
Photo by Miika Laaksonen on Unsplash
What is Manga ?
Manga (漫画, manga) are comics or graphic novels created in Japan or using the Japanese language and conforming to a style developed in Japan in the late 19th century. They have a long and complex pre-history in earlier Japanese art.
let’s say manga is Japanese comics which are more popular and interesting than most of the main stream comics.
Scouting
Let’s learn some WebScraping and get some value instead of just getting data, let us download some manga from internet and try to read it.
Reading manga online is easy, you just go to some site like mangapanda.com search some comics and read it. what if you want to download the entire comic compress each chapter to a particular volume and read it offline.
when we go to mangapanda.com and search for a particular comic like say naruto here’s what the URL we are directed to

Notice the naruto at the end of the URL, now if we go to the first chapter of naruto the URL transforms to http://www.mangapanda.com/naruto/1 that’s just great for us. Note that this doesn’t happen with all the manga sites out there and watch out for that before trying to scrape any other manga site. we are trying to download the images that exists in naruto chapter 1
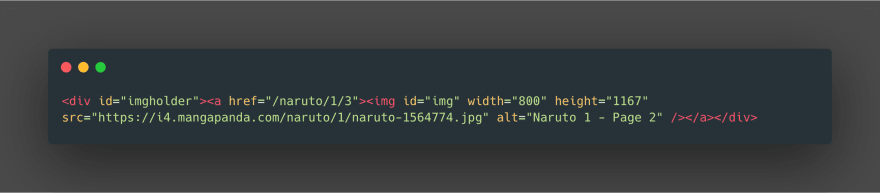
Let’s write a small function to get the image from the URL
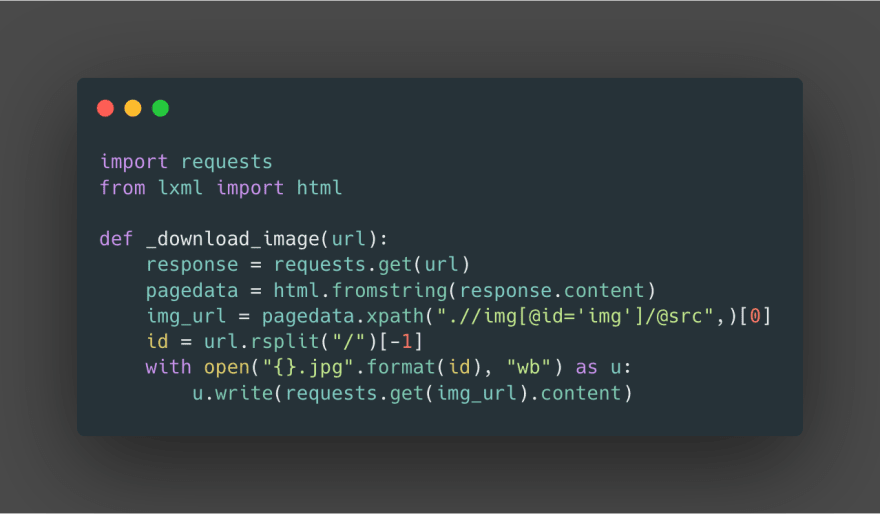
OK, what is happening here. for the _download_image we are giving URL say mangapanda.com/naruto/1/3 according to our observation we are downloading naruto’s chapter 1 image 3 . let’s breakdown the function and understand what’s going on for each line.
requests.get download the source of the given URL
convert the source code html document into lxml html tree this helps us to parse tags easily
-
get the tags with img with id=’img’ the expression, ensures that.
".//img[@id ='img']/@src"
after we get the image URL download the image with requests.get(URL).content
Downloading the entire chapter
It’s good that the chapters are in the format /chapter/page_number so how can we download all the images of a particular chapter if we don’t know the ending chapter number. if we know the ending chapter then we can simply using range and loop over the image number to download.
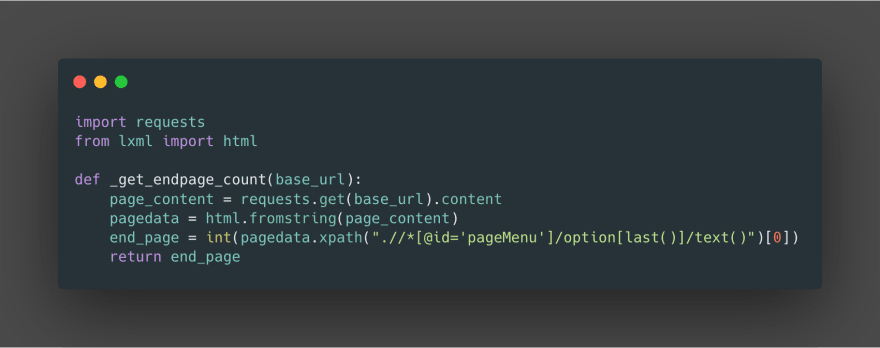
if we see the source code there is this interesting tag.

