This blog post takes you through the process of setting up Continuous Integration for building docker images via Dockerhub and Github, and via Github Actions. It also contains a condensed summary of important notes from the documentation.
Goal: Gain an overview of CI and actually use it to get automated builds of the docker images that built for my datascience toolbox.
Essentially I want to be able to a status check the docker containers that I am maintaining. Eventually I want to setup a series of checks that the libraries and software tools that I use are working as expected. Though dockerhub enables containers to be built on a commit, I would also like a CI/CD pipeline to be setup in order to understand how it actually works.
Pre-requisites : a dockerhub account and some dockerhub image to work off with. The dockerfile and related source code should be available in a github repository.
The github repository I will use is shrysr/sr-ds-docker and the dockerhub image shrysr/shiny. Within the github repository, the shiny folder contains all the files needed to build the shiny image. Note here that the rbase image is required for the shiny image to build.
Plan [3⁄3]
- Complete reading the Github documentation on github actions.
- setup a github hosted runner
- [-] Setup a self-hosted runner :
Lower priorityPostponed because it is better to understand how a runner works with github code before allowing any github code to run on my VPS.
- Create a CI integration between Dockerhub and Github
- Expand the CI setup to the datascience docker containers.
Setting up a Github Runner [0/1]
A github runner is essentially creatd by using the Actions tab. There is a marketplace of Actions that can be used for free. Actions already exist for many popular workflows like building a docker image and pushing it to some registry.
Apparently the first action has to be a checkout of the repository. Without this step, the process will not work. I spent a long time in
Specify build context to a specific folder. i.e do not use build . because then the context and paths will not work, thus the COPY type functions won’t work.
Apparently Github will reocognise yaml files only within the .github/workflows location, though I may be wrong. If their autosuggestion for the action setup is used, the folder is created automatically. However, thankfully,any YAML file created in this folder will be run by Github actions. Refer to the notes below regarding the API limitations. Since it appears that this YAML file cannot be used for say Travis or CircleCI, it may be good to have these within the github folder anyhow.
Getting started was as simple as using the actions tab when the repository is opened. A basic YAML template is offered and was actually sufficient for me to quickly get started.
The build context is specified by the location of the file in this case, and the tag can be specified. Currently, I’m using an ephemeral container.
- An idea for a test would be like : run an ubuntu docker container, and then call the shiny container within it. Get the container running, and then also devise some output via R scripts. One way could be load a bunch of packages. Another way could be to get a shiny app to run and provide some kind of temporary output. This has to be refined further. <!--listend-->
name: Docker Image CI
on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: shiny
run: docker build . --file /shiny/Dockerfile --tag my-image-name:$(date +%s)q
The build details can be found by clicking on the individual jobs. The raw log can be downloaded for verbose logs to enable a good text search. During a live build process, there is some lag between the log update and the webpage refresh, however it seems within tolerable limits as of now.
