The Problem
At my current company, we have a lot of services:
- An Oracle database
- A Postgres database
- A PIM system
- Salesforce
- APIs to access these data sources
- Caching services
Our development and infrastructure teams are quite small, and this is becoming a lot to manage. Not only that, but it is increasingly difficult to onboard new team members because they have to be familiar with all our data sources and APIs before they can start building a front
end application.
I believe that implementing a new GraphQL service between our front and back ends will improve developer experience on the front end and maintainability on the back end. The purpose of this post is not to explain what GraphQL is, so I will assume you are already familiar with it. Rather, I want to explain why I think GraphQL is a good solution to the problem we have and I want to address some of the concerns my colleagues have brought up about using GraphQL.
Current Architecture
Currently, our architecture looks something like this
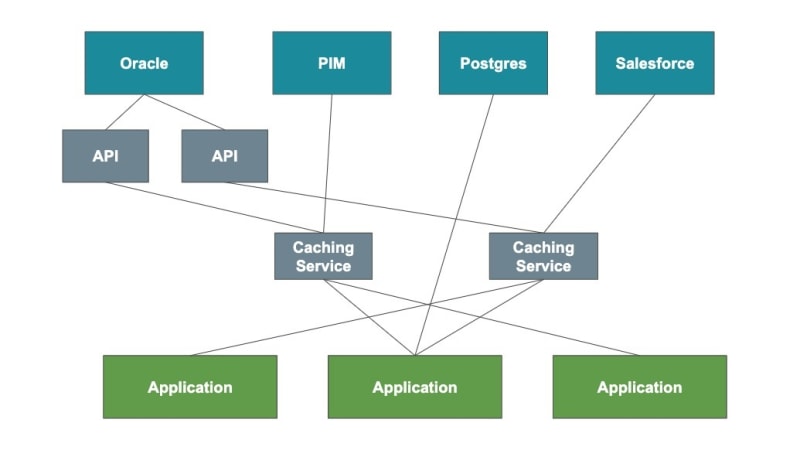
This picture is a simplification, but I think it accurately sums up how things are generally structured. We have all our data sources in one layer. Then we have APIs to access those data sources. Then we have some caching services. Finally we get to our front end applications, which use a combination of APIs, caching services, and data sources to get what they need.
This works, and one of the biggest benefits to doing things like this is that there is no single point of failure. If the Postgres database goes down, applications that don't depend on it can still run just fine. Of course, some services (like the Oracle database) have a lot of unavoidable dependencies,
but even if it goes down, some applications will still run just fine.
The problem with this architecture is... well, it's messy. And it's hard to understand. And it's even harder to get new employees to understand it. And each application has to know how every data store/service that it uses works. On top of that, each application needs to figure out how to combine the various data sources into a usable format for its specific use case.
Doing things like this is fine for a small shop, which my company is. But we have grown a lot recently, both in the number of developers we have and the number of services we need to support. As the number of services grows, so does the difficulty of remembering what every service is for and how to use them on the front end. And if it's difficult for us to remember what everything does, I imagine it will be more difficult for any new developer we might hire. I just don't see this scaling well in the long run.
Proposed Solution
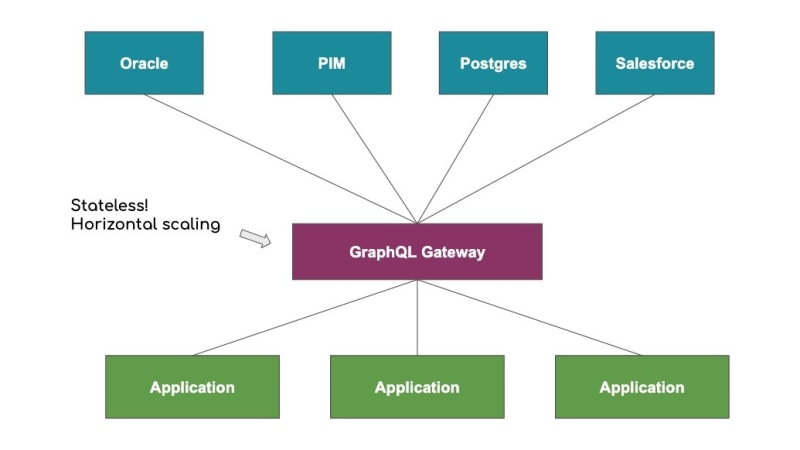
The architecture I'm proposing looks like this

One benefit of this architecture is immediately obvious: it's a whole lot simpler. It's obvious where to go to get data. This improves developer experience on the front end because now you only need to know about one back end service: GraphQL. Once you learn GraphQL, you can immediately bring data into the user interface from anywhere. And since GraphQL is self-documenting, your front end devs are guaranteed to have good documentation about your data. That means much less time is needed for your front end developers to become productive.
