Choosing the right database for analytics is hard. With many options available, each is optimized for different use cases.
Some databases are built for real-time analytics in customer-facing applications, where low-latency queries and high-ingest performance are essential. Others are designed for internal BI and reporting and optimized for large-scale aggregations and batch processing. Some databases are general-purpose, handling both transactions and analytics, while others specialize in analytical workloads.
Benchmarks can help—but only if they reflect your actual workload.
Several benchmarks, such as ClickBench, TPC-H, and TPC-DS, evaluate the performance of databases for analytics. However, they are not representative of real-time analytics.
To fill this gap, we’ve created RTABench, a new benchmark to assist developers in evaluating the performance of different databases in real-time analytics scenarios.
Key patterns in real-time analytics include:
Multi-table Joins: Quickly combining data from several tables.
Selective Filtering: Fast lookups for the most recent and specific data.
Pre-aggregated Results: Using pre-calculated materialized views for prompt responses.
While denormalizing data can speed up queries, it complicates management and raises costs. Real-time applications favor normalized schemas and joining data at query time.
Introducing RTABench
To meet the need for real-time analytics workloads, we developed RTABench, a benchmark designed to test databases with these specific requirements. RTABench focuses on essential query patterns such as joins, filtering, and pre-aggregations.
How RTABench Works
RTABench models an order tracking system with normalized tables to mimic real-time analytics applications. It uses around 171 million order records and evaluates databases with 40 different queries, including basic counts, selective filtering, multi-table joins, and pre-aggregated queries.
RTABench categorizes databases into:
General-purpose databases: e.g., PostgreSQL and MySQL.
Real-time analytics databases: Optimized for quick insights, often secondary databases.
Batch analytics databases: Primarily for historical data and excluded from real-time benchmarks.
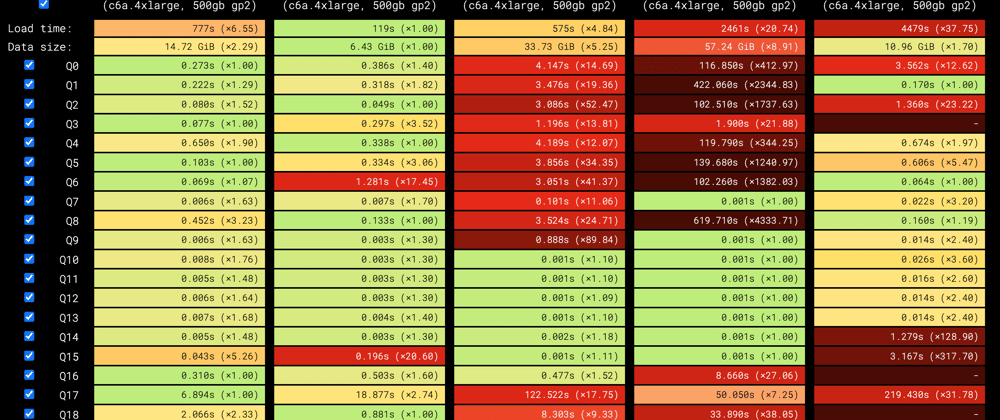
Benchmark Results: What We Learned
RTABench results are published at rtabench.com. While performance varies based on workload characteristics, this benchmark reveals some interesting insights:
General-purpose databases perform better on RTABench than on ClickBench. That’s expected—RTABench uses a normalized schema similar to real applications, while ClickBench is based on a denormalized dataset optimized for batch analytics.
TimescaleDB is 1.9x faster than ClickHouse on RTABench, even though it’s 6.8x slower on ClickBench. This is likely because TimescaleDB is optimized for real-time analytics applications, which often rely on normalized schemas and selective aggregations, while ClickHouse shines in denormalized, columnar analytics with large-scale aggregations.
Incremental materialized views offer massive speedups. They deliver up to hundreds or even thousands of times faster performance than querying the raw data (from seconds to a few milliseconds), demonstrating their value for real-time analytics. However, among the databases tested, only ClickHouse and TimescaleDB support them.
ClickHouse is the leader in data loading and storage efficiency. It’s 4.8x faster at loading data and uses 1.7x less disk than the next best database.