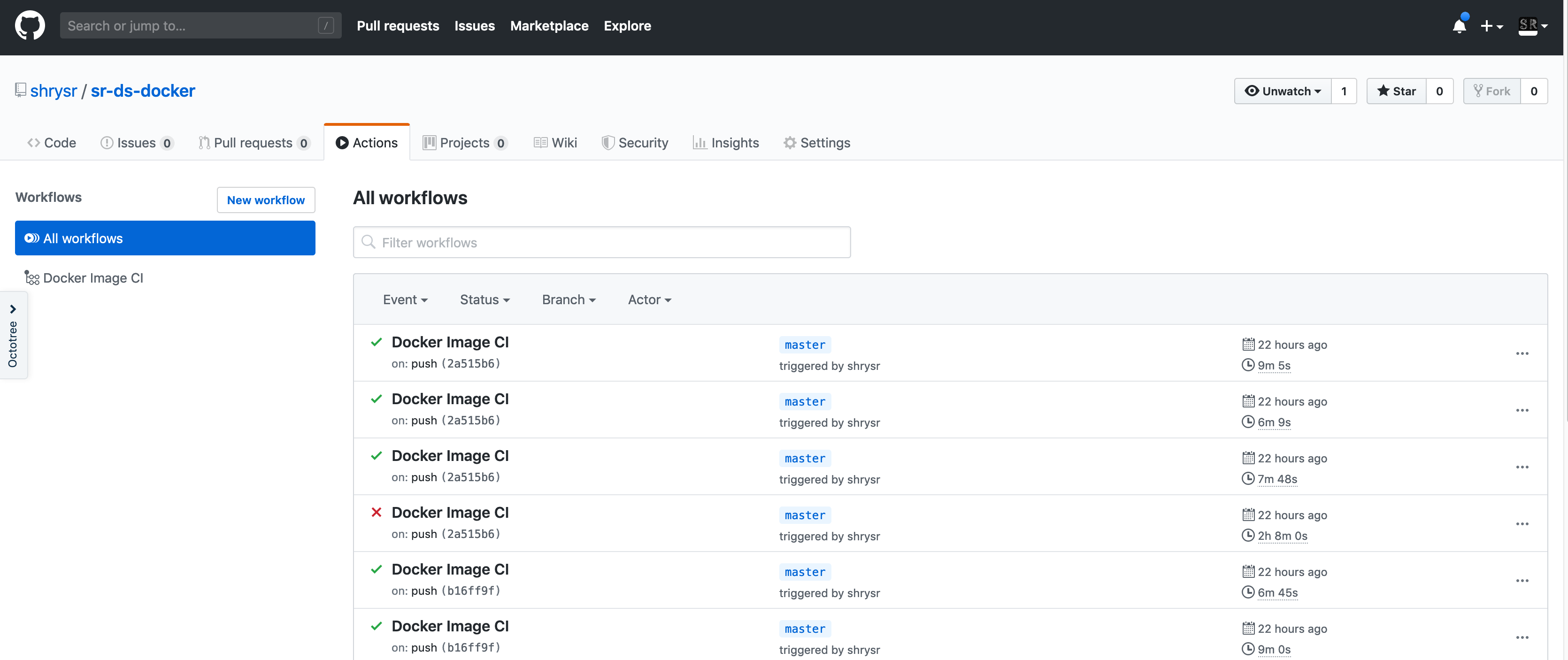
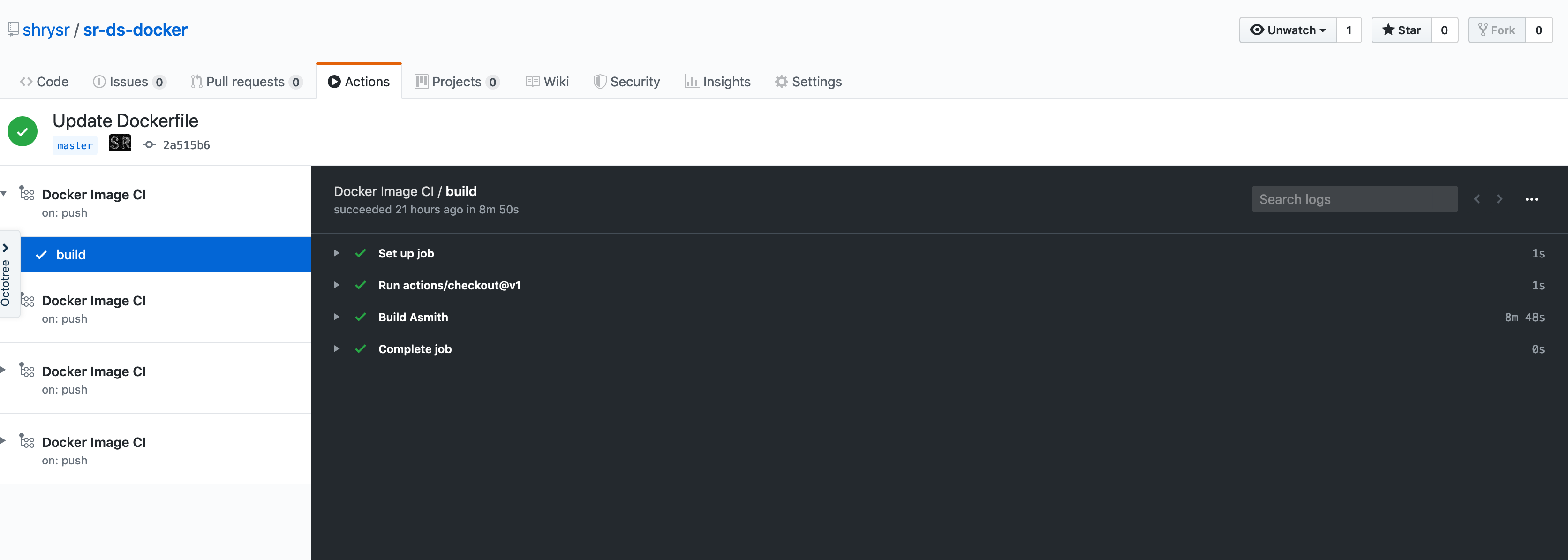
Notes about build and queue
The free build time is rather long and the configuration of the servers is unknown. It is probably a lot faster to build the images locally and push them to dockerhub. However, minor image updates and small image builds are quite quick to take place. The key is getting a single successful build off a github commit after which the context is established and new layers need not take the same amount of time.