Developer experience for back end teams also improves with this architecture. Instead of managing several endpoints to their data, each tailored to fit a particular client's need, they just have to make sure the data gets to the GraphQL gateway.
GraphQL also provides a common language between front and back end teams: the language of the GraphQL schema. And since the schema is an abstract layer between the data and the front end, the schema types can be named using any convention we want. Typically, we name types after the language of the business users, which puts the focus back on the user and allows everyone to provide a better user experience.
The result of this architecture is greater cohesion and efficiency among all parties involved.
Concern #1 - Single Point of Failure
One concern people have with this architecture is that the GraphQL gateway looks like a single point of failure. Everything depends on it, so if it goes down, then everything breaks.
Except not exactly. The GraphQL gateway is completely stateless, meaning it doesn't store any data itself (except, perhaps, caching). It only communicates with external data sources. Once a request is finished processing, the GraphQL server forgets everything about it. Because of this stateless nature, the GraphQL gateway can actually live on several servers behind some load balancers. Now if one of the gateway instances goes down, the request can still be sent to one of the other instances.
Concern #2 - Creating a Monolith
Okay, so even if the GraphQL gateway isn't a single point of failure, it's still this giant monolith that needs to know everything about every data source. Won't that get confusing for back end developers?
This is a pretty big concern. How do we provide this nice GraphQL interface to our front end applications while maintaining modularity on the back end? The answer is federation.
Federation
Federation is the idea that we build several GraphQL services independently of one another, then stitch together the schemas into a single GraphQL gateway. This way, we can maintain our GraphQL schema as a set of separate services on the back end, and the front end will be none the wiser.
What's more, different services can implement their own part of the data graph in whatever way they want. If one of our teams wants to build their GraphQL service in Python and another team wants to use JavaScript, we can do that.
Apollo Server is a great JavaScript library for building a federated GraphQL server. Apollo has been making tools for GraphQL pretty much since GraphQL was created, and you can read more about implementing federation with Apollo here.
And since I mentioned Python, graphene is a great library for building a GraphQL server in Python, and graphene-federation provides a quick and easy way to implement the federation specification.
Concern #3 - Controlling Access
One final concern people have has to do with access control. Of course, it would be pretty silly to expose everything about your data and let anyone have access to it. Thankfully, GraphQL lets you control access in a granular and flexible way.
There are several ways to implement authentication and authorization, but the basic idea is that the user would need to send an access token (usually a JWT) to the GraphQL gateway. The gateway would then validate the JWT and pass the JWT payload to the data graph through the context. The payload would contain information about which user this is and what their permissions are. Since the context object is passed to every resolver, each resolver can check if the user has permission to access that field. If not, it can simply return null.
When using federation, some extra steps need to be taken to make sure that the user info is passed to each implementing service. You can read more about how to do this with Apollo Server here.
Conclusion
GraphQL is a great tool for hiding the complexity of your back end from your front end and promoting cohesion and efficiency throughout the company. Though there may be some concerns, I think they can be resolved in a secure and scalable way. Implementing a company-wide data graph would be a great solution for us as we continue to grow, and I highly recommend it to anyone else who is in a similar situation.
Be sure to share or leave a comment if you liked the post! I'll keep you updated on how this goes for us if/when we implement it.

Top comments (0)