When you’re starting out doing ETL jobs on AWS Glue, there’s always a combo to refer to, which is the AWS Dynamo.
Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability.
It also helps you to lessen the load on managing tedious parts for operation and the scalability of your databases.
It already provided that by giving you everything at once, including hardware provisioning, setup and configuration, replication, software patching, and cluster scaling.
Another fact about it is that whenever you use DynamoDB, it sets up the environment for your tables for storage and retrieval, which is usually difficult when there’s a large amount of data and traffic.
As for choosing to scale down or scale up in terms of capacity, when’s a possible situation that is likely needed to? You can always set up and refer to the cost subjected to these changes.
DynamoDB provides on-demand backup capability. It allows you to create full backups of your tables for long-term retention and archival for regulatory compliance needs.
In this article, we mainly focus on a few things. The first is to explore around the DynamoDB, then store our data in the AWS S3 and run your ETL workloads on AWS Glue seamlessly and efficiently.
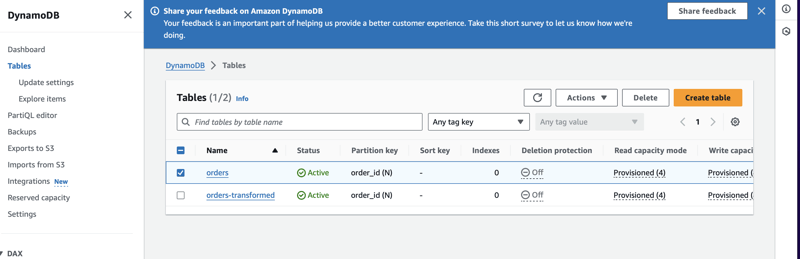
In this part right here, once you’ve already set up your tables on the database [DynamoDB] you can then choose the specific names of the tables and explore each of these based on your preference.
Make sure to also set up the IAM role if there is needed to so just in case you encounter some issues on enabling this on your end.
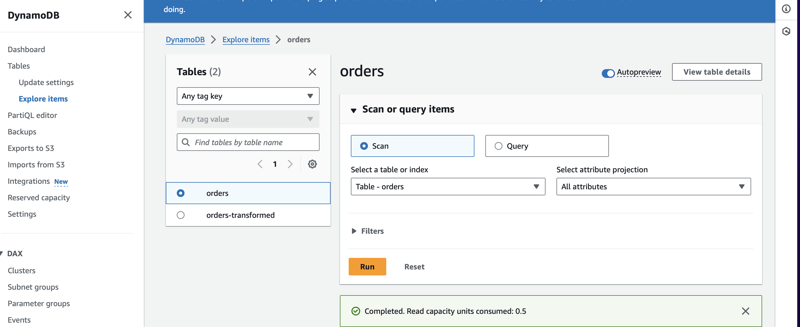
Upon clicking any of the tables, you will then be able to also add your queries and see the rows and columns and values within the table
It’s either you scan or query, which then is helpful to check the attributes and get the gist of the data you’ll be doing for ETL.
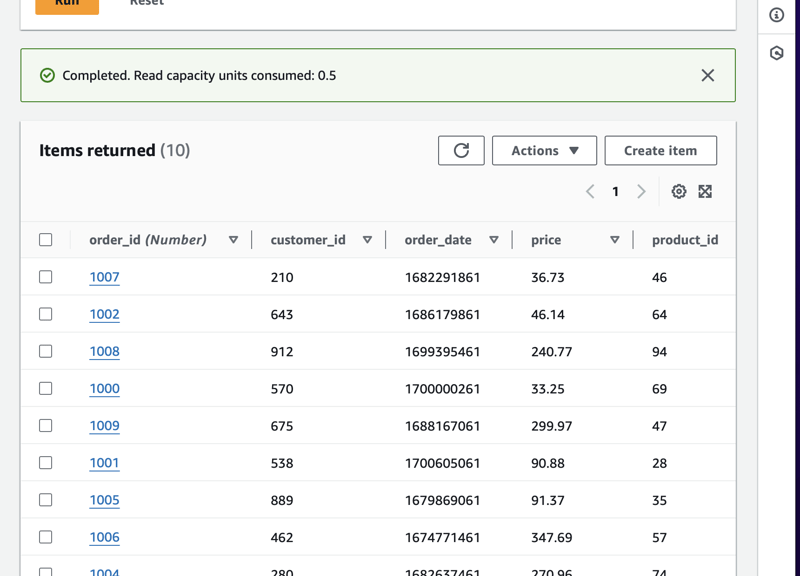
Since we can now see the items from the chosen tables. We can now go to the Amazon S3 to check our buckets and perhaps do some ways to validate and check if the file uploaded is in JSON format.
Note that the goal on this one is to make sure that once we’ve done ETL we then explore the preparation of the data for analytics and usage.
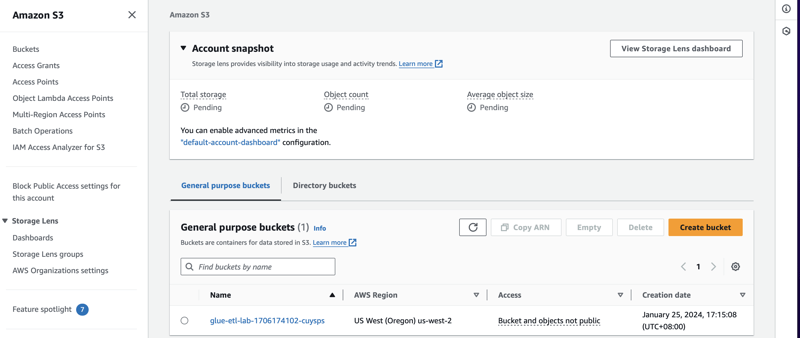
From here, we can see our buckets set up and also the AWS Region is mentioned specifically on US West (Oregon) us-west-2. This is commonly used for provision access and a good way to start on AWS Console.
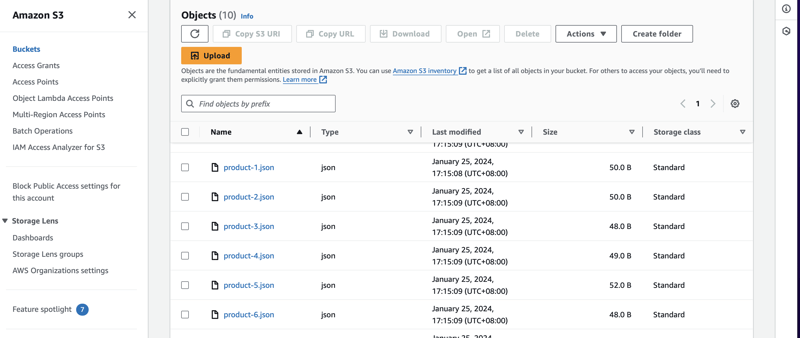
Now we can see that our data format is in JSON files. Ready for the AWS Glue to do the ETL and run some jobs for processing.
From here, we already prepared the setup for this, the next is run now the ETL Jobs which will then be shown on the next article.
You’ll see when setting up the DynamoDB and AWS S3.
The following tutorials present complete end-to-end procedures to familiarize yourself with DynamoDB.
These tutorials can be completed with the free tier of AWS and will give you practical experience using DynamoDB.





Top comments (0)