All this being said, the queue time in dockerhub is very long compared to the queue time of builds via actions on Github. The free tier is actually quite generous for a lot of room to play and experiment. It would also appear that the github computer servers are faster than Dockerhub.
Setting up CI via Dockerhub and Github
The pre-requisite is of course that you have a docker image in your repository.
This process is relatively simple. Login to your Dockerhub account and click on the fingerprint like icon to reach the account settings. Use the linked accounts tab and setup github with your login credentials.
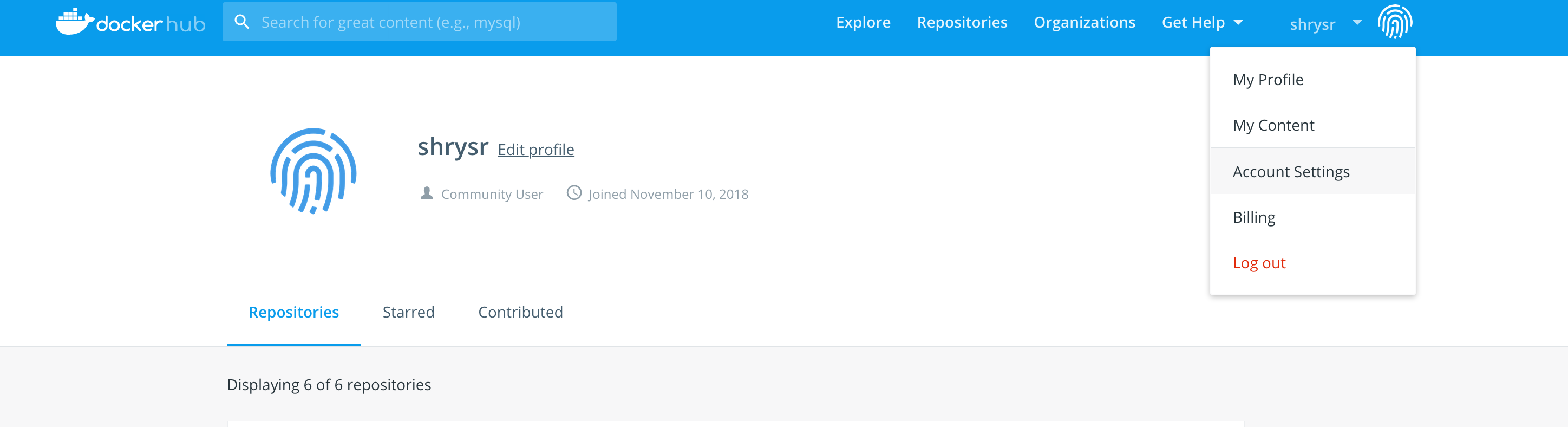
Next, select your docker image repository and click on the Builds tab and click on setup automated builds.

Now you have the option to select a github repository and settings are available to point to a particular branch or a particular Dockerfile as well.