There wrote this so that users can select the page number in the form of a dropdown. we can use the lxml format tree for this .//*[@id =’pageMenu’]/option[last()]/text() and get the last occurence of the pageMenu id which is the end page of the chapter.
let’s write wrap this up in a small function
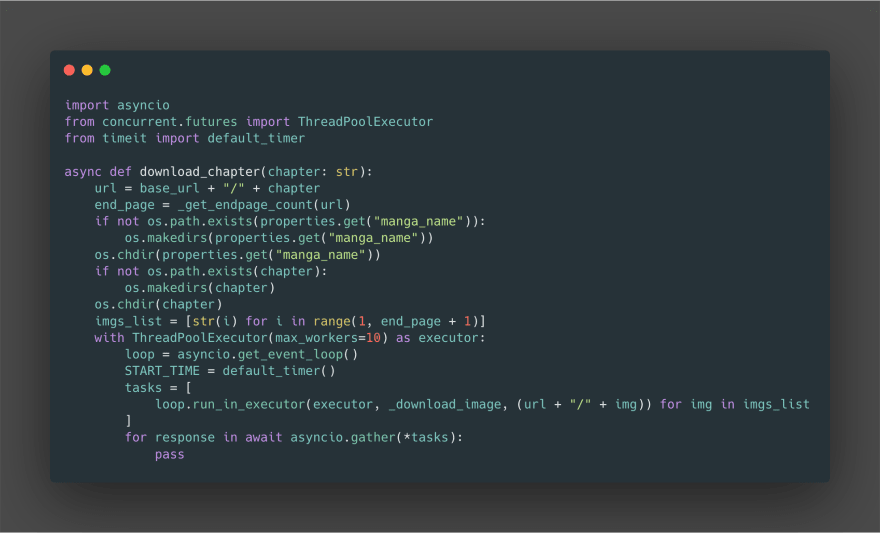
now, we know the page numbers of the chapters we are going to download. we can just get all the images from the chapter in parallel, sort them and then compress them to make a single volume.
let’s use ThreadPoolExecutor and write an async function for the following job.
properties = json.load(open("configs.json"))
base_url = properties.get("base_url") + "/" + properties.get("manga_name")
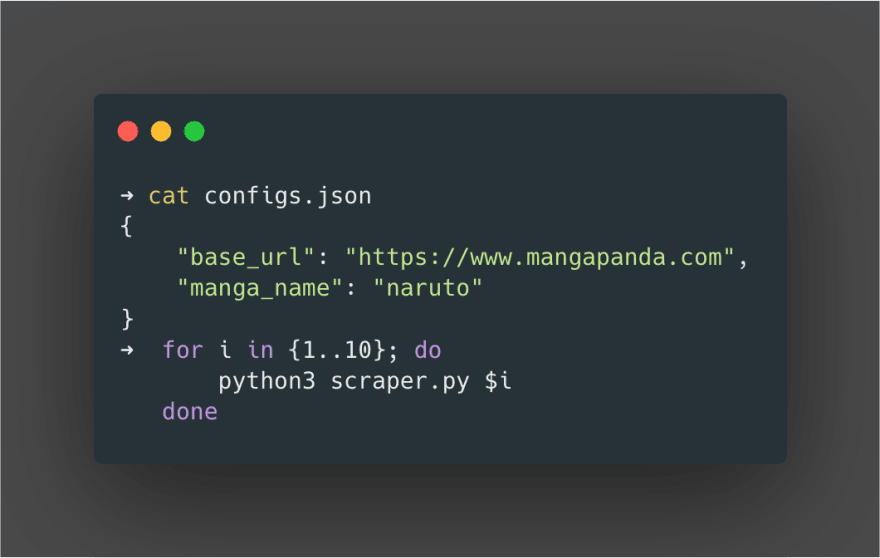
we can define manga_name and base_url in configs.json so that we don’t have to give name of the manga every time we download a chapter.
download_chapter function creates directories based on the manga_name and chapter number
➜ naruto git:(master) ✗ tree
.
└── 1
├── 1.jpg
├── 10.jpg
├── 11.jpg
Now that we’ve downloaded all the pages in the chapter. let’s compress it in CBZ format and ensure that the order of the page numbers is sorted properly
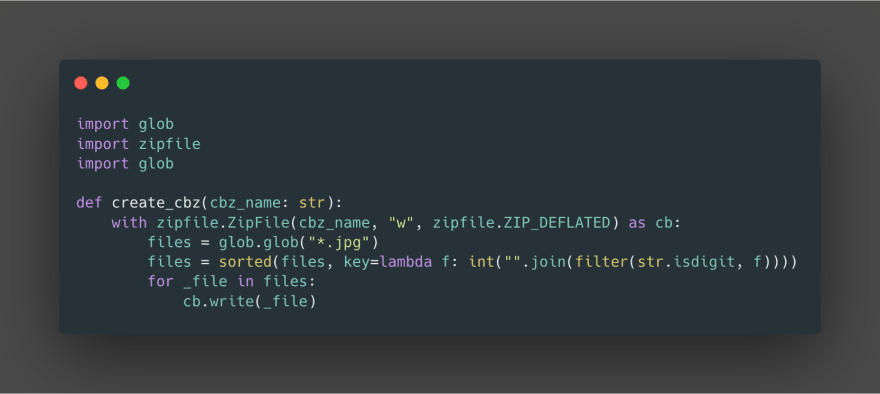
we can wrap everything up with a classic main so that if we give chapter number we will download the entire comic

In action
we can run the script in the following way
Disclaimer: this is for pure educational purpose only. Do not use this commercially for piracy or for attacking mangapanda.com

Top comments (3)
Interesting... You are simply scraping images from the manga aggregator sites. I wonder if the same method could possibly be applied to manhua & manhwa
I guess we could, it really depends on the site, if it just uses simple img type of storage, then we can.
some sites just use php rendering or something weird.. then the scraping the images from it will be different
Some comments may only be visible to logged-in visitors. Sign in to view all comments.