PostgreSQL was the fastest general-purpose database. The most popular database among developers demonstrates its versatility. With indexing, it’s only 4.1x slower than TimescaleDB on raw queries—but it can’t match the performance of incremental materialized views, which PostgreSQL doesn’t support.
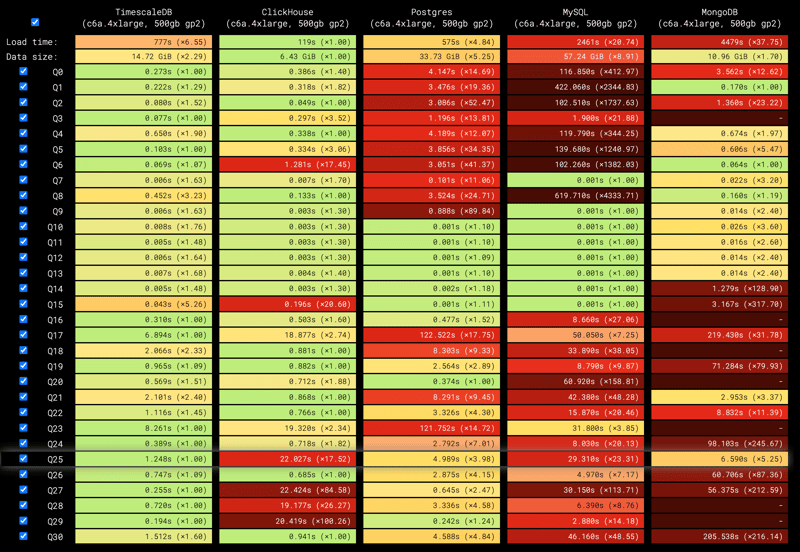
Check out the full results here.
Community contributions to RTABench are encouraged! Whether it's adding new databases, improving existing queries, or making configuration tweaks, we hope you’ll contribute to the repo. All tools, datasets, and results are available on GitHub, with the latest version here.

Top comments (5)
A small warning: if you are comparing databases without being already an experts in those then you are probably doing it wrong.
Analytics? Learn RDBMS and ACID. Learn NOSQL and CAP. Learn hadoopfs, cockroach, spark, redis and rocksdb. Play with omega and F1 if you are lucky, for most you stick with good "old" kubernetes and TiDB.
Not sure I completely agree there, but I do think you should play to your strengths. If you're a SQL|NoSQL person go for a SQL|NoSQL database unless it specifically can't do something you need. Don't add new databases just for fun 😅
I mentioned NewSQL (F1, TiDB). I mentioned also NOSQL which stands for not only sql. You probably meant "anythings that is not structured query language". I worked with many databases where size varies between gigabyte and sizes given as just an exponent scale (you rarely call anything over terabytes with name and petabytes are at the border of calling them with a name).
MySQL is a database with many cool features but also an interface. Same for postgresql. Look at yugabyte. Search for scalable attempts to make Mysql or postgres. Play with elastic and mongo. Then look at cassandra which claims to be full CAP. After all the steps you might be closer to understand why your view might be wrong.
What I meant is that you compared a racing car and a truck. Since the truck was too slow and racing car cannot handle large load while both consuming a lot of fuel, you decided that that it is the best to transport goods on your legs. The truth is that each option has its use cases. To know which, when and why you need a crazy amount of knowledge. LLM is a good tool here - describe your use case without pointing to a database and it would point right database for you. It you talk about data tables - you might get a RDBMS. Unfortunately your view perspective will push some options. If you are able to step away from any database related terminology and give an abstract requirement to AI then it might guide you to the right option.
I worked in a place where someone tested many databases with a test scenario that fits simple single instance RDBMS with no data store guarantee. It was then enforced to use some database for everything. But it failed when number of users have grown over 10000, when first production crash happened, when performance dropped down, memory usage went out of control and access control became and issue - that database had no such features but had met other criteria. Just like a CSV file can handle fast write and sequential read - your decision might be to use CSV for everything. Until you learn about data indexing. Or you learn about apache parquet for analytics with plain file storage on the cloud. There are simply too many nuances. Beware. And I wish you good luck there.
This sounds cool 🔥 Wish you good luck for this! Interested to see how this turns out ✨️
Nice