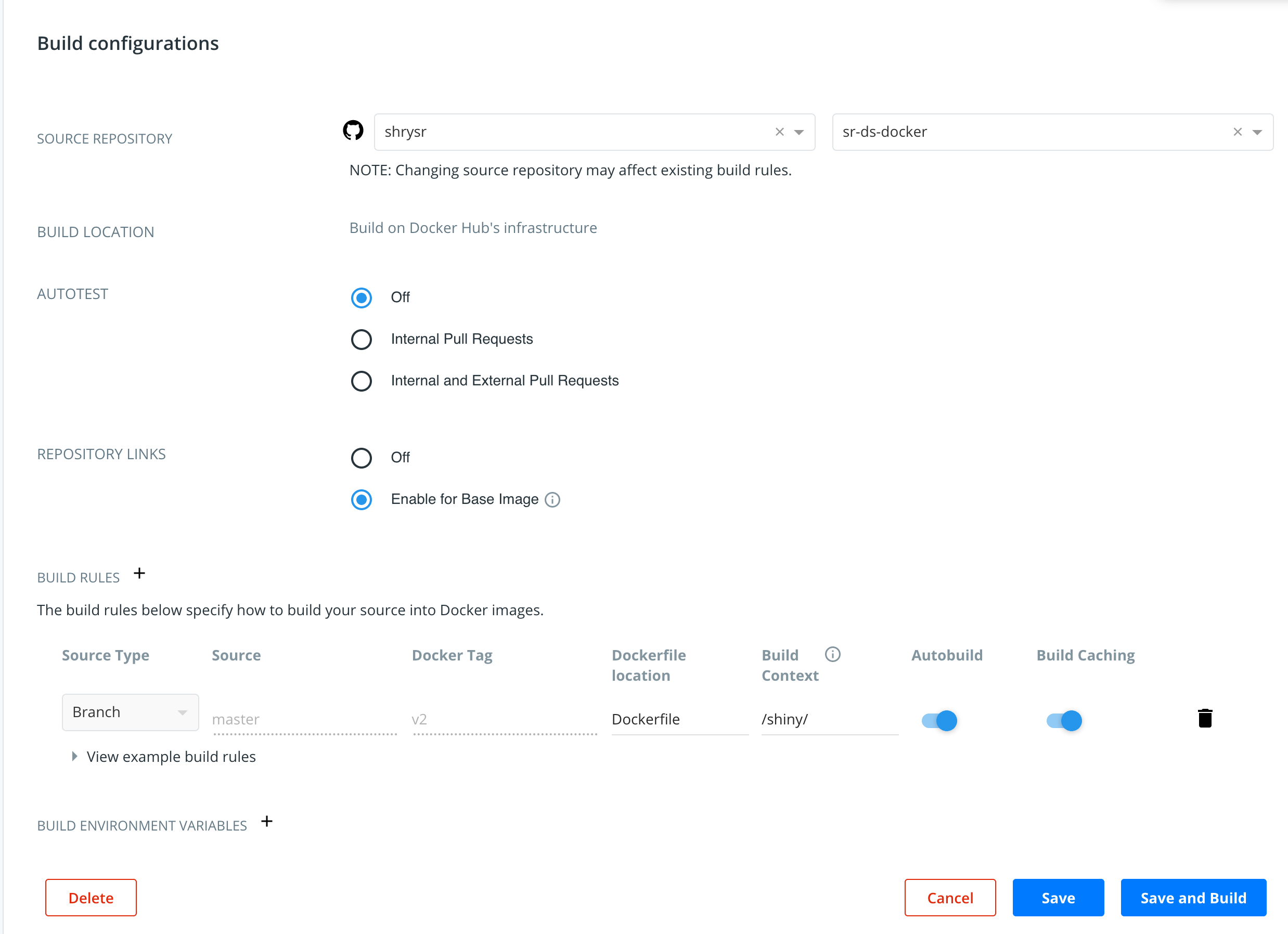
Note the option Enable for Base Image for the Repository Links. This can be set enabled if your image depends on another image. Suppose that base image is updated, then a build will be triggered for your image.
