Basic Hash Maps
Now that we have all of the main ingredients for a hash map, let’s put them all together. First, we need some sort of associated data that we’re hoping to preserve. Second, we need an array of a fixed size to insert our data into. Lastly, we need a hash function that translates the keys of our array into indexes into the array. The storage location at the index given by a hash is called the hash bucket.
Let’s use the following example for our hash map:
| Key: Album Name | Value: Release Year |
|---|---|
| People’s Instinctive Travels and the Paths of Rhythm | 1990 |
| The Low End Theory | 1991 |
| Midnight Marauders | 1993 |
| Beats, Rhymes and Life | 1996 |
Our map here relates the first four A Tribe Called Quest studio albums with the year they were produced in. We’ll need an array of at least size 4 to contain all of these elements. And a way to turn each album name into an index into that array.
For each album name, find that album’s hash by performing the following calculation:
hash value = ((number of 'a's in album title) + (number of 'e's in album title))
And then take that hash and calculate an array index by performing hash value mod 4. Following these steps we get the following schema:
| Key: Album Name | Hash | Hash Mod | Value: Release Year |
|---|---|---|---|
| People’s Instinctive Travels and the Paths of Rhythm | 8 | 0 | 1990 |
| The Low End Theory | 2 | 2 | 1991 |
| Midnight Marauders | 3 | 3 | 1993 |
| Beats, Rhymes and Life | 5 | 1 | 1996 |
First the key is translated into the hash via our hashing function. Then our hash map performs modulo arithmetic to turn the hash into an array index.
Collisions
Remember hash functions are designed to compress data from a large number of possible keys to a much smaller range. Because of this compression, it’s likely that our hash function might produce the same hash for two different keys. This is known as a hash collision. There are several strategies for resolving hash collisions.
The first strategy we’re going to learn about is called separate chaining. The separate chaining strategy avoids collisions by updating the underlying data structure. Instead of an array of values that are mapped to by hashes, it could be an array of linked lists!
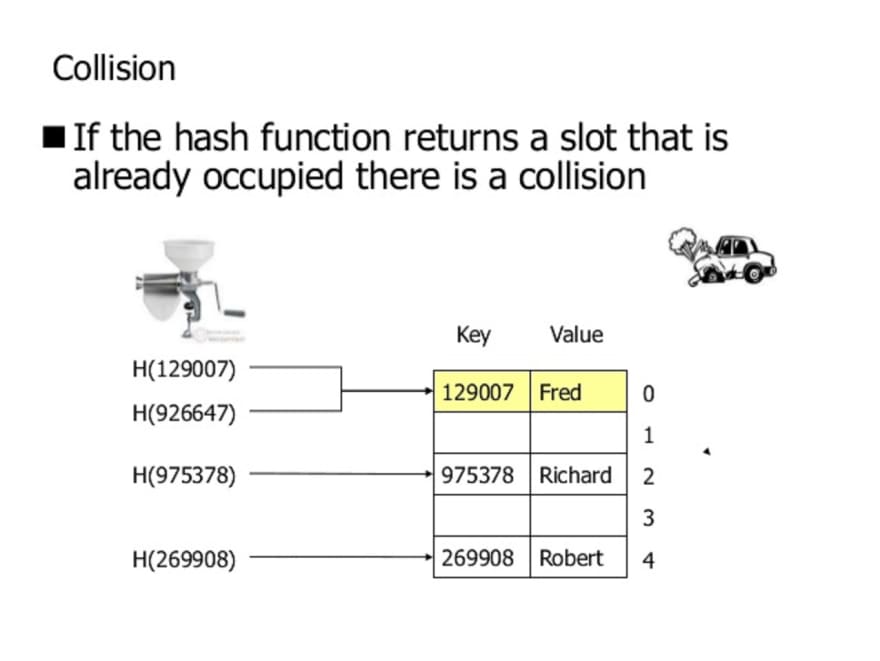
Image credits to javarevisited
Separate Chaining
A hash map with a linked list separate chaining strategy follows a similar flow to the hash maps that have been described so far. The user wants to assign a value to a key in the map. The hash map takes the key and transforms it into a hash code. The hash code is then converted into an index to an array using the modulus operation. If the value of the array at the hash function’s returned index is empty, a new linked list is created with the value as the first element of the linked list. If a linked list already exists at the address, append the value to the linked list given.
This is effective for hash functions that are particularly good at giving unique indices, so the linked lists never get very long. But in the worst-case scenario, where the hash function gives all keys the same index, lookup performance is only as good as it would be on a linked list. Hash maps are frequently employed because looking up a value (for a given key) is quick. Looking up a value in a linked list is much slower than a perfect, collision-free hash map of the same size. A hash map that uses separate chaining with linked lists but experiences frequent collisions loses one of its most essential features.
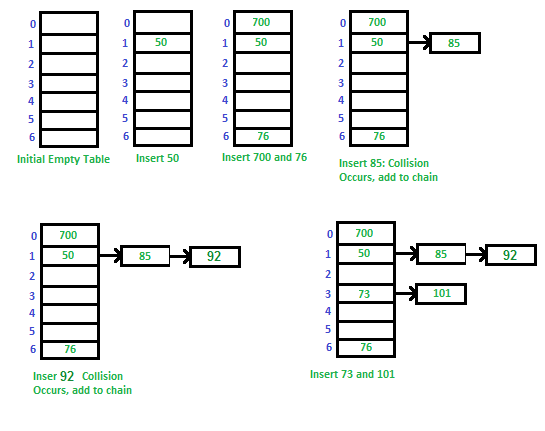
Image credits to geeksforgeeks
Saving Keys
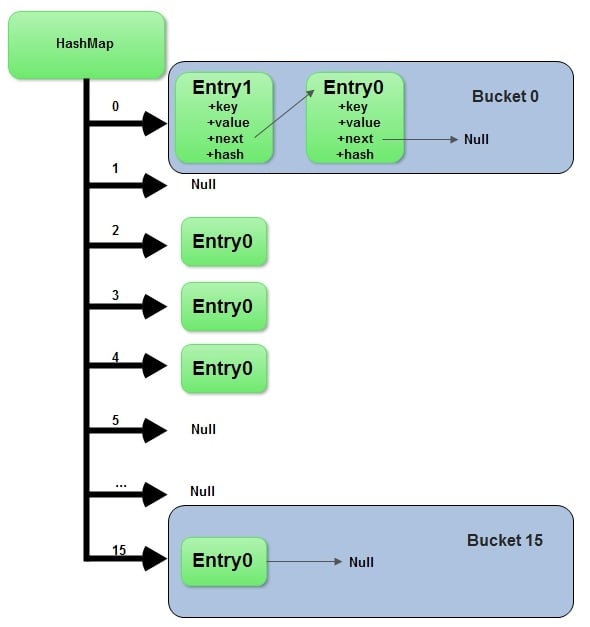
A hash collision resolution strategy like separate chaining involves assigning two keys with the same hash to different parts of the underlying data structure. How do we know which values relate back to which keys? If the linked list at the array index given by the hash has multiple elements, they would be indistinguishable to someone with just the key.
If we save both the key and the value, then we will be able to check against the saved key when we’re accessing data in a hash map. By saving the key with the value, we can avoid situations in which two keys have the same hash code where we might not be able to distinguish which value goes with a given key.
Now, when we go to read or write a value for a key we do the following: calculate the hash for the key, find the appropriate index for that hash, and begin iterating through our linked list. For each element, if the saved key is the same as our key, return the value. Otherwise, continue iterating through the list comparing the keys saved in that list with our key.

Top comments (0)