public data sets you can query.
Microsoft Azure SQL Data Warehouse
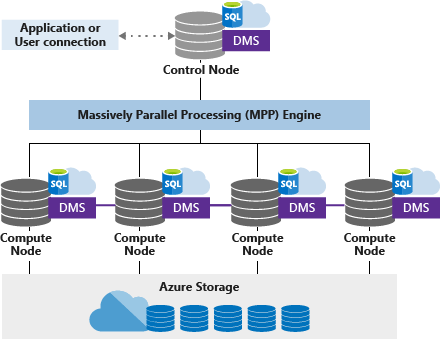
Image Source: Microsoft
Microsoft SQL Server instances have been used as a data warehouse across multiple companies and industries. With the advent and popularization of the Cloud, Microsoft developed its Azure SQL Data Warehouse that has many similar benefits to other cloud data warehouses.
Similar to Redshift and BigQuery, SQL Data Warehouse stores data into relational tables with columnar storage. This format significantly reduces data storage costs and improves query performance.
In addition, like other modern data warehouses, SQL Data Warehouse uses massively parallel processing to quickly run complex queries across petabytes of data. All of these infrastructure improvements along with the fact that Azure was developed to easily integrate with the rest of Microsoft's systems, make Azure a very popular option for data warehouses.
Snowflake
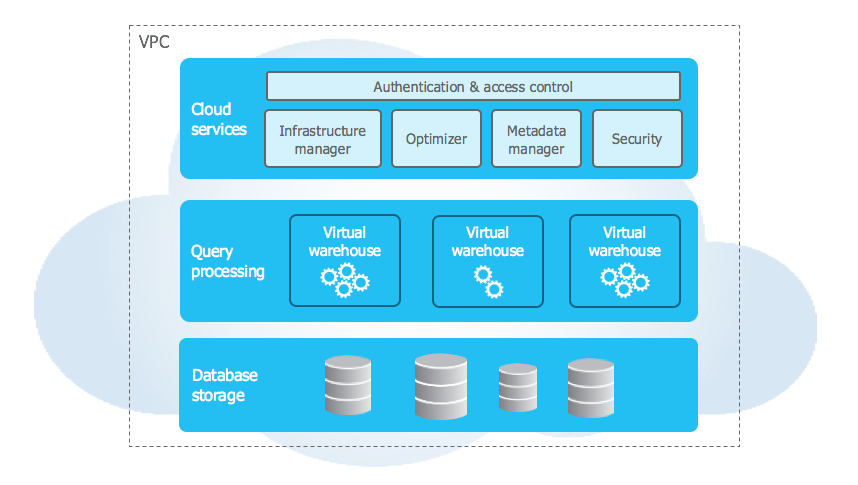
Image Source: Snowflake
Snowflake has been around for much longer than its recent IPO. In fact, I have been to multiple Snowflake sales talks. Snowflake technology and approach are interesting. They focused on developing a data warehouse on top of other cloud providers like AWS and Azure.
What snowflake has done is develop a multi-cluster, shared data architecture that, separates compute resource scaling from storage resources, thus enabling seamless, non-disruptive scaling.
For example, on AWS it basically runs using S3 and EC2. S3 acts as the storage layer and EC2 acts as the compute.
This makes it easy to scale both on the compute and storage side. In addition, snowflake has features like secure data transfer and sharing with partners outside of your company and semi-structured data management.
To put it simply, there is a reason Snowflake is so popular. Of course, Snowflake's marketing budget is also clearly very large based on the number of ads, content, and other forms of marketing they put out constantly.
Oracle Autonomous Data Warehouse
Oracle fell behind for a bit for cloud data warehouses. When Amazon migrated all of their systems off of Oracle and onto Redshift and their other cloud databases it was probably a wake-up call. However, Oracle quickly built out and developed their Cloud data warehouse competitor.
They developed what they called the Oracle Autonomous Data Warehouse. Similar to many of the other cloud data warehouses Oracle offers an elastic data warehouse that is automatically backed up.
In addition, the data warehouse attempts to automatically tune your data warehouse for improved performance. In oracle's own words, their data warehouse is self-driving, self-securing, and self-repairing.
This means it automatically monitors and tunes processes, protects against attacks, and the ability to perform maintenance tasks with fewer than 2.5 minutes of downtime per month, including patching.
On top of this, supposedly, at least according to Oracle, it's Autonomous Data Warehouse actually outperforms Redshift.
Similar to Microsoft's Azure Data Warehouse, Oracle provides a much more complete and integrated environment. Not only does Oracle have its own set of ETL tools and dashboard tools, but they also attempt to make it easy to develop notebooks and machine learning models off of their data warehouse.
This has been the business model for Oracle for a while. Don't just build a single piece of infrastructure, but try to get as much vendor lock-in as possible.
With all these cloud providers, it is important that you mind vendor lock-in.
Is It Time To Migrate To A Cloud Data Warehouse?
Data warehousing isn't what it used to be. With modern columnar data warehouses that are often inserted and read-only, the traditional schemas and ETLs/ELTs are needing to be updated.
The trade-off is data warehouses that are often cheaper, faster, and can handle more users than in prior years. Thanks to improvements in design, software, and a push for more data-driven decisions, data warehouses have improved in leaps and bounds.
Thanks so much for reading. Our next post will discuss ETLs, ELTs, and how we actually get data from your application databases and third parties and into your data warehouses where data scientists and analysts can start using them.
Until then, if you want to read or watch more about big data, data science, machine learning, then check out the content below.
4 SQL Tips For Data Scientists
How To Improve Your Data-Driven Strategy
What Is A Data Warehouse And Why Use It

Top comments (4)
Wow despite its offering a superficial overview its really deep in analysis. I had never came across the other database besides bigquery and snowflake.
I was tempted to go deeper...but it was already close to 3000 words and I think if I were to go deep on some of these topics then I would just focus on one data warehouse or one concept.
Like a post just about MPP vs Map Reduce vs Distributed computing...or something
Yeah, sometimes I wish I could write that amount of technical information into a single article but the time investment for a long form article is usually quite crazy.
who is this us? what paper is this?