The source option can be set to a named branch or a tag and the docker tag must also be specified. The build context helps if you have multiple docker configurations stored together.
Note also below that Environment variables can be specified thus enabled a more customised deployment of the image. The variable can be used to specify things like the username and password, Rstudio version or r-base version, etc. Docker image tags are typically used to demarcate these more easily.
Here’s how the build activity looks like on Dockerhub:
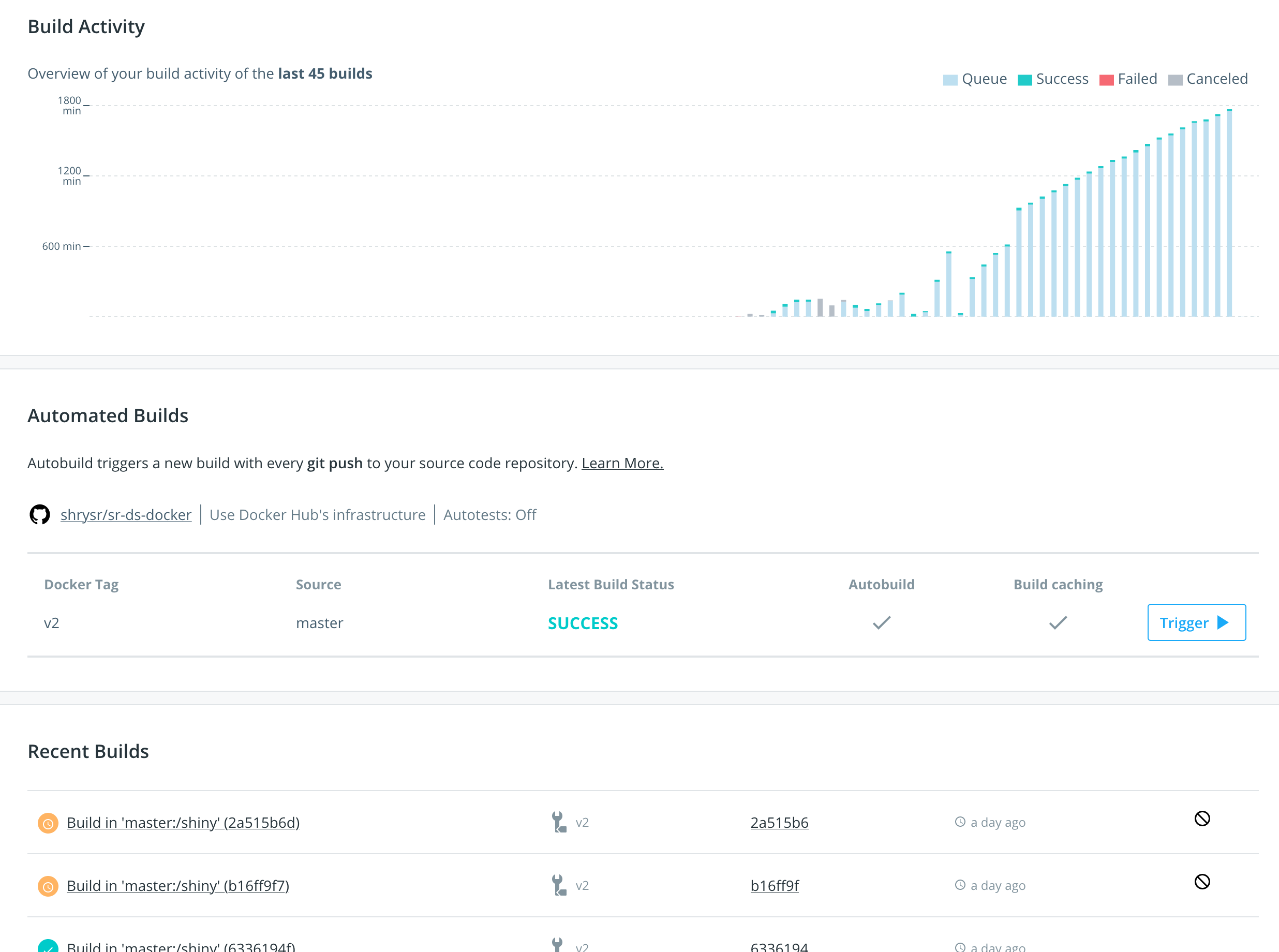
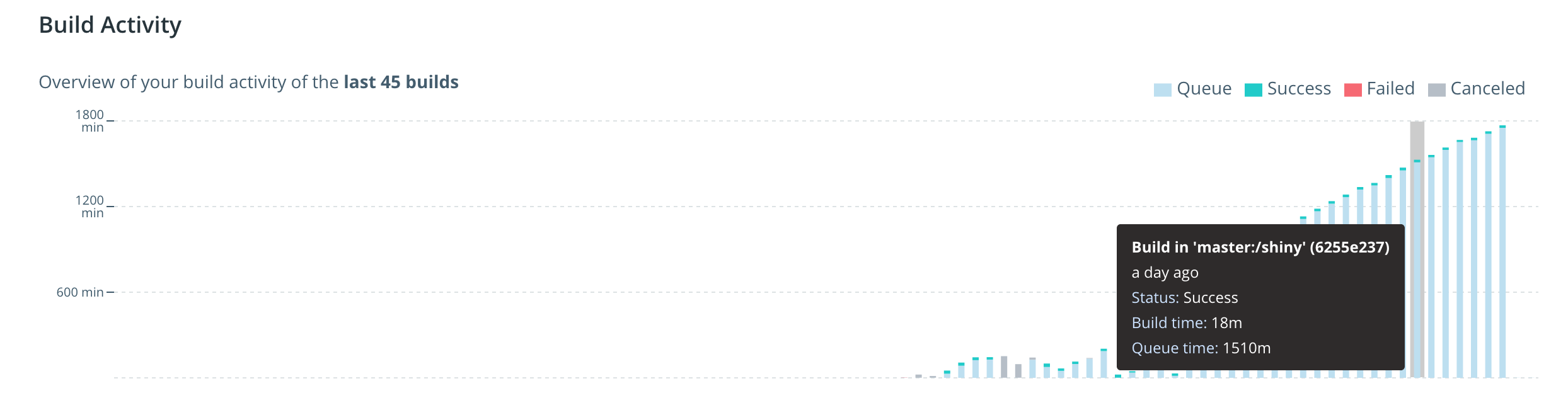
General notes
Overview of components
For any code to run, there has to be a server or a computer to run it. This is called a runner and one can be created on a self-hosted platform or there are services with different tiers on which the runners can be placed.
Reference: Github docs
GitHub Actions enables you to create custom software development life cycle (SDLC) workflows directly in your GitHub repository. GitHub Actions is available with GitHub Free, GitHub Pro, GitHub Team, GitHub Enterprise Cloud, and GitHub One
Workflows run in Linux, macOS, Windows, and containers on GitHub-hosted machines, called ‘runners’. Alternatively, you can also host your own runners to run workflows on machines you own or manage. For more information see, “About self-hosted runners.”
You can create workflows using actions defined in your repository, open source actions in a public repository on GitHub, or a published Docker container image. Workflows in forked repositories don’t run by default.
You can create a workflow file configured to run on specific events. For more information, see “Configuring a workflow” and “Workflow syntax for GitHub Actions”.
GitHub Marketplace is a central location for you to find, share, and use actions built by the GitHub community.
On API limits
Most of these limits are not applicable to self-hosted runners. Exception to the above : “You can execute up to 1000 API requests in an hour across all actions within a repository.”
There are some limits on GitHub Actions usage. Unless specified, the following limits apply only to GitHub-hosted runners, and not self-hosted runners. These limits are subject to change.
You can execute up to 20 workflows concurrently per repository. If exceeded, any additional workflows are queued.
Each job in a workflow can run for up to 6 hours of execution time. If a job reaches this limit, the job is terminated and fails to complete.
The number of concurrent jobs you can run across all repositories in your account depends on your GitHub plan. If exceeded, any additional jobs are queued.
You can execute up to 1000 API requests in an hour across all actions within a repository. This limit also applies to self-hosted runners. If exceeded, additional API calls will fail, which might cause jobs to fail.
In addition to these limits, GitHub Actions should not be used for:
Content or activity that is illegal or otherwise prohibited by our Terms of Service or Community Guidelines.
Cryptomining
Serverless computing
Activity that compromises GitHub users or GitHub services.
Any other activity unrelated to the production, testing, deployment, or publication of the software project associated with the repository where GitHub Actions are used. In other words, be cool, don’t use GitHub Actions in ways you know you shouldn’t.
You can execute up to 1000 API requests in an hour across all actions within a repository. This limit also applies to self-hosted runners. If exceeded, additional API calls will fail, which might cause jobs to fail.
| GitHub plan | Total concurrent jobs | Maximum concurrent macOS jobs |
|---|---|---|
| Free | 20 | 5 |
| Pro | 40 | 5 |
| Team | 60 | 5 |
| Enterprise | 180 | 15 |
Self-hosted runners versus github hosted runners
Self-hosted runners can be physical, virtual, container, on-premises, or in a cloud. You can use any machine as a self-hosted runner as long at it meets these requirements:
- You can install and run the GitHub Actions runner application on the machine. For more information, see “Supported operating systems for self-hosted runners.”
- The machine can communicate with GitHub Actions. For more information, see “Communication between self-hosted runners and GitHub.”
GitHub-hosted runners offer a quicker, simpler way to run your workflows, while self-hosted runners are a highly configurable way to run workflows in your own custom environment.
GitHub-hosted runners:
- Are automatically updated.
- Are managed and maintained by GitHub.
- Provide a clean instance for every job execution.
Self-hosted runners:
- Can use cloud services or local machines that you already pay for.
- Are customizable to your hardware, operating system, software, and security requirements.
- Don’t need to have a clean instance for every job execution.
- Depending on your usage, can be more cost-effective than GitHub-hosted runners.
Notes on setting up :Using an .env file
If setting environment variables is not practical, you can set the proxy configuration variables in a file named .env in the self-hosted runner application directory. For example, this might be necessary if you want to configure the runner application as a service under a system account. When the runner application starts, it reads the variables set in .env for the proxy configuration.
An example .env proxy configuration is shown below:
https_proxy=http://proxy.local:8080no_proxy=example.com,myserver.local:443
Self-hosted runner security : With respect to public repos - essentially, this means that some repo of code on github is able to run on your computer. Therefore unless the code is trusted and vetted, it is dangerous to allow this. Forks can cause malicious workflows to run by opening a pull request.
It is safer to use public repositories with a github hosted runner.
We recommend that you do not use self-hosted runners with public repositories.
Forks of your public repository can potentially run dangerous code on your self-hosted runner machine by creating a pull request that executes the code in a workflow.
This is not an issue with GitHub-hosted runners because each GitHub-hosted runner is always a clean isolated virtual machine, and it is destroyed at the end of the job execution.
Untrusted workflows running on your self-hosted runner poses significant security risks for your machine and network environment, especially if your machine persists its environment between jobs. Some of the risks include:
- Malicious programs running on the machine.
- Escaping the machine’s runner sandbox.
- Exposing access to the machine’s network environment.
- Persisting unwanted or dangerous data on the machine.
CI
Continuous Integration: enables commits to trigger builds and thereby enhances error discovery and rectification process.
The CI server can run on the same server as the runner. Therefore it can be github hosted or a self-hosted CI server.
Github analyses a repository when CI is setup and recommends basic templates depending on the language used.
When you commit code to your repository, you can continuously build and test the code to make sure that the commit doesn’t introduce errors. Your tests can include code linters (which check style formatting), security checks, code coverage, functional tests, and other custom checks.
Building and testing your code requires a server. You can build and test updates locally before pushing code to a repository, or you can use a CI server that checks for new code commits in a repository.
You can configure your CI workflow to run when a GitHub event occurs (for example, when new code is pushed to your repository), on a set schedule, or when an external event occurs using the repository dispatch webhook.

Top comments (0)